论文地址 :Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
论文代码:Github链接
1. 摘要
文章主要的工作是将空间金字塔池化和编解码模块结合,在DeepLabV3的基础上提出DeepLabV3+:使用DeepLabV3作为编码结构,再次基础上增加一个简单有效的解码模块来精细化分割的结果,特别是边界部分。文章还进一步探索Xception的结构,在ASPP和Decoder中都应用了深度可分离卷积,得到一个快速而且健壮的编解码网络。
2. 介绍
语义分割模型中,金字塔池化模块能够在不同分辨率下获取丰富的语义信息而编解码结构则能够捕获比较细节的物体边框。在DeepLabV3中应用了不同空洞率的空洞卷积层并行组成的ASPP模块来捕获多个尺度的特征图,尽管能够将丰富的语义信息编码在最后的特征图中,但是由于池化和带步长卷积的存在,会使得一些关于物体边界的细节信息丢失
这个问题可以通过空洞卷积来减缓,空洞卷积计算代价过大。以ResNet101为例,若output_stride=16,有三个残差块即九个层需要空洞化;若output_stride=8,则有26个残差快即78个层需要空洞化。
但是在编解码结构中不会有如此强度的计算,在此类模型的编码结构中没有特征需要空洞卷积处理,解码结构逐步还原,所以计算更快。而且编解码结构还能获得更加详细的物体边框回复效果,所以论文中将ASPP和编解码结构结合来获取物体多尺度的语义信息并精细化边框,如下图所示:

除了ASPP与编解码结构的结合,模型还应用了深度可分离卷积来简化模型并提速,具体来讲是对Xception进行了一些改进,并将可分离卷积的思想结合空洞卷积形成空洞可分离卷积应用于ASPP和解码模块中。
总的来说,论文的主要贡献在于:
- 新颖的使用DeepLabV3作为编码模块的编解码结构
- 空洞卷积来控制编码结构中特征图尺寸实现精度和速度的均衡
