版权声明:本文为博主原创文章,未经博主允许不得转载。https://blog.csdn.net/weixin_44474718/article/details/86219792
函数解释
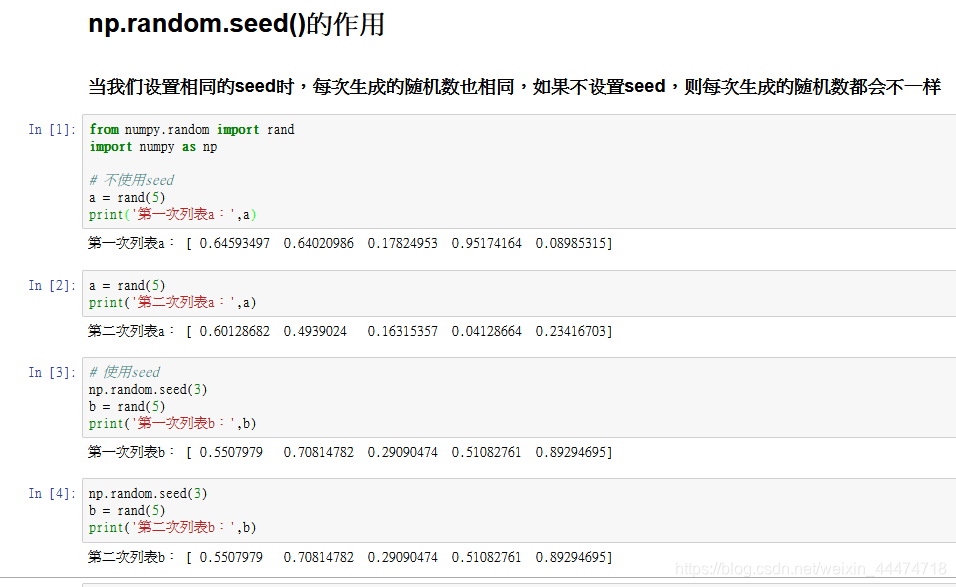
np.random.seed()函数,每次运行代码时设置相同的seed,则每次生成的随机数也相同,如果不设置seed,则每次生成的随机数都会不一样。例如:
本例子:
数据集为8个属性和输出结果一共9列,为二分类问题(糖尿病为1或非糖尿病为0)
输出层(1个输出)
隐藏层(8个神经元)
隐藏层(12个神经元)
可视层(8个输入)
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 设定随机数种子
np.random.seed(7)
# 导入数据
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',')
# 分割输入x和输出Y x = dataset[:, 0 : 8] 中0 : 8为第0列到8-1=7列
x = dataset[:, 0 : 8]
Y = dataset[:, 8]
# 创建模型
model = Sequential()
#relu为激活函数
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
#==***sigmoid为激活函数,二分类一般用这个***==
model.add(Dense(1, activation='sigmoid'))
# 编译模型
#使用有效的梯度下降算法adam作为优化器
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
#epochs 迭代次数 batch_size 批数
model.fit(x=x, y=Y, epochs=150, batch_size=10)
# 评估模型
scores = model.evaluate(x=x, y=Y)
print('\n%s : %.2f%%' % (model.metrics_names[1], scores[1]*100))
激活函数:
sigmoid: 一般用于二分类
sgn: 单层神经网络
relu:多层神经网络,更容易收敛,预测效果好