论文名称:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
论文下载:https://arxiv.org/abs/1606.00915
论文年份:TPAMI 2016
论文被引:11363(2022/05/16)
论文代码:http://liangchiehchen.com/projects/DeepLab.html
论文笔记
本文作者通过对特征分辨率进行控制、引入多尺度池化技术并将 [22] 的密集连接 CRF 集成到 DCNN 之上来扩展之前的图像分割工作,并命名为 DeepLab。
为了应对图像分割(本文是语义分割)任务中存在的三个挑战:
- DCNN中连续的最大池化和下采样操作,会损害特征图的分辨率;
- 由于多尺度物体的存在,处理此问题的标准方法是向 DCNN 呈现同一图像的重新缩放版本,然后聚合特征或分数图 (feature or score maps),这会造成重复计算;
- 以目标为中心的分类器需要对空间变换保持不变性,这限制了 DCNN 的空间精度;
提出了对应的三个解决方案:
-
针对挑战一,提出空洞卷积 (atrous convolution),可以控制 DCNN 中计算特征响应的分辨率。它还允许在不增加参数数量或计算量的情况下,有效地扩大滤波器的视野以包含更大的上下文。
-
针对挑战二,受到特征金字塔的启发,提出了多孔空间金字塔池化(atrous spatial pyramid pooling,ASPP)。
-
针对挑战三,采用全连接的条件随机场 (CRF) [22] 来提高模型捕获精细细节的能力。
图像分割中大多数表现最佳的方法都采用了 DeepLab 系统的一个或两个关键要素:
-
用于高效密集特征提取的 Atrous 卷积
-
通过全连接的 CRF 对原始 DCNN 分数进行细化
Abstract
In this work we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit. First, we highlight convolution with upsampled filters, or ‘atrous convolution’, as a powerful tool in dense prediction tasks. Atrous convolution allows us to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks. It also allows us to effectively enlarge the field of view of filters to incorporate larger context without increasing the number of parameters or the amount of computation. Second, we propose atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales. ASPP probes an incoming convolutional feature layer with filters at multiple sampling rates and effective fields-of-views, thus capturing objects as well as image context at multiple scales. Third, we improve the localization of object boundaries by combining methods from DCNNs and probabilistic graphical models. The commonly deployed combination of max-pooling and downsampling in DCNNs achieves invariance but has a toll on localization accuracy. We overcome this by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF), which is shown both qualitatively and quantitatively to improve localization performance. Our proposed “DeepLab” system sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 79.7% mIOU in the test set, and advances the results on three other datasets: PASCAL-Context, PASCAL-Person-Part, and Cityscapes. All of our code is made publicly available online.