- 应用Xception作为主干网络并在ASPP和解码结构中应用可分离卷积的思想提出空洞可分离卷积
- 在PASCAL VOC 2012数据集上实现了state-of-art 的性能。
3. 方法
涉及的方法有空洞卷积,深度可分离卷积,DeepLabV3作为编码器模块,对应的解码结构,Xception的修改版。
3.1 带有空洞卷积的编解码结构
- 空洞卷积
空洞卷积的引入能够使特征图的分辨率得到控制并且调整滤波器的感受野来捕获多尺度的信息。二维信号中,对于每一个位置 ,有一个输出 和一个滤波器 ,空洞卷积在特征图x上的应用如下所示:
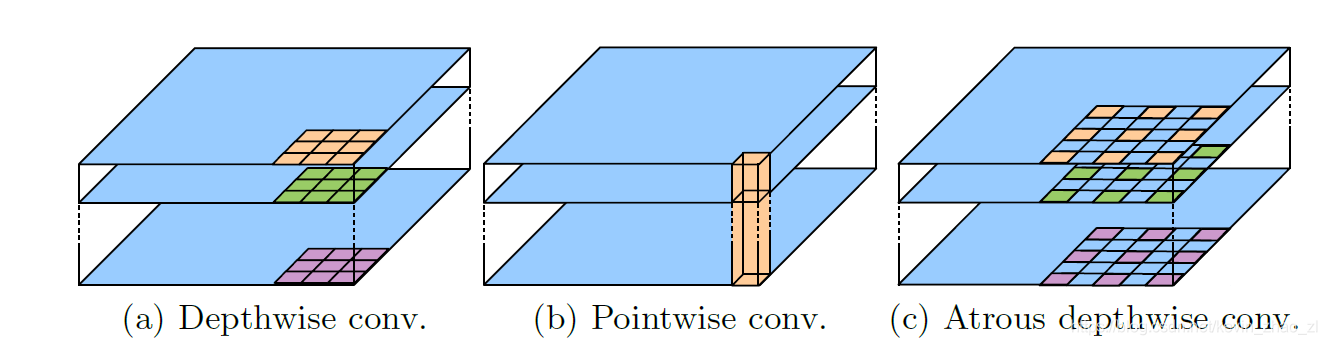
- 深度可分离卷积
深度可分离卷积把标准卷积分解为一个Depthwise Conv和一个Pointwise Conv,其中DW独立地对每个输入通道做空间卷积,PW用于结合DW的输出。将空洞卷积于深度可分离卷积结合可以减少运算量的同时保持不错的效果,结构如下图所示:
- DeepLabV3作为编码模块
对于图像分类任务来说,输出特征图通常是输入图像的三二分之一,即output_stride=32,对于分割任务来说,通常是16或者8,这是通过一处最后的一个block或者两个blocks并应用空洞卷积来实现的。[atrous rate=2,4;output_stride=8]。
对于DeepLabV3来说,它通过应用不同的空洞率的空洞卷积和image-level feature改进了ASPP,我们使用这个结构作为编码结构。这个编码结构的输出使包含256个通道的富语义信息,并且可以通过调整具体的参数得到不同尺寸的输出特征图 - 解码结构
通常来说,DeepLabV3的output_stride=16,然后通过一个16倍的双线性插值来进行上采样,这可以被看作一个简单的解码模块,单并不能很好的恢复分割的细节。文中提出一个解码结构如下图所示:

