版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/kevin_zhao_zl/article/details/84561137
论文地址 :DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
论文代码:工程链接
1. 简介
DeepLabV2是在V1基础上的优化,不同与V1,模型采用Resnet代替VGG-16,提出ASPP代替标准多尺度处理进行多尺度的特征的捕捉和融合,取得了更好的效果。
2. 主要问题
- 下采样导致特征分辨率的降低
- 多尺度对象信息
- DCNN内在不变性导致定位精度低
3. 解决方案
- 空洞卷积解决感受野和分辨率的问题:最后及格最大池化层去掉下采样的层,以空洞卷积代替
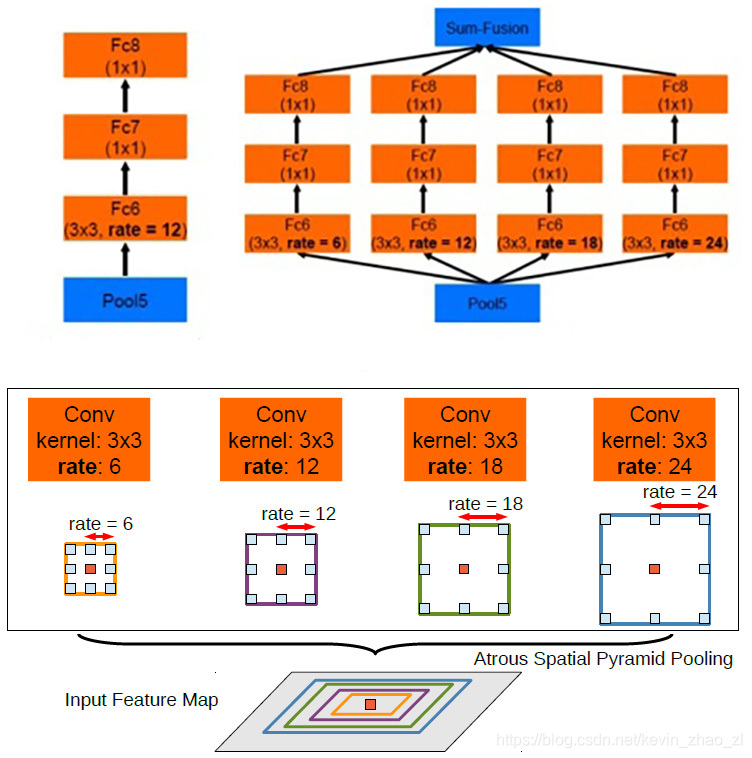
- 空洞卷积空间池化金字塔解决多尺度对象的问题:在给定的出入上以不同采样率的空洞卷积进行采样
- Dense CRF解决边界细化的问题:全连接条件随机场捕捉边界细节特征
4. 具体步骤
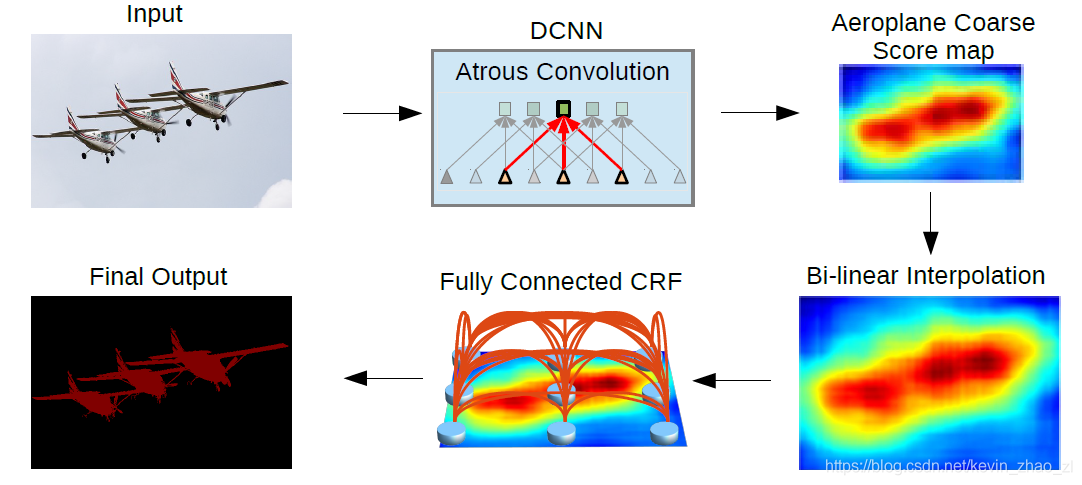
- 调整ImageNet pre-train的ResNet为全卷积结构,结合空洞卷积和ASPP得到粗略结果
- 双线性插值扩大特征图到原图大小
- 全连接条件随机场细化预测结果,输出最终结果
5.模型和方法
5.1 空洞卷积
进行空洞卷积的两个有效的方法:
- 通过插入空洞(零)来隐含地对滤波器进行上采样,或等效稀疏地对输入特征图进行采样。通过向im2col函数(从多通道特征图中提取矢量化块)添加稀疏采样底层特征图实现了这一点
- 用一个等于空洞卷积率 r 等效的因子对输入特征图下采样,对于每一个 的移位,都对其进行去交织以产生 大小的的分辨率映射。然后将标准卷积应用于这些中间特征图,并隔行扫描生成原始图像分辨率。通过将多孔卷积变换为常规卷积,可以使用现成的高度优化的卷积方法。
5.2 ASPP
不同于标准的多尺度特征处理方法中,先对图像进行多个不同尺度的放缩然后采用相同参数进行特征提取之后再融合得到最终的结果,空洞卷积空间池化特征金字塔(Atrous Spatial Pyramid Pooling)对相同的输入进行并行的不同采样率的空洞卷积然后进行特征融合,如下图