在这项工作中,我们使用深度学习解决语义图像分割的任务,并做出了三个主要贡献,这些贡献被实验证明具有实质性的实际价值。首先,我们强调使用上采样滤波器的卷积,或“atrous convolution”,作为密集预测任务中的强大工具。 Atrous 卷积允许我们明确控制在深度卷积神经网络中计算特征响应的分辨率。它还允许我们在不增加参数数量或计算量的情况下有效地扩大滤波器的视野以包含更大的上下文。其次,我们提出了多孔空间金字塔池化(atrous spatial pyramid pooling,ASPP)以在多个尺度上稳健地分割目标。 ASPP 用多个采样率和有效视野的滤波器探测传入的卷积特征层,从而在多个尺度上捕获目标和图像上下文。第三,我们通过结合 DCNN 和概率图模型的方法来改进目标边界的定位。 DCNN 中通常部署的最大池化和下采样组合实现了不变性,但会影响定位精度。我们通过将最终 DCNN 层的响应与完全连接的条件随机场 (CRF) 相结合来克服这个问题,这在定性和定量上都显示出来以提高定位性能。我们提出的“DeepLab”系统在 PASCAL VOC-2012 语义图像分割任务中实现了 state-of-art (最佳),在测试集中达到 79.7% mIOU,并在其他三个数据集上推进了结果:PASCAL-Context、PASCAL-Person-Part和 Cityscapes。我们所有的代码都在网上公开。
1 INTRODUCTION
深度卷积神经网络 (DCNNs) [1] 已将计算机视觉系统的性能推向了一系列高层次问题的飙升高度,包括图像分类 [2], [3], [4], [5], [6] 和目标检测 [7], [8], [9], [10], [11], [12],与依赖手工特征的系统相比,以端到端方式训练的 DCNN 所提供的结果要好得多。这一成功的关键是 DCNN 对局部图像变换的内置不变性 (built-in invariance),这使它们能够学习越来越抽象的数据表示 [13]。这种不变性对于分类任务显然是可取的,但可能会妨碍密集预测任务,例如语义分割 (semantic segmentation),其中不希望抽象空间信息。
特别是,我们考虑了将 DCNN 应用于语义图像分割的三个挑战:
-
1)降低特征分辨率
-
2)存在多个尺度的目标
-
3)由于 DCNN 不变性而降低了定位精度
接下来,我们将讨论这些挑战以及提出的 DeepLab 系统中克服这些挑战的方法。
第一个挑战是由在最初为图像分类 [2], [4], [5] 设计的 DCNN 的连续层上执行的最大池化和下采样(“跨步”)的重复组合引起的。当以完全卷积方式使用 DCNN [14] 时,这会导致特征图的空间分辨率显着降低。为了克服这一障碍并有效地生成更密集的特征图,我们从 DCNN 的最后几个最大池化层中移除了下采样算子,取而代之的是对后续卷积层中的滤波器进行上采样,从而以更高的采样率计算特征图。滤波器上采样相当于在非零滤波器抽头 (nonzero filter taps) 之间插入孔(法语中的“trous”)。这种技术在信号处理方面有着悠久的历史,最初是为有效计算未抽取小波变换 (undecimated wavelet transform) 而开发的,该方案也称为“algorithme à trous”[15]。我们使用术语空洞卷积 (atrous convolution) 作为带有上采样滤波器的卷积的简写。 [3], [6], [16] 之前已经在 DCNN 的上下文中使用了这种想法的各种风格。在实践中,我们通过结合多孔卷积来恢复全分辨率特征图,该卷积计算更密集的特征图,然后对原始图像大小的特征响应进行简单的双线性插值。该方案为在密集预测任务中使用反卷积层 [13], [14] 提供了一种简单而强大的替代方案。与具有较大滤波器的常规卷积相比,atrous 卷积允许我们在不增加参数数量或计算量的情况下有效地扩大滤波器的视野。
第二个挑战是由多尺度物体的存在引起的。处理此问题的标准方法是向 DCNN 呈现同一图像的重新缩放版本,然后聚合特征或分数图 (feature or score maps) [6], [17], [18]。我们证明了这种方法确实提高了系统的性能,但代价是为输入图像的多个缩放版本计算所有 DCNN 层的特征响应。相反,受空间金字塔池 [19], [20] 的启发,我们提出了一种计算有效的方案,即在卷积之前以多个比率 (multiple rate) 对给定特征层进行重采样。这相当于使用具有互补有效视野的多个滤波器探测原始图像,从而在多个尺度上捕获目标以及有用的图像上下文。实际上,我们没有重新采样特征,而是使用具有不同采样率的多个并行空洞卷积层有效地实现了这种映射;我们将所提出的技术称为多孔空间金字塔池化(atrous spatial pyramid pooling,ASPP)。
第三个挑战与以目标为中心的分类器需要对空间变换保持不变性这一事实有关,这从本质上限制了 DCNN 的空间精度。缓解此问题的一种方法是在计算最终分割结果时使用跳过层从多个网络层中提取“hyper-column”特征 [14], [21]。我们的工作探索了一种非常有效的替代方法。特别是,我们通过采用全连接的条件随机场 (Conditional Random Field, CRF) [22] 来提高模型捕获精细细节的能力。 CRF 已广泛用于语义分割,将多路分类器计算的类别分数与像素和边缘 [23], [24] 或超像素 [25] 的局部交互捕获的低级信息相结合。尽管已经提出了更复杂的工作来模拟分段的层次依赖性[26], [27],[28]和/或高阶依赖性[29], [30], [31], [32], [33 ],我们使用[22]提出的全连接的成对CRF,因为它的计算效率很高,并且能够捕获精细的边缘细节,同时还可以满足长距离依赖性。该模型在 [22] 中显示,以提高基于提升的像素级分类器的性能。在这项工作中,我们证明了当与基于 DCNN 的像素级分类器结合使用时,它会产生最先进的结果。
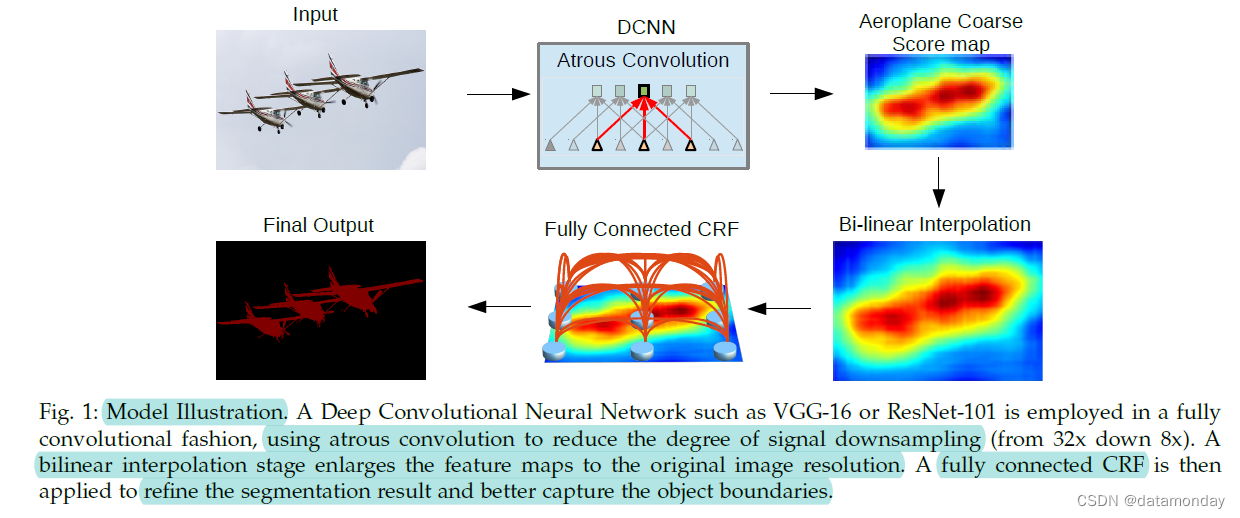
所提出的 DeepLab 模型的高级说明如图 1 所示。在图像分类任务中训练的深度卷积神经网络(本工作中的 VGG-16 [4] 或 ResNet-101 [11])被重新训练。旨在通过
-
1)将所有全连接层转换为卷积层(即全卷积网络[14])
-
2)通过多孔卷积层提高特征分辨率来完成语义分割任务,每 8 次计算特征响应像素而不是原始网络中的每 32 个像素。
