Addition Link
Introduction
- ResNets [11] and Highway Networks [33] by-pass signal from one layer to the next via identity connec-tions.
- Stochastic depth [13] shortens ResNets by randomly dropping layers during training to allow better information and gradient flow.
- FractalNets [17] repeatedly combine several parallel layer sequences with different number of convolutional blocks to obtain a large nominal depth, while maintaining many short paths in the network.
ResNet and Highway Networks
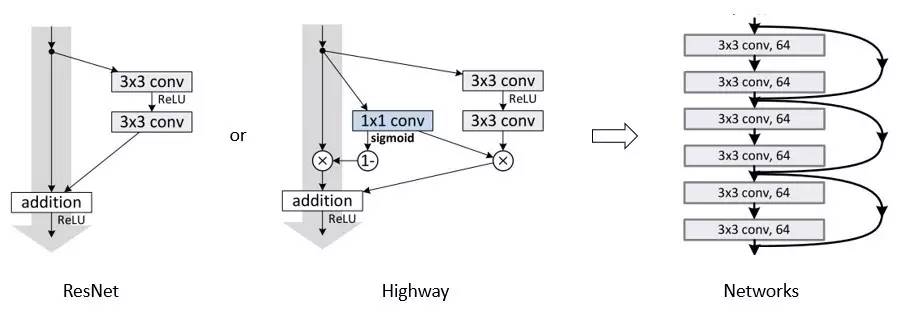
Stochastic Depth
Recent variations of ResNets [13] show that many layers contribute very little and can in fact be randomly dropped during training.

FractalNets

AdaNet
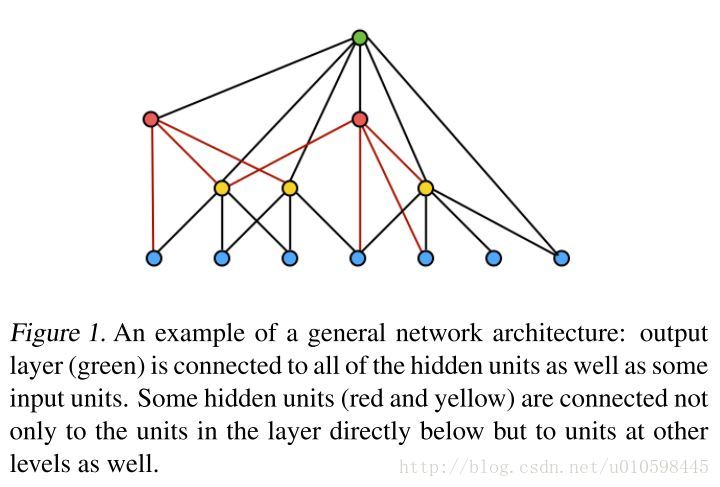
Parallel to our work, [1] derived a purely theoretical framework for networks with cross-layer connections similar to ours.
Change
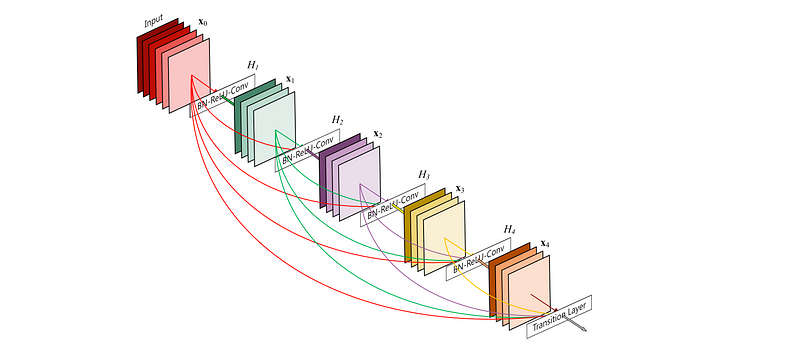
- we connect all layers (with matching feature-map sizes)
- in contrast to ResNets, we never combine features through summation before they are passed into a layer; in- stead, we combine features by concatenating them.
- narrow layers (eg: 12 filters per layer)
Advantage
- Similar to recurrent neural networks[21], it requires fewer parameters than traditional convolutional networks, as there is no need to re-learn redundant feature-maps.
- Implicit deep supervision[20], Improved flow of information and gradients, which make network easy to train. Further, dense connections have a regularizing effect.
Result
- Our models tend to require much fewer parameters than existing algorithms with comparable accuracy.
- Further, we significantly outperform the current state-of- the-art results on most of the benchmark tasks.
Reference
[1] C. Cortes, X. Gonzalvo, V. Kuznetsov, M. Mohri, and S. Yang. Adanet: Adaptive structural learning of artificial neural networks. arXiv preprint arXiv:1607.01097, 2016. 2[1] C. Cortes, X. Gonzalvo, V. Kuznetsov, M. Mohri, and S. Yang. Adanet: Adaptive structural learning of artificial neural networks. arXiv preprint arXiv:1607.01097, 2016. 2
[11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 1, 2, 3, 4, 5, 6
[12] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016. 2, 3, 5, 7
[13] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger. Deep networks with stochastic depth. In ECCV, 2016. 1, 2, 5, 8
[17] G. Larsson, M. Maire, and G. Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. arXiv preprint arXiv:1605.07648, 2016. 1, 3, 5, 6
[20] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeply- supervised nets. In AISTATS, 2015. 2, 3, 5, 7
[21] Q. Liao and T. Poggio. Bridging the gaps between residual learning, recurrent neural networks and visual cortex. arXiv preprint arXiv:1604.03640, 2016. 2
[33] R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. In NIPS, 2015. 1, 2, 5