ASPP全称:Atrous Spatial Pyramid Pooling,中文可以理解为空洞空间卷积池化金字塔或者多孔空间金字塔池化。在这其中,要理解两个概念:一个是SPP,池化金字塔结构或者叫空间金字塔池化层,都是一个东西;另一个是Atrous,空洞卷积,两个概念加在一起产生了ASPP。
首先说一下SPP:Spatial Pyramid Pooling。这个结构出自于论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,原文连接:https://arxiv.org/pdf/1406.4729.pdf
一、SPP
1.问题的产生
这里问了让逻辑更通顺,多讲一些,大佬们请跳到2
通常在神经网络的训练过程中,我们都需要保证数据集图片大小的一致性,可这是为什么呢?我们知道一个神经网络通常包含三个部分:卷积、池化、全连接。
假设给定一个30*30大小的输入图片,通过一个3*3的卷积核得到大小为29*29的输出和给定一个40*40大小的输入图片,得到大小为39*39的输出之间有区别吗?其实是没有区别的,因为在这里我们要训练的是卷积核的参数,与输入的图片大小无关。
再来看池化层,池化层其实可以理解成一个压缩的过程,无论是AVE还是MAX其实也输入都没啥关系,输出大小直接变为输出一半就完了(参数为2)。
所以问题出现在全连接层上,假设同一个池化层的输出分别是32*32*1和64*64*1,这就出问题了,因为全连接层的权重矩阵W是一个固定值,池化层的不同尺寸的输出会导致全连接层无法进行训练。
针对这个问题,原有的解决思路是通过拉伸或者裁剪去统一图片的尺寸,但是会造成信息丢失,失真等等众多问题。

图1.图片变换后失去了原有的样子
所以大佬们就想了个办法,将原有的神经网络处理流程从图2改变为了图3,提出了SPP结构,也就是池化金字塔,利用多尺度解决这个问题。
![]()
图2.原有神经网络处理流程
![]()
图3.带有SPP结构的神经网络处理流程
2.解决方案-SPP
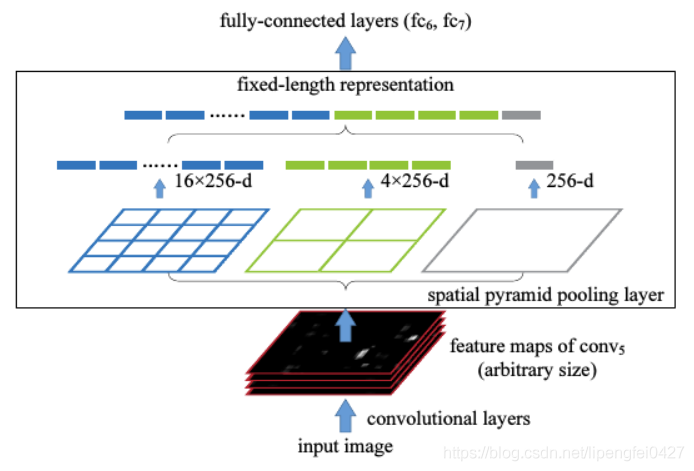
图4.SPP模块示意图
SPP的思想就是利用多个不同尺度的池化层进行特征的提取,融合成一个21维的向量输入至全连接层。
如图4所示,从下往上看,输入图片的大小可以是任意的,经过卷积层卷积之后获取特征图的channels数量为256,将其输入到SPP结构中。图中从左往右看,分别将特征图分成了16个格子,4个格子和1个格子。
假设特征图大小是:width*height,这里蓝色格子的大小就是width/4*height/4,绿色格子的大小就是width/2*height/2,灰色格子的大小就是width*height。对每个格子分别进行池化,一般是采用MAX pooling,这样子我们分别可以得到16*256、4*256、1*256的向量,将其叠加就是21维向量,这样子就保证了无论输入图片尺寸是多少,最终经过SPP输出的尺度都是一致的,也就可以顺利地输入到全连接层。
这就是SPP层的处理过程,思路和结构都很巧妙。
二、空洞卷积
再一个就是空洞卷积,这里直接丢个连接:https://blog.csdn.net/lipengfei0427/article/details/108968914
三、ASPP
ASPP一开始在DeepLabv2中提出,DeepLab系列也是语义分割效果很棒的一个系列,丢个原文链接:https://arxiv.org/pdf/1606.00915.pdf
其实在理解了SPP模块和空洞卷积之后再来看ASPP就十分简单了。
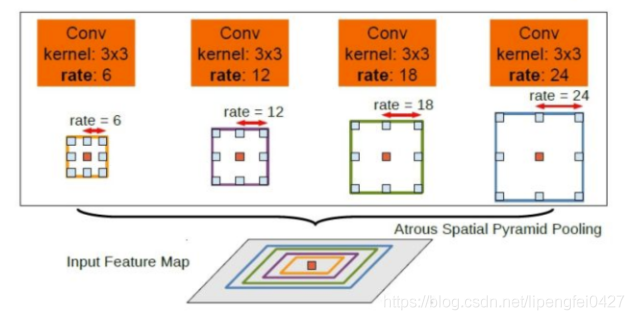
图5.ASPP模块示意图
图5就是ASPP模块示意,对于给定的输入以不同采样率的空洞卷积并行采样,将得到的结果concat到一起,扩大通道数,然后再通过1*1的卷积将通道数降低到预期的数值。相当于以多个比例捕捉图像的上下文。
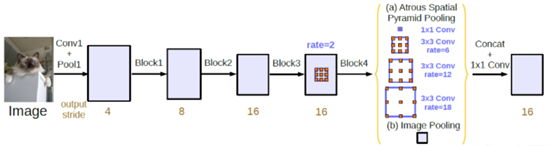
图6.添加ASPP模块网络示意图
添加ASPP模块后的网络如图6所示,将Block4的输出输入到ASPP,经过多尺度的空洞卷积采样后经过池化操作,然后由1*1卷积将通道数降低至预期值。
在DeepLabv3中,在ASPP中加入了BN层,再丢一个DeepLabv3原文链接:https://arxiv.org/pdf/1706.05587.pdf
最后附一个没有BN层的ASPP代码(PyTorch)
#without bn version
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
self.mean = nn.AdaptiveAvgPool2d((1, 1)) #(1,1)means ouput_dim
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net
参考连接:
https://www.cnblogs.com/zongfa/p/9076311.html
https://blog.csdn.net/qq_26898461/article/details/50424240
https://zhuanlan.zhihu.com/p/27485018
https://blog.csdn.net/qq_36530992/article/details/102628455