然后,采用双线性插值 (bi-linear interpolation) 对分数图进行 8 倍上采样,以达到原始图像分辨率,最后输入到全连接的 CRF [22],从而改进分割结果。
从实际的角度来看,我们 DeepLab 系统的三个主要优势是:
-
1)速度:凭借空洞卷积,密集 DCNN 在 NVidia Titan X GPU 上以 8 FPS 的速度运行,而全连接 CRF 的平均场推理在 CPU 上需要 0.5 秒。
-
2)准确性:在几个具有挑战性的数据集上获得了最先进的结果,包括 PASCAL VOC 2012 语义分割基准 [34]、PASCAL-Context [35]、PASCALPerson-Part [36] 和 Cityscapes [37]。
-
3)简单性:系统由两个非常完善的模块级联 (cascade) 组成,DCNNs 和 CRFs。
与我们最初的会议出版物 [38] 中报告的第一个版本相比,我们在本文中介绍的更新后的 DeepLab 系统具有多项改进。我们的新版本可以通过多尺度输入处理 [17], [39], [40] 或提出的 ASPP 更好地分割多个尺度的目标。采用最先进的 ResNet [11] 图像分类 DCNN 构建了 DeepLab 的残差网络变体,与基于 VGG-16 [4] 的原始模型相比,实现了更好的语义分割性能。最后,我们对多个模型变体进行了更全面的实验评估,并报告了不仅在 PASCAL VOC 2012 基准测试上而且在其他具有挑战性的任务上的最新结果。我们通过扩展 Caffe 框架 [41] 实现了所提出的方法。我们在配套网站 http://liangchiehchen.com/projects/DeepLab.html 上分享我们的代码和模型。
2 RELATED WORK
过去十年开发的大多数成功的语义分割系统都依赖于手工制作的特征与平面分类器相结合,例如 Boosting [24], [42],随机森林 [43] 或支持向量机 [44]。通过结合来自上下文 [45] 和结构化预测技术 [22], [26], [27], [46] 的更丰富的信息,已经实现了实质性的改进,但是这些系统的性能总是受到有限的表达能力的影响。在过去的几年里,深度学习在图像分类方面的突破迅速转移到了语义分割任务上。由于这个任务涉及分割和分类,一个中心问题是如何结合这两个任务。
第一个基于 DCNN 的语义分割系统通常采用级联的自下而上图像分割,然后是基于 DCNN 的区域分类。例如,[47], [48] 提供的边界框建议和掩码区域 (masked regions) 在 [7] 和 [49] 中用作 DCNN 的输入,以将形状信息合并到分类过程中。同样,[50] 的作者依赖于超像素表示。即使这些方法可以从良好的分割提供的清晰边界中受益,它们也无法从任何错误中恢复。
第二类作品依赖于使用卷积计算的 DCNN 特征进行密集图像标记,并将它们与独立获得的分割相结合。首先是 [39],他们在多种图像分辨率下应用 DCNN,然后使用分割树来平滑预测结果。最近,[21] 提出使用跳过层并将 DCNN 中计算的中间特征图连接起来进行像素分类。此外,[51] 建议通过区域提议来汇集中间特征图。这些工作仍然使用与 DCNN 分类器的结果分离的分割算法,因此有可能做出过早的决定。
第三类作品使用 DCNN 直接提供密集的类别级像素标签,这甚至可以完全丢弃分割。[14], [52] 的无分割方法以完全卷积的方式直接将 DCNN 应用于整个图像,将 DCNN 的最后一个完全连接的层转换为卷积层。
-
为了处理引言中概述的空间定位问题,[14] 对来自中间特征图的分数进行上采样和连接,
-
而[52]通过将粗略结果传播到另一个DCNN来从粗略 (coarse) 到精细 (fine) 地改进预测结果。
我们的工作建立在这些工作的基础上,如引言中所述,通过对特征分辨率进行控制、引入多尺度池化技术并将 [22] 的密集连接 CRF 集成到 DCNN 之上来扩展它们。我们表明,这会导致明显更好的分割结果,尤其是在目标边界上。 DCNN 和 CRF 的结合当然不是新的,但之前的工作只是尝试了局部连接的 CRF 模型。具体来说,[53] 使用 CRF 作为基于 DCNN 的重新排序系统的提议机制,而 [39] 将超像素视为局部成对 CRF 的节点,并使用图形切割进行离散推理。因此,他们的模型受到超像素计算错误或忽略远程依赖性的限制。相反,我们的方法将每个像素视为一个 CRF 节点,由 DCNN 接收一元势 (unary potentials)。至关重要的是,我们采用的 [22] 的全连接 CRF 模型中的高斯 CRF 势 (potentials) 可以捕获远程依赖关系,同时该模型可以进行快速平均场推断 (mean field inference)。我们注意到平均场推断已被广泛研究用于传统的图像分割任务 [54], [55], [56],但这些较旧的模型通常仅限于短程连接。在独立工作中,[57] 使用非常相似的密集连接 CRF 模型来细化 DCNN 对材料分类问题的结果。然而,[57] 的 DCNN 模块仅通过稀疏点监督而不是每个像素的密集监督进行训练。
自从这项工作的第一个版本公开 [38] 以来,语义分割领域取得了长足的进步。多个小组取得了重要进展,显着提高了 PASCAL VOC 2012 语义分割基准的标准,这反映在基准排行榜中的高水平活动 [17], [40], [58], [59], [60 ], [61], [62], [63]。有趣的是,大多数表现最佳的方法都采用了我们 DeepLab 系统的一个或两个关键要素:用于高效密集特征提取的 Atrous 卷积和通过完全连接的 CRF 对原始 DCNN 分数进行细化。我们在下面概述了一些最重要和最有趣的进步。
