NiN
全连接层的问题:包含大量的参数。很容易过拟合。
通常是 输 入 通 道 数 × 图 像 尺 寸 × 输 出 尺 度 输入通道数\times 图像尺寸\times 输出尺度 输入通道数×图像尺寸×输出尺度
NiN的思想是:完全不要全连接层;
一个NiN块:

卷积层之后跟两个1x1的卷积,步幅为1,无填充,输出形状和卷积层输出一样。起到了全连接层的作用(按照逐一像素)。
NiN的架构:
- 无全连接层;
- 交替使用NiN块和步幅为2的最大池化层(逐步减小高宽和增大通道数);
- 最后使用全局平均池化层得到输出(输入通道数是类别数);
如果我们要得到1000类的话,最后就有1000个通道,每个做全局平均池化得到这一通道对应类的置信度。
总结:
- NiN块使用卷积层+2个1x1卷积层,后者对每个像素增加了非线性;
- 全局平均池化代替VGG和AlexNet的全连接层,参数个数少,不容易过拟合。

参数用了Alex那一套,不过加了一些1x1的卷积。
GoogleNet
怎么选择最好的超参数?
卷积核、池化方式、通道数?
Inception块:每种卷积都要,最后concatenation(高宽不变,通道数连接)。
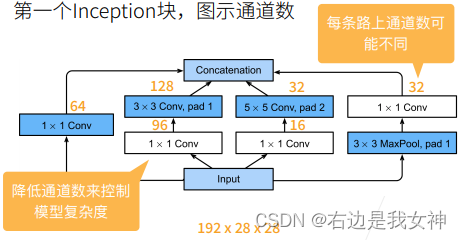
可以看到,白色块的作用都是通过改变通道数来降低模型复杂度(也就是参数量)。蓝色块的作用是抽取信息。
先降后增的设计思路是bottleneck的感觉。
Inception块相比单独的3x3或5x5卷积相比,其有更少的参数个数和计算复杂度。
同时Inception块还增加了其中学习得到的信息的多样性。

Stage1和Stage2和VGG一致。GoogleNet用了很多NiN的思想,大量地使用1x1卷积减少参数量。
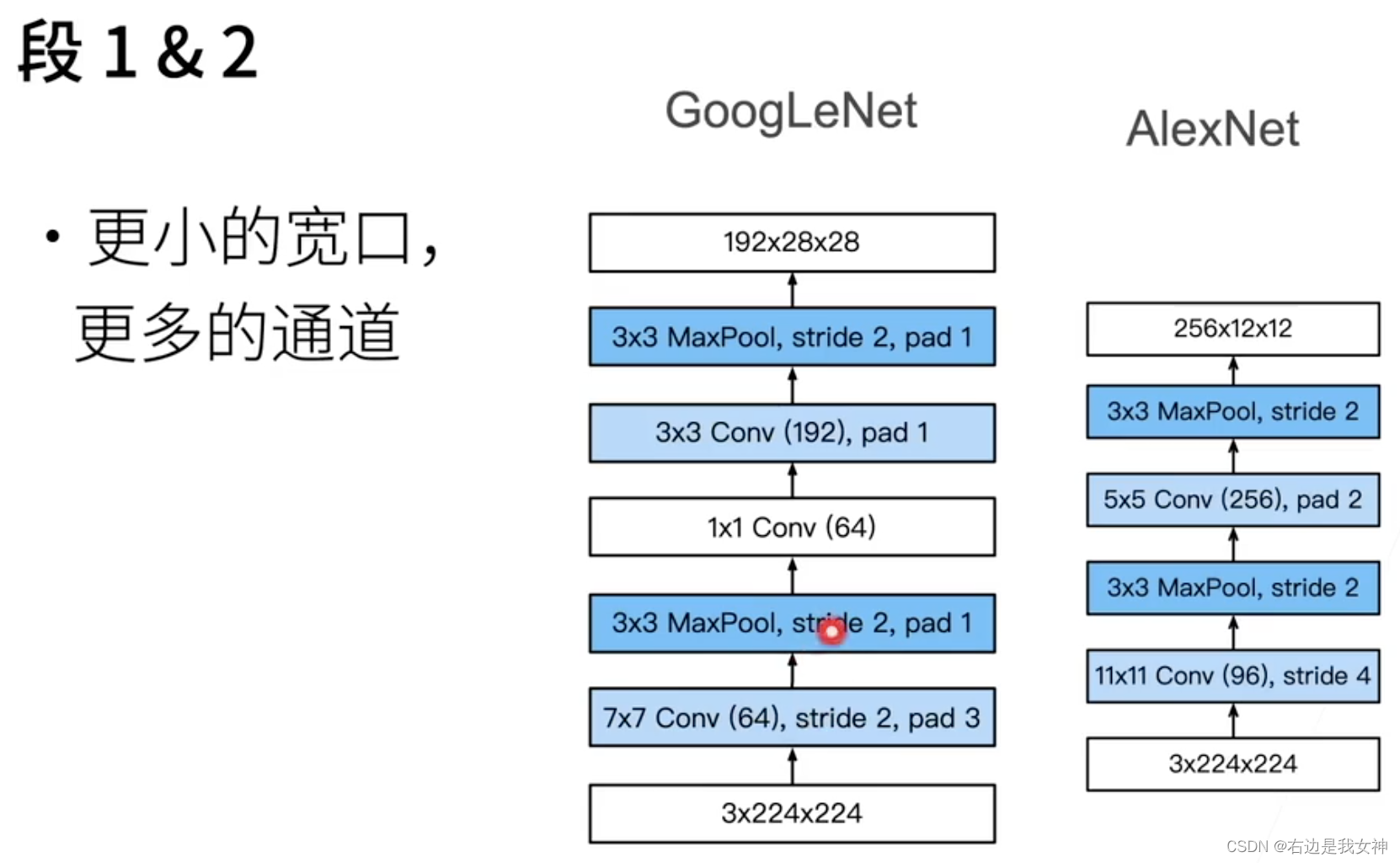
相比于AlexNet,GoogleNet的卷积核是比较小的,这使得空间信息不会被很快压缩,支撑后续通道数增加时的信息学习。
同时,空间信息被压缩,我认为也是为了增加通道数的无奈之举,目的是为了减少参数量。

第三阶段,可以看到通道数还是在增加的,但是每一个Inception块的参数都不一样。值得一提的是,3x3卷积永远是被分配地最多的,这是因为它参数量不大,提取信息的效果也还行。
Inception块后续有很多变种,V2加入了BN、V3修改了卷积尺寸、V4加入了残差连接。