首先将编码结构的输出双线性插值上采样4倍然后和对应的经过1x1卷积来减少通道数的底层特征图concat,之后应用一个3x3的卷积,之后应用一个4倍的双线性插值上采样来得到最后的输出。实验证明,output_stride=16具有最好的精度和速度的折中。等于8的话精度的提升带来了额外多的计算。
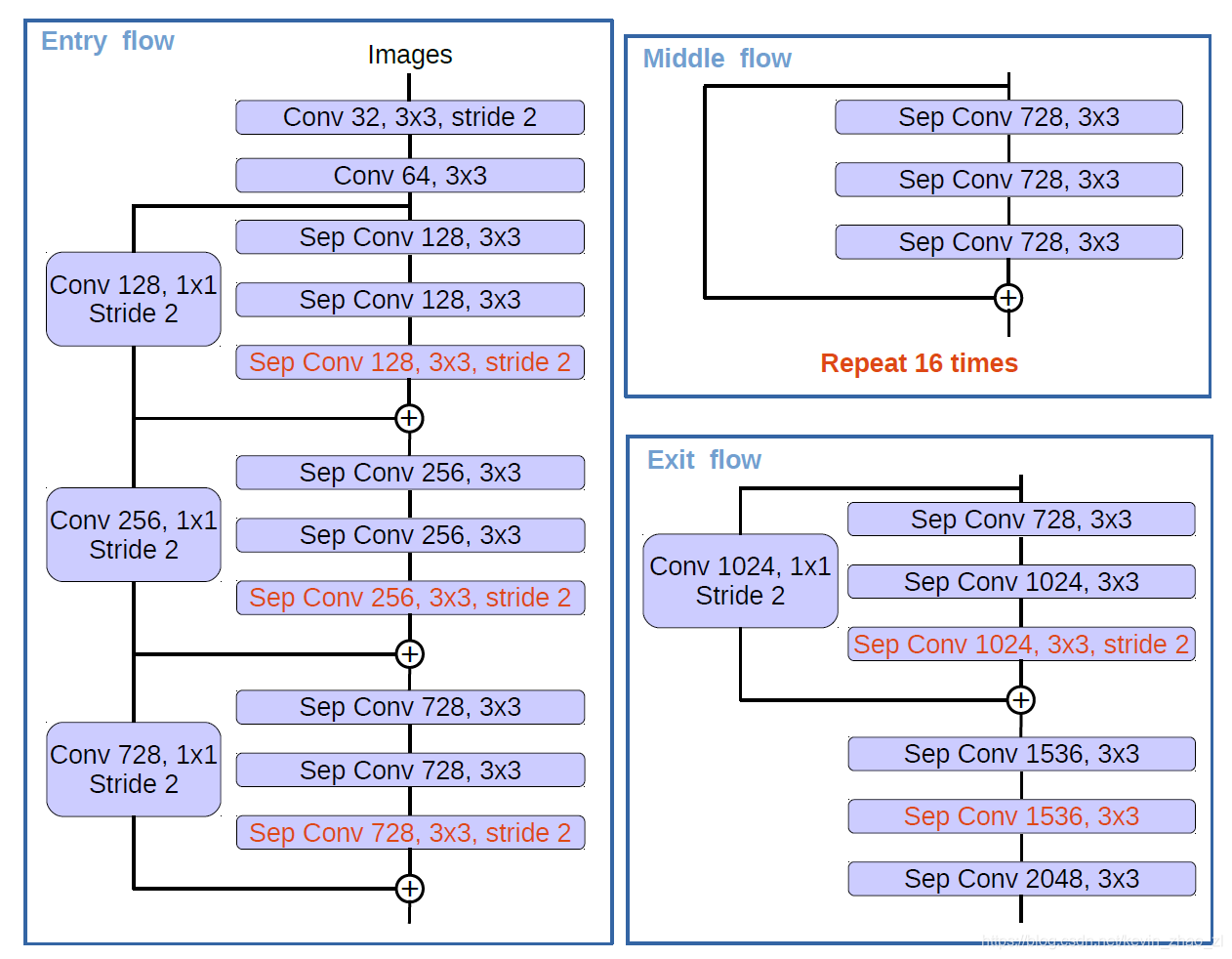
3.2 修改并校准Xception
主要对Xception做了如下修改:
- MSRA类似的改进过的Deeper Xception,即more layers
- 将所有的最大池化操作修改为带步长的深度可分离卷积,以便应用空洞可分离卷积
- 额外的BN层和RELU激活层附加在每一个3x3DW Conv后,这与MobileNet的设计很相似。
最后细节如下图所示:
4.实验
与V3相同的训练参数,具体实验包括:
4.1 Decoder设计的选择
在decoder模块中:
- 1x1 卷积用于减少底层特征图的通道数
- 3x3 卷积用于获取精细的特征图分割结果
- 底层特征图必须要用在编码结构中
不同通道数对结果的影响如下表:

3x3 卷积个数和其滤波器个数对实验结果的影响如下表:
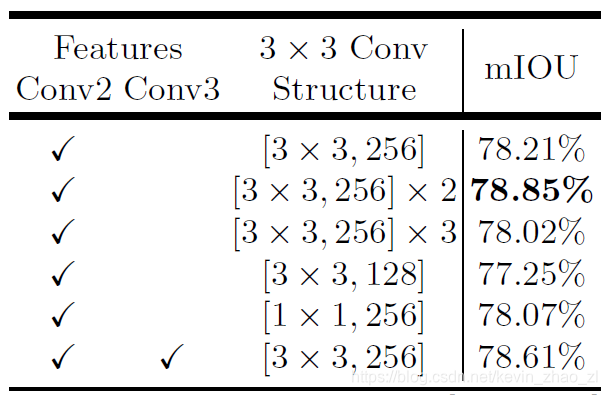
最终采取了这样的解码结构,将经过Conv2的通道减少的特征图与DeepLabV3的特征图做concat后的结果再经过两个[3x3,256]的卷积操作。
4.2 其他实验细节
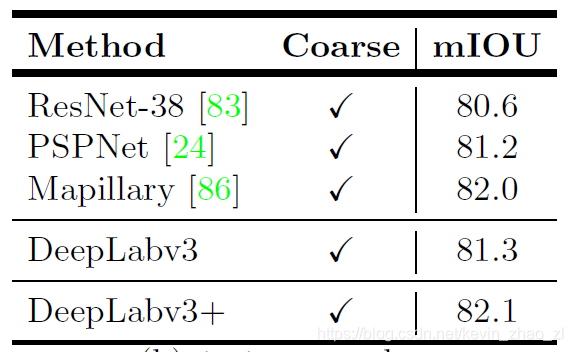
包括ResNet和Xception的对比,Xception作为主干网络后,其他细节的对比,下表是再Pascal VOC 2012的结果:
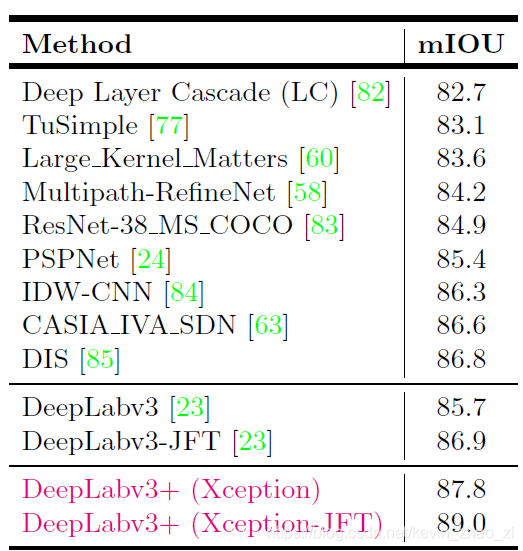
下表是再Citycapes数据集上的实验结果: