版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012071811/article/details/86225132
主成分分析(Principal Components Analysis, PCA)是一种降维方法。为了更好的解释该算法,首先假设数据集为
{
x
(
i
)
;
i
=
1
,
2
,
…
,
m
}
\{x^{(i)}; i=1,2, \dots, m\}
{ x ( i ) ; i = 1 , 2 , … , m }
x
(
i
)
∈
R
n
x^{(i)} \in \mathbb {R}^n
x ( i ) ∈ R n
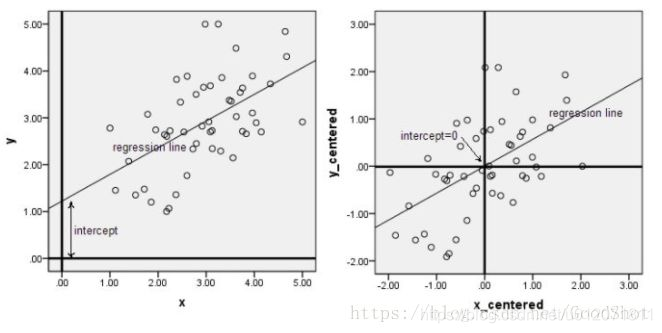
中心化又叫零均值化,中心化(零均值化)后的数据均值为零。下面两幅图是数据做中心化前后的对比,可以看到其实就是一个平移的过程,平移后所有数据的中心是(0, 0)。
数据标准化的目的就是使各个特征都在同一尺度下被衡量。
Z-score 标准化(也叫 0-1 标准化),这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为 0,标准差为 1。Z-score 标准化的公式如下:
x
∗
=
x
−
μ
σ
x^{*} = \frac{x - \mu}{\sigma}
x ∗ = σ x − μ
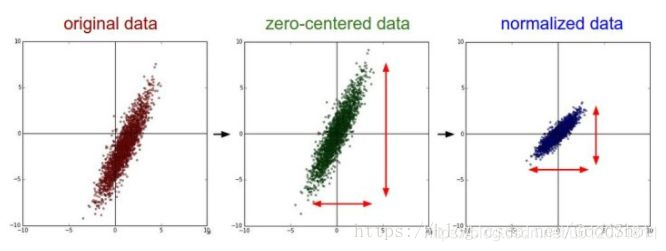
我们可以发现 Z-score 标准化的过程中是包含中心化的。以下图片展示了一组数据进行 Z-score 标准化的过程。左图表示的是原始数据,中间的是中心化后的数据,右图是将中心化后的数据除以标准差,得到的标准化后的数据,可以看出每个维度上的尺度是一致的(红色线段的长度表示尺度)。
想要使用 PCA 算法,需要先对数据做以下处理:
μ
=
1
m
∑
i
=
1
m
x
(
i
)
\mu = \frac{1}{m} \sum_{i=1}^{m} x^{(i)}
μ = m 1 ∑ i = 1 m x ( i )
x
(
i
)
=
x
(
i
)
−
μ
x^{(i)} = x^{(i)} - \mu
x ( i ) = x ( i ) − μ
σ
j
2
=
1
m
∑
i
(
x
j
(
i
)
)
2
\sigma_j^2 = \frac{1}{m} \sum_i(x_j^{(i)})^2
σ j 2 = m 1 ∑ i ( x j ( i ) ) 2
x
j
(
i
)
=
x
j
(
i
)
σ
j
x_j^{(i)} = \frac{x_j^{(i)}}{\sigma_j}
x j ( i ) = σ j x j ( i )
整个过程其实就是 Z-score 标准化的过程。
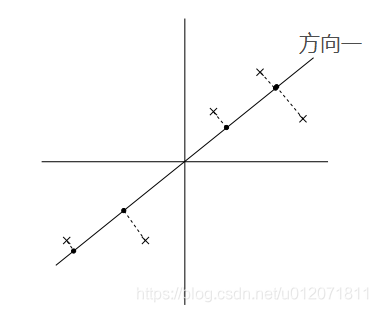
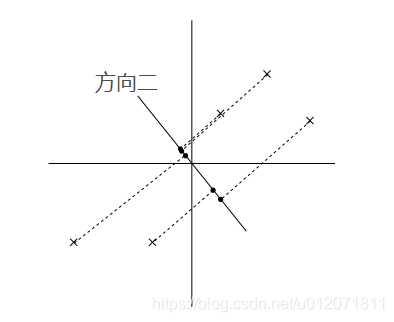
PCA 算法的基本思想就是寻找到数据的主轴方向,我们希望数据在主轴方向上能够被更好的区分开,直观的说就是我们希望数据在主轴上尽量分散,更具体的就是指所有的点在主轴方向的投影点的方差最大。比如在以下两个图中,在方向一上,数据更分散,投影点的方差最大,所以如果从这两个方向上选一个主轴的话,应该选方向一。
在数据已经做了 Z-score 标准化的前提下,数据的均值为 0,其投影点的均值也为 0。
m
a
x
1
m
∑
i
=
1
m
(
x
(
i
)
T
u
−
0
)
2
⇒
m
a
x
1
m
∑
i
=
1
m
μ
T
x
(
i
)
x
(
i
)
T
μ
⇒
m
a
x
μ
T
(
1
m
∑
i
=
1
m
x
(
i
)
x
(
i
)
T
)
μ