最近在几项相关工作中探索了结构化预测的端到端训练。虽然我们使用 CRF 作为后处理方法,但 [40], [59], [62], [64], [65] 已经成功地实现了 DCNN 和 CRF 的联合学习。特别是,
-
[59], [65] 展开 CRF 平均场推断步骤,将整个系统转换为端到端可训练的前馈网络,
-
而 [62] 近似于密集 CRF 平均场推断的一次迭代 [22] 通过带有可学习滤波器的卷积层。
-
[40], [66] 追求的另一个富有成果的方向是通过 DCNN 学习 CRF 的成对项,以增加计算量为代价显着提高性能。
-
在不同的方向上,[63] 用更快的域变换模块 [67] 替换了平均场推断中使用的双边滤波模块,提高了速度并降低了整个系统的内存需求,
-
而 [18], [68] 结合了带有边缘检测的语义分割。
许多论文都在追求更弱的监督,放宽了像素级语义注释可用于整个训练集的假设 [58], [69], [70], [71],取得了明显优于弱监督 pre-DCNN 系统,例如 [72]。在另一个研究领域,[49], [73] 追求实例分割,联合处理目标检测和语义分割。
我们在这里所说的 atrous 卷积最初是为了有效计算 [15] 的“algorithme à trous”方案中的未抽取小波变换而开发的。感兴趣的读者可以阅读 [74],以获取小波文献的早期参考资料。Atrous 卷积也与多速率信号处理中的“noble identities”密切相关,它建立在输入信号和滤波器采样率的相同相互作用之上 [75]。Atrous 卷积是我们在 [6] 中首次使用的术语。相同的操作后来被 [76] 称为扩张卷积,他们创造了一个术语,因为该操作对应于带有上采样(或 [15] 的术语中的扩张)滤波器的常规卷积。许多作者之前在 DCNN [3], [6], [16] 中使用相同的操作进行更密集的特征提取。除了单纯的分辨率增强之外,atrous 卷积还允许我们扩大滤波器的视野以包含更大的上下文,我们在 [38] 中已经证明这是有益的。 [76] 进一步采用了这种方法,他们使用了一系列具有递增速率的空洞卷积层来聚合多尺度上下文。这里提出的用于捕获多尺度目标和上下文的空洞空间金字塔池化方案还采用了具有不同采样率的多个空洞卷积层,但是我们将它们并行而不是串行布局。有趣的是,atrous 卷积技术也被用于更广泛的任务,例如目标检测 [12], [77],实例级分割 [78],视觉问答 [79] 和光流 (optical flow) [80]。
我们还表明,正如预期的那样,将更高级的图像分类 DCNN (例如 [11] 的残差网络)集成到 DeepLab 中会产生更好的结果。 [81] 也独立观察到了这一点。
3 METHODS
3.1 Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
通过以全卷积方式部署 DCNN [3], [14],已证明使用 DCNN 进行语义分割或其他密集预测任务可以简单且成功地解决。然而,在这些网络的连续层上,最大池化和跨步的重复组合显着降低了生成的特征图的空间分辨率,通常在最近的 DCNN 中每个方向上降低 32 倍。部分补救措施是使用 [14] 中的“反卷积”层,但这需要额外的内存和时间。
我们提倡使用空洞卷积,最初是为了在 [15] 的“algorithme à trous”方案中高效计算未抽取小波变换而开发的,之前在 [3], [6], [16] 的 DCNN 上下文中使用过。该算法允许以任何所需的分辨率计算任何层的响应。一旦网络经过训练,它就可以在事后应用 (post-hoc),但也可以与训练无缝集成。
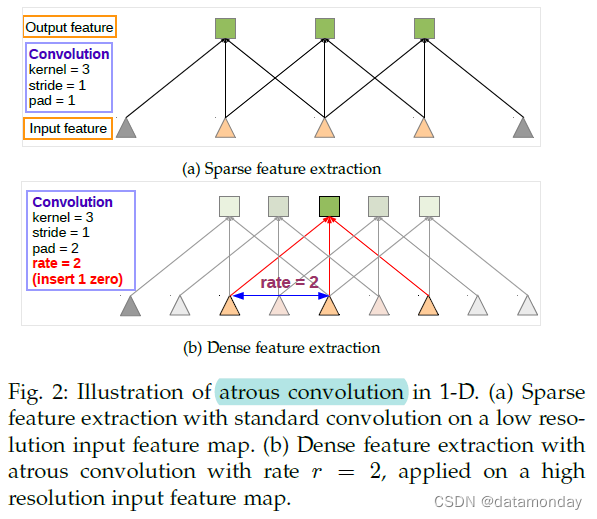
首先考虑一维信号,具有长度为 K 的滤波器 w[k] 的一维输入信号 x[i] 的空洞卷积的输出 y[i] 定义为:
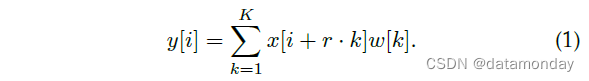
速率参数 r 对应于对输入信号进行采样的步幅。标准卷积是速率 r = 1 的特殊情况。参见图 2 进行说明。

我们通过图 3 中的一个简单示例来说明该算法在 2-D 中的操作:给定一张图像,假设首先进行下采样操作,将分辨率降低 2 倍,然后使用卷积核执行卷积——这里是垂直高斯导数 (vertical Gaussian derivative)。如果将生成的特征图植入原始图像坐标中,则仅在图像位置的 1/4 处获得了响应。相反,如果将全分辨率图像与“带孔”滤波器进行卷积,可以计算所有图像位置的响应,其中将原始滤波器上采样 2 倍,并在滤波器值之间引入零。尽管有效滤波器大小增加,但我们只需要考虑非零滤波器值,因此滤波器参数的数量和每个位置的操作数量都保持不变。由此产生的方案使我们能够轻松而明确地控制神经网络特征响应的空间分辨率。
在 DCNN 的上下文中,可以在一系列层中使用 atrous 卷积,从而有效地允许我们以任意高分辨率计算 5 个最终 DCNN 网络响应。
-
例如,为了使 VGG-16 或 ResNet-101 网络中计算的特征响应的空间密度加倍,我们找到最后一个降低分辨率的池化或卷积层(分别为“pool5”或“conv5 1”),将其设置为步幅为 1 以避免信号抽取,并用速率 r = 2 的多孔卷积层替换所有后续卷积层。将这种方法一直推到网络中可以让我们以原始图像分辨率计算特征响应,但这最终会太昂贵了。
-
相反,我们采用了一种混合方法,可以在效率/准确性之间取得良好的平衡,使用多孔卷积将计算的特征图的密度增加 4 倍,然后使用快速双线性插值增加 8 倍来恢复特征图以原始图像分辨率。在这种情况下,双线性插值就足够了,因为类得分图(对应于对数概率)非常平滑,如图 5 所示。与 [14] 采用的反卷积方法不同,所提出的方法将图像分类网络转换为密集特征提取器不需要学习任何额外的参数,从而在实践中实现更快的 DCNN 训练。
Atrous 卷积还允许在任何 DCNN 层任意扩大滤波器的视野。最先进的 DCNN 通常采用空间小的卷积核(通常为 3×3),以保持计算和包含的参数数量。速率为 r 的 Atrous 卷积在连续滤波器值之间引入 r - 1 个零,有效地将 k ×k 滤波器的卷积核大小扩大到 ke = k + (k - 1)(r - 1) 而不增加参数数量或数量计算。因此,它提供了一种控制视野 (field-of-view) 的有效机制,在 (accurate localization) 准确定位(小视野)和 (context assimilation) 上下文同化(大视野)之间找到最佳平衡。我们已经成功地试验了这种技术:我们的 DeepLab-LargeFOV 模型变体 [38] 在 VGG-16 ‘fc6’ 层中采用速率 r = 12 的多孔卷积,性能显着提升,详见第 4 节。
在实现方面,有两种有效的方法来执行空洞卷积。
-
第一种是通过插入孔(零)来隐式上采样滤波器,或者等效地对输入特征图进行稀疏采样[15]。我们在早期的工作 [6], [38] 和 [76] 中实现了这一点,在 Caffe 框架 [41] 中,通过向 im2col 函数(它从多通道特征图中提取矢量化补丁)添加对底层特征图进行稀疏采样的选项。
-
第二种方法,最初由 [82] 提出并在 [3], [16] 中使用,是对输入特征图进行二次采样,系数等于空洞卷积率 r r r,将其去交错以生成 r 2 r^2 r2 个降低分辨率的图,每个图 r × r r×r r×r 个可能的移位。接下来是对这些中间特征图应用标准卷积并将它们重新交错 (reinterlacing) 到原始图像分辨率。通过将空洞卷积减少为常规卷积,它允许使用现成的高度优化的卷积例程。
我们已经在 TensorFlow 框架 [83] 中实现了第二种方法。
3.2 Multiscale Image Representations using Atrous Spatial Pyramid Pooling
DCNN 已显示出隐式表示规模的非凡能力,只需在包含不同大小目标的数据集上进行训练即可。尽管如此,明确考虑目标规模可以提高 DCNN 成功处理大小目标的能力 [6]。
我们已经尝试了两种方法来处理语义分割中的尺度变化。第一种方法相当于标准的多尺度处理[17],[18]。我们使用共享相同参数的并行 DCNN 分支从多个(在我们的实验中为三个)重新缩放的原始图像版本中提取 DCNN 分数图。为了产生最终结果,我们将并行 DCNN 分支的特征图双线性插值到原始图像分辨率,并通过在每个位置获取不同尺度的最大响应来融合它们。我们在训练和测试期间都这样做。多尺度处理显着提高了性能,但代价是在所有 DCNN 层为多尺度输入计算特征响应。

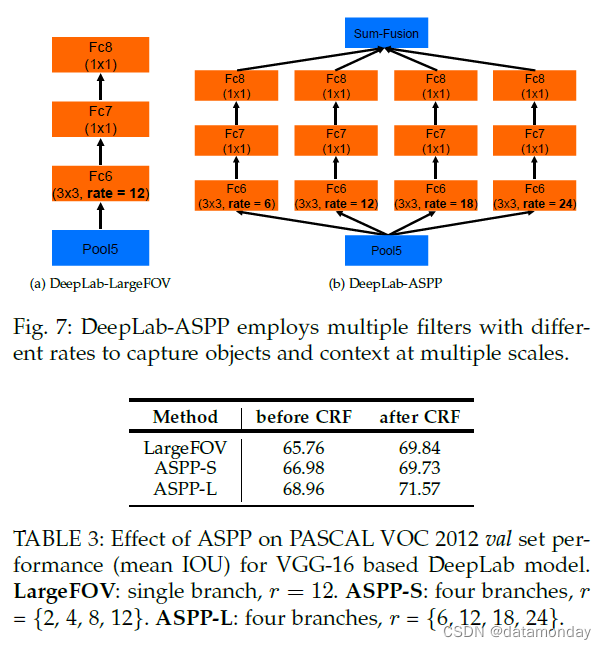
第二种方法的灵感来自 [20] 的 R-CNN 空间金字塔池化方法的成功,该方法表明通过对在单个尺度上提取的卷积特征进行重采样,可以准确有效地对任意尺度的区域进行分类。我们已经实现了他们方案的一个变体,它使用多个具有不同采样率的并行空洞卷积层。为每个采样率提取的特征在单独的分支中进一步处理并融合以生成最终结果。提出的“多孔空间金字塔池化”(DeepLabASPP)方法概括了我们的 DeepLab-LargeFOV 变体,如图 4 所示。
3.3 Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
定位精度和分类性能之间的权衡似乎是 DCNN 固有的:具有多个最大池化层的更深模型已被证明在分类任务中最成功,但是增加的不变性和顶级节点的大感受野只能产生平滑的响应 (smooth responses)。如图 5 所示,DCNN 分数图可以预测物体的存在和粗略位置,但不能真正描绘它们的边界。

以前的工作追求两个方向来解决这一定位挑战 (localization challenge)。
-
第一种方法是利用来自卷积网络中多个层的信息,以便更好地估计目标边界 [14], [21], [52]。
-
第二个是采用超像素表示,本质上将定位任务委托给低级分割方法 [50]。
我们基于将 DCNN 的识别能力和全连接 CRF 的细粒度定位精度相结合来寻求另一个方向,并表明它在解决定位挑战、产生准确的语义分割结果和在远超出现有方法的细节水平上恢复对象边界方面非常成功。现有方法无法达到的细节。自从我们工作的第一篇论文 [38] 发表以来,这个方向已经被几篇后续论文 [17], [40], [58], [59], [60], [61], [62], [63], [65] 延伸。
传统上,条件随机场 (CRF) 已被用于平滑噪声分割图 [23], [31]。通常,这些模型会耦合相邻节点,有利于将相同标签分配给空间上邻近的像素。定性地说,这些短程 CRF 的主要功能是清理建立在本地手工工程特征之上的弱分类器的虚假预测。
与这些较弱的分类器相比,我们在这项工作中使用的现代 DCNN 架构会产生质量不同的分数图和语义标签预测。如图 5 所示,得分图通常非常平滑并产生同质的 (homogeneous) 分类结果。在这种情况下,使用短程 CRF 可能是有害的,因为我们的目标应该是恢复详细的局部结构,而不是进一步平滑它。将对比敏感势 (contrastsensitive potentials) [23] 与局部范围 CRF 结合使用可以潜在地改善定位,但仍然会错过薄结构,并且通常需要解决昂贵的离散优化问题。
为了克服短程 CRF 的这些限制,我们将 [22] 的全连接 CRF 模型集成到系统中。该模型采用能量函数 (energy function)

其中 x 是像素的标签分配。我们使用 (unary potential) 一元势 θi(xi) = − log P (xi),其中 P (xi) 是由 DCNN 计算的像素 i 处的标签分配概率。
成对势 (pairwise potential) 的形式允许在使用全连接图时进行有效推理,即在连接所有图像像素对 i, j 时,特别是,如在 [22] 中,使用以下表达式:
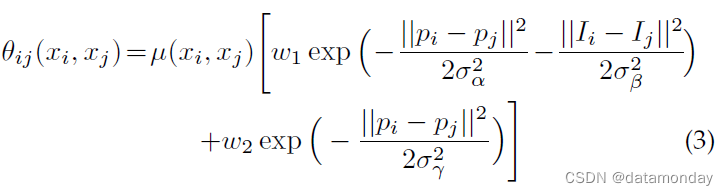
其中,如果 x i ≠ x j x_i \neq x_j xi=xj,则 µ ( x i , x j ) = 1 µ(x_i, x_j) = 1 µ(xi,xj)=1,否则为零,与 Potts 模型一样,这意味着只有具有不同标签的节点才会受到惩罚。
-
剩下的表达式在不同的特征空间中使用了两个高斯核;第一个,“双边”卷积核取决于像素位置(表示为 p)和 RGB 颜色(表示为 I),第二个卷积核仅取决于像素位置。
-
超参数 σα、σβ 和 σγ 控制高斯核的尺度。
-
第一个卷积核强制具有相似颜色和位置的像素具有相似的标签,而第二个卷积核在强制平滑时只考虑空间接近度。
至关重要的是,该模型适用于有效的近似概率推理 [22]。在完全可分解的平均场近似 b ( x ) = ∏ i b i ( x i ) b(x) = \prod _i b_i(x_i) b(x)=∏ibi(xi) 下的消息传递更新可以表示为双边空间中的高斯卷积。高维滤波算法 [84] 显着加快了这种计算速度,从而使算法在实践中非常快,使用 [22] 的公开实现的 Pascal VOC 图像平均需要不到 0.5 秒。
4.1 PASCAL VOC 2012
数据集:PASCAL VOC 2012 分割基准 [34] 涉及 20 个前景目标类和一个背景类。原始数据集包含 1464 (训练),1449(验证)和 1456(测试)像素级标记图像,分别用于训练、验证和测试。该数据集通过 [85] 提供的额外注释进行了扩充,产生了 10582 个(trainaug)训练图像。性能是根据 21 个类别的平均像素交叉联合 (IOU) 来衡量的。
4.1.1 Results from our conference version
我们使用在 Imagenet 上预训练的 VGG-16 网络,适用于语义分割,如第 3.1 节所述。我们使用 20 张图像的小批量和 0.001 的初始学习率(最终分类器层为 0.01),每 2000 次迭代将学习率乘以 0.1。我们使用 0.9 的动量和 0.0005 的重量衰减。
在 DCNN 在 trainaug 上进行微调后,我们按照 [22] 的思路交叉验证 CRF 参数。我们使用默认值 w2 = 3 和 σγ = 3,并通过对来自 val 的 100 个图像进行交叉验证来搜索 w1、σα 和 σβ 的最佳值。我们采用从粗到细的搜索方案。参数的初始搜索范围是 w1 ∈ [3 : 6]、σα ∈ [30 : 10 : 100] 和 σβ ∈ [3 : 6](MATLAB 表示法),然后我们在第一轮的周围细化搜索步长最佳值。我们采用 10 次平均场迭代。
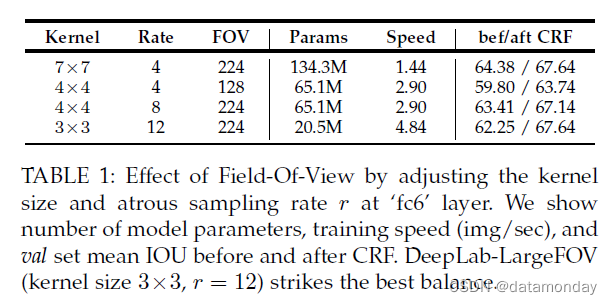
视野和 CRF:如表 1 所示,我们报告了使用不同视野大小的 DeepLab 模型变体的实验,这些变体是通过调整“fc6”层中的卷积核大小和空洞采样率 r 而获得的,如 Sec.3.1 中所述。我们从 VGG-16 网络的直接改编开始,使用原始的 7 × 7 卷积核大小和 r = 4(因为我们对最后两个最大池化层没有使用跨步)。该模型在 CRF 之后的性能为 67.64%,但相对较慢(训练期间每秒 1.44 张图像)。通过将卷积核大小减小到 4 × 4,我们将模型速度提高到每秒 2.9 张图像。我们已经尝试了两种具有更小 (r = 4) 和更大 (r = 8) FOV 大小的网络变体;后者表现更好。最后,我们采用 3×3 的卷积核大小和更大的空洞采样率 (r = 12),通过在“fc6”和“fc7”层的 4096 个滤波器中保留 1024 个随机子集来使网络更薄。生成的模型 DeepLab-CRFLargeFOV 与直接 VGG-16 自适应的性能相匹配(7 × 7 卷积核大小,r = 4)。同时,DeepLab-LargeFOV 的速度提高了 3.36 倍,参数明显更少(20.5M 而不是 134.3M)。
CRF 显着提高了所有模型变体的性能,平均 IOU 增加了 3-5%。
测试集评估:我们在 PASCAL VOC 2012 官方测试集上评估了我们的 DeepLabCRF-LargeFOV 模型。它达到了 70.3% 的平均 IOU 性能。
4.1.2 Improvements after conference version of this work
在这项工作的会议版本 [38] 之后,我们对我们的模型进行了三个主要改进,我们将在下面讨论:
-
1)训练期间的不同学习策略
-
2)atrous 空间金字塔池化
-
3)使用更深层次的网络和多尺度处理
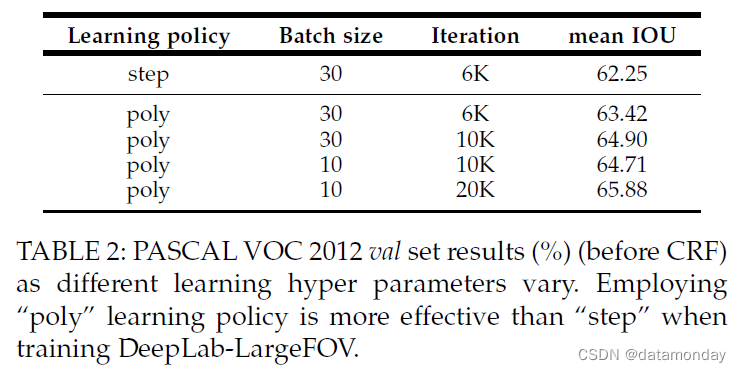
学习率策略:我们在训练 DeepLab-LargeFOV 时探索了不同的学习率策略。与 [86] 类似,我们还发现采用 poly 学习率策略(学习率乘以 ( 1 − i t e r / m a x i t e r ) p o w e r (1− iter/max \ iter)^{power} (1−iter/max iter)power)比 step 学习率(将学习率降低到固定步长)更有效。如表 2 所示,使用“poly”(幂 = 0.9)并使用相同的批量大小和相同的训练迭代产生的性能比使用“step”策略好 1.17%。固定batch size并将训练迭代增加到10K,性能提升到64.90%(增益1.48%);但是,由于更多的训练迭代,总训练时间会增加。然后,我们将批量大小减少到 10,发现仍然保持可比的性能(64.90% 对 64.71%)。最后,我们采用批量大小 = 10 和 20K 迭代,以保持与之前的“步骤”策略相似的训练时间。令人惊讶的是,这使我们在 val 上的性能提高了 65.88%(比“step”提高了 3.63%),在测试上提高了 67.7%,而在 CRF 之前 DeepLabLargeFOV 的原始“step”设置为 65.1%。我们对本文其余部分报告的所有实验采用“poly”学习率策略。
