【论文阅读】ConvNet Architecture Search for Spatiotemporal Feature Learning
这是一篇和I3D同一时间的论文,论文的作者就是提出C3D网络的那个人,本文也是通过实验探索了更优的3D网络结构,提出了一种Res3D网络模型,该网络比C3D网络的FLOPs小两倍,比C3D网络的参数量小2倍,同时模型的性能也要好于C3D。
前言
本文通过实验来探索最优的3D网络结构,在3D网络结构设计的过程中主要有以下3个难点:
- 3D网络往往都比较大,所以在训练的过程中会非常地花费时间和显存。
- 在2DCNN网络中,有ImageNet这种标准数据集来评测模型性能,但是当时在行为识别领域中,最大的只是UCF101这种数据集(当时还没有kinetics)。
- 在设计网络的过程之中,影响网络性能的因素太多了。
文章做了以下措施来克服上述的难点:
- 为了更快地探索网络结构,文章使用简化的网络(Simplified networks)做相关实验,这种简化的网络训练速度更快。
- 因为当时最大的数据集为UCF101,所以只能在这个数据集上做实验,3D网络很容易在这个数据集上过拟合,为了解决这个问题,文章首先限制不同对比网络之间的参数量是一致的,从而如果一个网络的准确率更高,我们可以排除网络容量的影响,可以认为是网络结构的功劳;其次,如果一种网络结构在UCF101上表现优秀,如果该网络在其他数据集上能够得到相同的结果,我们才认为这种网络结构比其他网络结构更优
正文
基础的Res3D网络结构
因为当时resnet在2D卷积网络中取得了非常好的成绩,所以文章基于resnet设计3D网络结构,首先文章提出了res3D网络,其结构如下表所示:

该网络的输入为 8x112x112,网络移除了最大池化层,将conv3_1,conv4_1,conv5_1的步长都设置为了 2x2x2,从而能够对输入进行时间和空间的降采样。网络的每一个卷积层后都跟着BN层。同时为了能够快速地实验,文章使用简化的网络(Simplified networks)做相关实验,简化网络与该网络相比,输入更改为 4x112x112。
网络结构的探索实验
输入视频帧的最优采样间隔是多少?
文章首先探索了最优的输入视频的采样间隔的问题,分别设置采样间隔为 {1,2,4,8,16,32}。结果如下表所示。

可以看到最优的视频帧采样间隔在2-4之间,间隔太长效果会非常差,文章认为间隔太长的话无法有效地学习输入帧之间的运动信息。从而可以得到结论:对于视频分类来说,在25-30fps的视频中,视频帧的采样间隔在2-4之间能够得到最好的效果
输入视频帧的最优空间分辨率是多少?
因为要保证所有的对比实验中网络的参数量是一致的,所以在探索最优的输入空间分辨率时,对于不同分辨率的输入,仅修改conv1的卷积核的尺寸,其余部分都不变,这样就可以保证所有对照实验中网络的参数量是一致的。文章设置了3种分辨率,分别为 {56x56,112x112,224x224},在输入的预处理过程中,视频帧首先缩放为 64x86,128x171,256x342。然后再随机裁剪出相应的输入分辨率。实验结果如下表所示:
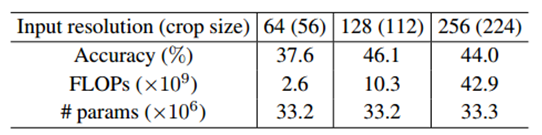
可以看到 将输入首先缩放到 128x171,然后随机裁剪112x112,这种分辨率的输入兼顾准确率和计算效率,是在GPU显存受限下最优的输入分辨率。
网络中使用什么样的卷积方式最好呢?
虽然文章的目的是构建3D卷积网络,但是并不一定表示3D卷积网络中的核全为3D卷积核。所以文章做了以下两个实验探索:
- 混合2D-3D网络形式:文章假设只需要在网络的底层对时间动态进行建模,而在顶层时间运动信息是没有必要的。所以文章从顶层到底层依次替换3D卷积核为2D卷积核,同时为了保证网络的参数量是一致的,将丢失的3D卷积核的时间深度加到2D卷积核的通道深度中。
- 2.5D网络形式:2.5D就是说将3D卷积核拆分成(2D+1D)的形式,文章替换了网络中所有的3D卷积核为(2D+1D)的形式,同时为了保证网络的参数量是相同的,使用2D和1D中间的channel值来平衡,channel值设置为 ,其中 表示channel值, 为输入的通道数, 为输出的通道数, 为卷积核的尺寸。
两种探索实验的结果如下表所示:
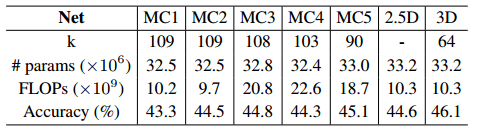
该表中 MC1-MC5表示第一种混合2D-3D网络实验中,从第几层开始往上都是2D卷积核,例如:MC4表示从第4层开始到第5层的卷积核都是2D。从表中可以看到:所有的卷积核都使用3D卷积核可以很好地提升网络的性能。
插一句嘴:[1][2]中也有这种相似的探索实验,这3篇论文的结论都存在差异,感觉没有理论支撑,存靠实验探索还是不行啊。
网络的最优深度是多少?
为了探索网络最优的深度,文章设置了不同深度的网络,分别为{10,16,18,26,34}。同时为了保证各对照网络的参数量相同,通过更改每一个网络卷积层中blocks的数量以及blocks内卷积核的个数来平衡,各个深度网络结构的设置如下表所示(如果没看懂,可以去原文中看Table 14,表太大我就没贴):

实验结果如下表所示:
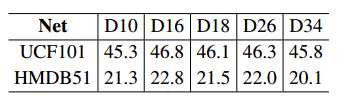
虽然18层的网络结果要比16层和26层网络的结果要低一些,但是考虑到18层网络的计算效率更高,参数量更小,两者兼顾,文章认为:18层的网络为最优的,其兼顾准确率、计算复杂度以及网络容量
最终的Res3D网络结构
通过上边的探索性实验,文章最终确定了整个Res3D的网络结构。

该网络的输入采样间隔为2,输入的分辨率为112x112,网络的深度为18。该Res3D网络与之前的C3D相比,准确率更高,计算效率高2倍,网络容量小2倍。
训练细节
数据集中一个视频随机地裁剪出5个2S的视频段,视频帧首先被缩放为128x171,然后随机地裁剪8x112x112作为输入,视频帧的采样间隔为2。使用SGD训练,batchsize设为40,学习率初始化为0.01,每250k次迭代学习率除以2,在第3M次迭代时停止。
探索性实验
卷积核的可视化
文章对conv1中的64个卷积核进行了可视化,同时加入了2D resnet核的对照,实验结果如下图所示:

上图中上侧为64个3D卷积核可视化后的结果,下图为64个2D卷积核可视化的结果,可以看出:
- 学习的3D核其响应区域随着时间连续,所以3D卷积核可以捕获视频中的时间运动信息。
- 3D核中包含了2D核的appearance信息(我自己看着响应很多都是对角点和色彩的响应),所以3D核可以同时学习视频中的空间和时间信息。
[1] Tran, Du, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. “A Closer Look at Spatiotemporal Convolutions for Action Recognition.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6450-6459. 2018.
[2] Xie, Saining, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. “Rethinking spatiotemporal feature learning for video understanding.” arXiv preprint arXiv:1712.04851 (2017).