max \frac{1}{m} \sum_{i=1}^{m}(x^{(i)^T}u - 0)^2 \\ \Rightarrow max \frac{1}{m} \sum_{i=1}^{m} \mu^T x^{(i)} x^{(i)^T} \mu \\ \Rightarrow max \mu^T \Big( \frac{1}{m} \sum_{i=1}^m x^{(i)} x^{(i)^T} \Big) \mu \\
m a x m 1 i = 1 ∑ m ( x ( i ) T u − 0 ) 2 ⇒ m a x m 1 i = 1 ∑ m μ T x ( i ) x ( i ) T μ ⇒ m a x μ T ( m 1 i = 1 ∑ m x ( i ) x ( i ) T ) μ
(1) 上述第一个式子里的
x
(
i
)
T
μ
x^{(i)^T} \mu
x ( i ) T μ
x
(
i
)
x^{(i)}
x ( i )
μ
\mu
μ
μ
\mu
μ
∥
μ
∥
=
1
\lVert \mu \rVert = 1
∥ μ ∥ = 1 {(i) T} $ 是一个矩阵,并且这个矩阵是对称矩阵(实际上是一个协方差矩阵)。
μ
\mu
μ
μ
\mu
μ
∥
μ
∥
=
1
\lVert \mu \rVert = 1
∥ μ ∥ = 1
l
=
μ
T
(
1
m
∑
i
=
1
m
x
(
i
)
x
(
i
)
T
)
μ
−
λ
(
∥
μ
∥
−
1
)
=
μ
T
Σ
μ
−
λ
(
μ
T
μ
−
1
)
\begin{aligned} l =& \mu^T \Big( \frac{1}{m} \sum_{i=1}^m x^{(i)} x^{(i)^T} \Big) \mu - \lambda (\lVert \mu \rVert - 1)\\ =& \mu^T \Sigma \mu - \lambda(\mu^T \mu - 1) \end{aligned}
l = = μ T ( m 1 i = 1 ∑ m x ( i ) x ( i ) T ) μ − λ ( ∥ μ ∥ − 1 ) μ T Σ μ − λ ( μ T μ − 1 )
μ
\mu
μ
▽
μ
l
=
▽
μ
μ
T
Σ
μ
−
λ
▽
μ
μ
T
μ
=
Σ
μ
−
λ
μ
\begin{aligned} \triangledown_{\mu} l =& \triangledown_{\mu} \mu^T \Sigma \mu - \lambda \triangledown_{\mu} \mu^T \mu \\ =& \Sigma \mu - \lambda \mu \end{aligned}
▽ μ l = = ▽ μ μ T Σ μ − λ ▽ μ μ T μ Σ μ − λ μ
μ
\mu
μ
Σ
\Sigma
Σ
Σ
\Sigma
Σ
{
μ
1
,
μ
2
,
…
,
μ
k
}
\{\mu_1, \mu_2, \dots, \mu_k\}
{ μ 1 , μ 2 , … , μ k }
则可以通过以下公式将原来是 n 维的
x
(
i
)
x^{(i)}
x ( i )
y
(
i
)
y^{(i)}
y ( i )
[
y
1
(
i
)
,
y
2
(
i
)
,
…
,
y
k
(
i
)
]
=
[
u
1
T
x
(
i
)
,
u
2
T
x
(
i
)
,
…
,
u
k
T
x
(
i
)
]
[y_1^{(i)}, y_2^{(i)}, \dots, y_k^{(i)}] = [u_1^T x^{(i)}, u_2^T x^{(i)}, \dots, u_k^T x^{(i)}]
[ y 1 ( i ) , y 2 ( i ) , … , y k ( i ) ] = [ u 1 T x ( i ) , u 2 T x ( i ) , … , u k T x ( i ) ]