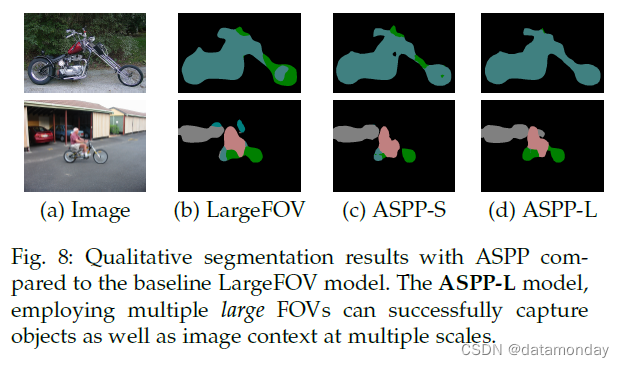
Atrous Spatial Pyramid Pooling:我们已经尝试了提出的 Atrous Spatial Pyramid Pooling (ASPP) 方案,在 Sec.3.1 中描述。如图 7 所示,VGG-16 的 ASPP 采用了几个并行的 fc6-fc7-fc8 分支。它们都使用 3×3 卷积核,但在“fc6”中使用不同的空洞率 r,以便捕获不同大小的目标。在选项卡中。如表 3 所示,我们报告了几个设置的结果:(1)我们的基线 LargeFOV 模型,有一个 r = 12 的分支,(2)ASPP-S,有四个分支和较小的开口率(r = {2, 4, 8, 12})和(3)ASPP-L,具有四个分支和更大的速率(r = {6, 12, 18, 24})。对于每个变体,我们在 CRF 之前和之后报告结果。如表所示,ASPP-S 比 CRF 之前的基线 LargeFOV 提高了 1.22%。然而,在 CRF 之后,LargeFOV 和 ASPP-S 的表现相似。另一方面,ASPP-L 在 CRF 之前和之后都比基线 LargeFOV 产生了一致的改进。我们在测试中评估了提议的 ASPP-L + CRF 模型,达到 72.6%。我们在图 8 中可视化了不同方案的效果。
更深的网络和多尺度处理:我们已经尝试围绕最近提出的残差网络 ResNet-101 [11] 而不是 VGG-16 构建 DeepLab。与我们对 VGG-16 网络所做的类似,我们通过空洞卷积重新使用 ResNet101,如 Sec.3.1 中所述。最重要的是,我们采用了其他几个特征,继最近 [17], [18], [39], [40], [58], [59], [62] 的工作之后:(1)多尺度输入:我们分别以 scale = {0.5, 0.75, 1} 向 DCNN 图像提供数据,通过分别获取每个位置的最大响应来融合它们的分数图 [17]。 (2) 在 MS-COCO [87] 上预训练的模型。 (3) 通过在训练期间随机缩放输入图像(从 0.5 到 1.5)来增强数据。在选项卡中。在表 4 中,我们评估了这些因素中的每一个,以及 LargeFOV 和空洞空间金字塔池 (ASPP) 对验证集性能的影响。采用 ResNet-101 而不是 VGG-16 显着提高了 DeepLab 的性能(例如,我们最简单的基于 ResNet-101 的模型达到了 68.72%,而我们基于 DeepLab-LargeFOV VGG-16 的变体在 CRF 之前达到了 65.76%)。多尺度融合 [17] 带来了 2.55% 的额外改进,而在 MS-COCO 上预训练模型又带来了 2.01% 的收益。训练期间的数据增强是有效的(大约 1.6% 的改进)。使用 LargeFOV(在 ResNet 之上添加一个多孔卷积层,具有 3×3 卷积核和速率 = 12)是有益的(大约 0.6% 的改进)。空间金字塔池化 (ASPP) 进一步提高了 0.8%。通过密集 CRF 对我们最好的模型进行后处理,可以得到 77.69% 的性能。


定性结果:我们在图 6 中提供了 CRF 之前和之后 DeepLab 的结果(我们的最佳模型变体)的定性视觉比较。DeepLab 在 CRF 之前获得的可视化结果已经产生了出色的分割结果,而使用 CRF 通过去除进一步提高了性能误报和细化目标边界。
测试集结果:我们已经将最终最佳模型的结果提交到官方服务器,测试集性能达到 79.7%,如表 5 所示。该模型大大优于以前的 DeepLab 变体(例如,带有 VGG-16 网络的 DeepLab-LargeFOV),目前是 PASCAL VOC 2012 分割排行榜上表现最好的方法。
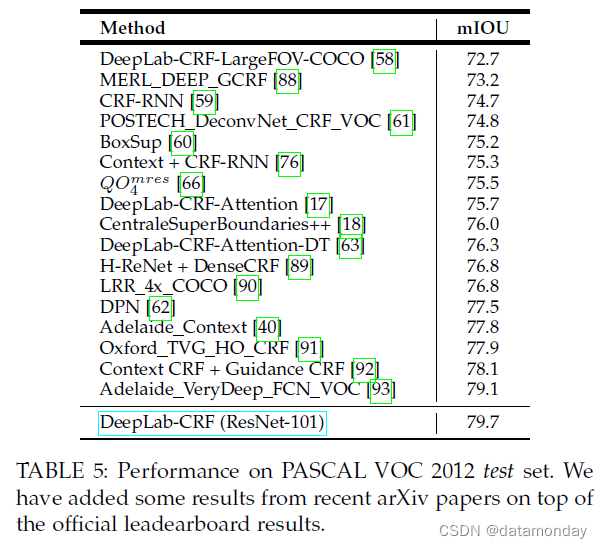
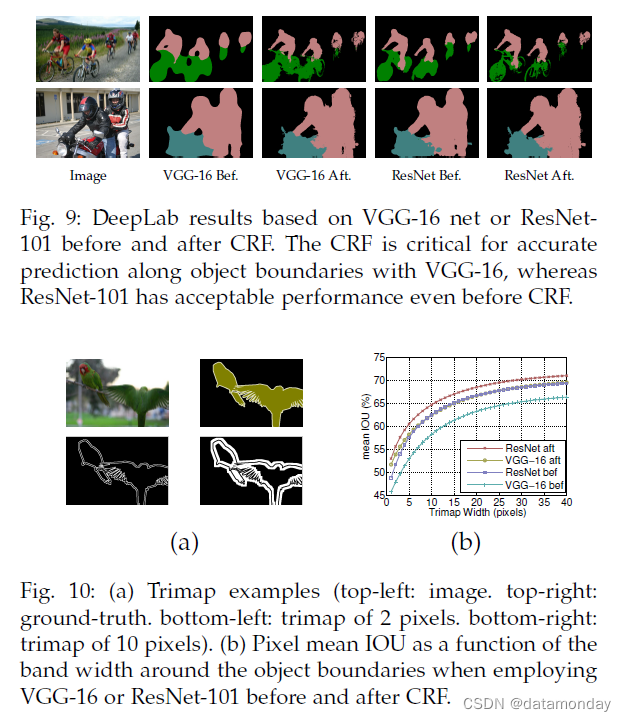
VGG-16 vs. ResNet-101:我们观察到,与使用 VGG16 [4] 相比,基于 ResNet-101 [11] 的 DeepLab 沿目标边界提供了更好的分割结果,如图 9 所示。我们认为身份映射 [94 ResNet-101 的 ] 具有与超列特征 [21] 类似的效果,它利用中间层的特征来更好地定位边界。我们在“trimap”[22], [31](沿目标边界的窄带)中进一步量化了图 10 中的这种效果。如图所示,在 CRF 之前使用 ResNet-101 在目标边界上的精度与使用 VGG-16 和 CRF 几乎相同。使用 CRF 对 ResNet-101 结果进行后处理进一步改进了分割结果。
4.2 PASCAL-Context
数据集:PASCAL-Context 数据集 [35] 为整个场景提供详细的语义标签,包括目标(例如,人)和东西(例如,天空)。在 [35] 之后,提出的模型在最常见的 59 个类别和一个背景类别上进行评估。训练集和验证集包含 4998 和 5105 张图像。
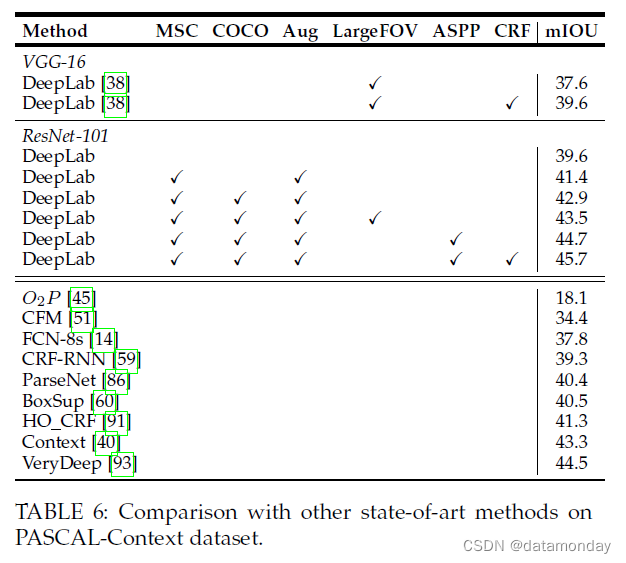
评估:我们在表 6 中报告评估结果。我们基于 VGG-16 的 LargeFOV 变体在 CRF 之前和之后分别为 37.6% 和 39.6%。为 DeepLab 重新利用 ResNet-101 [11] 比 VGG-16 LargeFOV 提高了 2%。与 [17] 类似,采用多尺度输入和最大池来合并结果将性能提高到 41.4%。在 MS-COCO 上预训练模型带来了额外 1.5% 的改进。采用多孔空间金字塔池化比 LargeFOV 更有效。在进一步使用密集 CRF 作为后处理后,我们的最终模型产生 45.7%,在不使用非线性成对项的情况下,比当前最先进的方法 [40] 高出 2.4%。我们的最终模型比并发工作 [93] 略好 1.2%,后者还采用了多孔卷积将 [11] 的残差网络重新用于语义分割。
定性结果:我们将使用和不使用 CRF 的最佳模型的分割结果可视化为图 11 中的后处理。CRF 之前的 DeepLab 已经可以高精度地预测大部分目标/东西。使用 CRF,我们的模型能够进一步消除孤立的误报并改进沿目标/东西边界的预测。

4.3 PASCAL-Person-Part
数据集:我们使用 [36] 的额外 PASCAL VOC 2010 注释进一步对语义部分分割 [98], [99] 进行实验。我们专注于数据集的人物部分,其中包含更多的训练数据以及目标尺度和人体姿势的较大变化。具体来说,数据集包含每个人的详细部分注释,例如眼睛,鼻子。我们将标注合并为 Head、Torso、Upper/Lower Arms 和 Upper/Lower Legs,从而产生六个人物部分类和一个背景类。我们只使用那些包含人员的图像进行训练(1716 张图像)和验证(1817 张图像)。

评估:PASCAL-Person-Part 上的人体部分分割结果见表 7。[17] 已经在这个数据集上进行了实验,为 DeepLab 重新使用了 VGG-16 网络,达到了 56.39%(多尺度输入)。因此,在这一部分中,我们主要关注将 ResNet-101 重新用于 DeepLab 的效果。使用 ResNet-101,仅 DeepLab 的收益率为 58.9%,分别显着优于 DeepLab-LargeFOV(VGG-16 网络)和 DeepLab-Attention(VGG-16 网络)约 7% 和 2.5%。通过最大池化结合多尺度输入和融合进一步将性能提高到 63.1%。此外,在 MS-COCO 上对模型进行预训练会产生另外 1.3% 的改进。但是,在此数据集上采用 LargeFOV 或 ASPP 时,我们没有观察到任何改进。使用密集的 CRF 对我们的最终输出进行后期处理,其性能大大优于并发工作 [97] 4.78%。
定性结果:我们将结果可视化在图 12 中。

4.4 Cityscapes
数据集:Cityscapes [37] 是最近发布的大规模数据集,其中包含从 50 个不同城市的街景中收集的 5000 张图像的高质量像素级注释。遵循评估协议[37],19 个语义标签(属于 7 个超类别:地面、建筑、物体、自然、天空、人类和车辆)用于评估(不考虑空标签进行评估)。训练集、验证集和测试集分别包含 2975、500 和 1525 张图像。
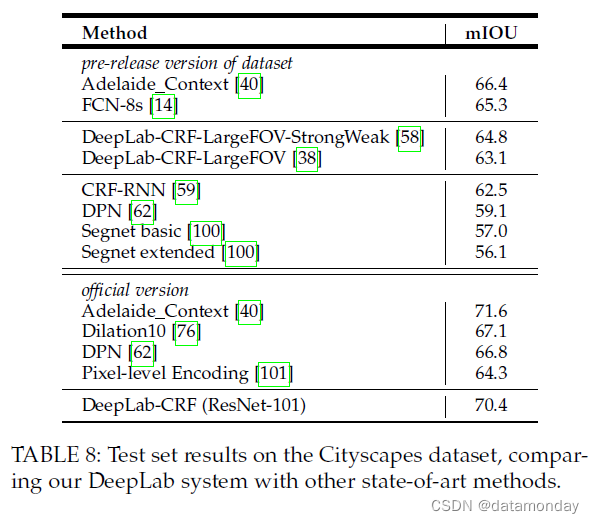
预发布测试集结果:我们参与了 Cityscapes 数据集预发布的基准测试。在表 8 中,我们的模型获得了第三名,性能分别为 63.1% 和 64.8%(在额外的粗标注图像上进行了训练)。

验证集结果:在初始发布后,我们进一步探索了表 9 中的验证集。Cityscapes 的图像分辨率为 2048×1024,这使得在 GPU 内存有限的情况下训练更深的网络成为一个具有挑战性的问题。在对数据集的预发布进行基准测试期间,我们将图像下采样了 2。但是,我们发现以原始分辨率处理图像是有益的。在相同的训练协议下,使用原始分辨率的图像在 CRF 之前和之后分别显着提高了 1.9% 和 1.8%。为了使用高分辨率图像对该数据集进行推理,我们将每个图像分成重叠区域,类似于 [37]。我们还用 ResNet101 替换了 VGG-16 网络。由于手头有限的 GPU 内存,我们不利用多尺度输入。相反,我们只探索 (1) 更深层次的网络(即 ResNet-101),(2) 数据增强,(3) LargeFOV 或 ASPP,以及 (4) CRF 作为该数据集的后处理。我们首先发现单独使用 ResNet-101 比使用 VGG-16 网络要好。使用 LargeFOV 带来了 2.6% 的改进,使用 ASPP 进一步将结果提高了 1.2%。采用数据增强和 CRF 作为后处理分别带来 0.6% 和 0.4%。
当前测试结果:我们已经将我们最好的模型上传到了评估服务器,获得了70.4%的性能。请注意,我们的模型仅在训练集上进行训练。
定性结果:我们将结果可视化在图 13 中。

4.5 Failure Modes
我们进一步定性地分析了我们在 PASCAL VOC 2012 验证集上的最佳模型变体的一些故障模式。如图 14 所示,我们提出的模型未能捕捉到物体的精细边界,例如自行车和椅子。由于一元项不够自信,CRF 后处理甚至无法恢复细节。我们假设 [100] 的编码器-解码器结构,[102] 可以通过利用解码器路径中的高分辨率特征图来缓解问题。如何有效地结合该方法是未来的工作。

5 CONCLUSION
我们提出的“DeepLab”系统通过将“atrous convolution”与上采样滤波器应用于密集特征提取,将图像分类训练的网络重新用于语义分割任务。我们进一步将其扩展到多孔空间金字塔池化,它在多个尺度上对目标和图像上下文进行编码。为了沿目标边界生成语义准确的预测和详细的分割图,我们还结合了来自深度卷积神经网络和全连接条件随机场的想法。我们的实验结果表明,所提出的方法在几个具有挑战性的数据集中显着提高了 state-of-art,包括 PASCAL VOC 2012 语义图像分割基准、PASCAL Context、PASCAL-Person-Part 和 Cityscapes 数据集。