这是Du Tran在Learning Spatiotemporal Features with 3D Convolutional Networks之后发表的续篇,相当于C3D的第二个版本,C3D-resnet.我个人觉得这篇文章除了主要探讨C3D-resnet以外,更重要的是对CNN卷积结构在时空特征表现上的一个深入探讨。大部分工作还是基于UCF-101,而且从头训练,很利于在硬件条件有限的情况下,对算法进行讨论。
首先给出代码: https://github.com/facebook/C3D/tree/master/C3D-v1.1
再看一下升级后的效果图:
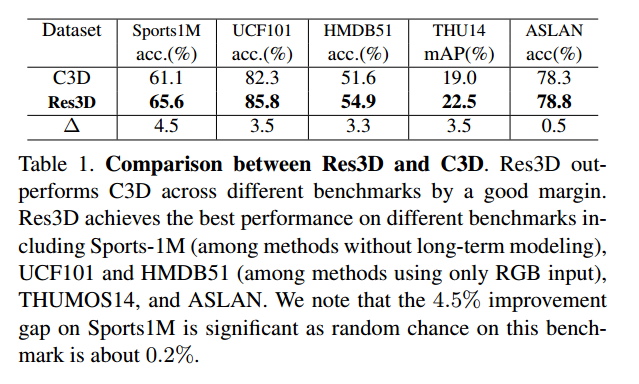
这是相较于C3D来说,已经有了明显的提高。 接下来我们看一下3D Residual Networks的结构 !

这是一个标准的8×112×112的input的结构。
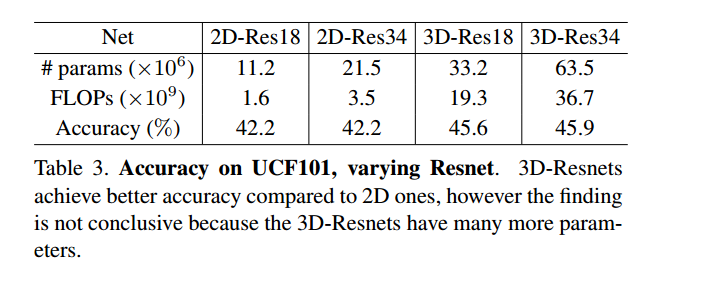
可以看到它的效果相比于2D-CNN有了提高,但是同时也增加了参数和浮点运算。 为了接下来研究方便,作者使用了一个很方便的小trick: 他简化了网络输入,把8×112×112换成4×112×112,只需要把最后一个卷积层conv5_1的stride换成1*2*2即可,也就是时序上的stride=1. 然后作者讨论了帧采样率{1, 2, 4, 8, 16, 32},这里帧采样率就是输入帧时序上的stride(采样间隔),在最小帧采样率为1,输入为4的情况下,4帧大概是1/8s,按照上述采样率,最大32的话,相当于稀疏采样,用4帧段视频表达了128帧的长视频(大概4.5-5s).

可以看到,采样率是2或者4的时候比较好,说明过于稀疏也没用,1的话太稠密冗余,也没有意义。
作者还比较了不同分辨率的影响:
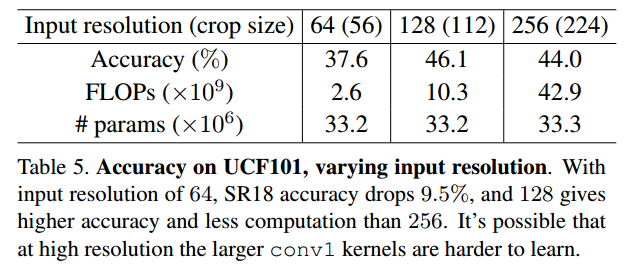
这也说明了,分辨率不一定是越大越好。
接下来作者讨论了2D-CNN和3D-CNN的混合模型:
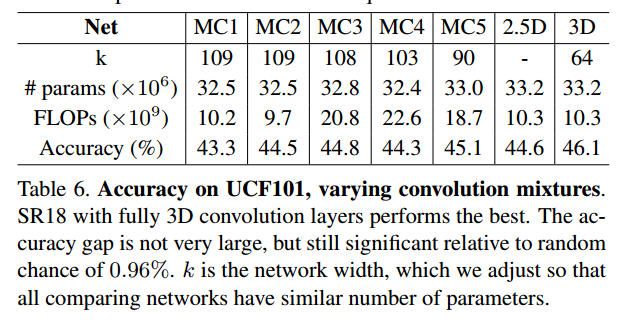
然而证明效果不佳。
接下来这个探讨我觉得非常可惜:
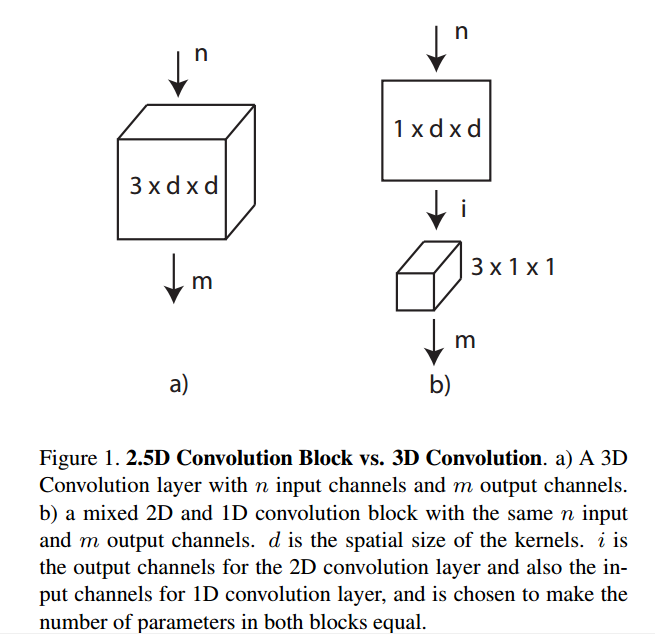
这个2.5D-CNN的想法我觉得本来很好,但是作者做出来的效果也不好,不过准确率没有提高就算了,参数量和浮点运算量也还是那么大,令人费解。 因为令人惊奇的是MSRA有一篇文章实现了伪3D卷积,效果不错,不仅准确率高,参数量和浮点运算量也低,值得关注。 Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks 接下来,作者讨论了在参数量和浮点运算量差不多的情况下,网络深度的影响,发现也没什么作用。
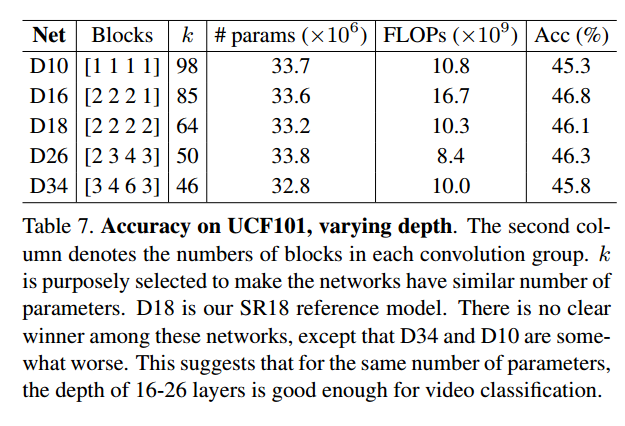
其中,k是输出卷积核的通道数,俗称网络宽度,用来控制参数量和浮点运算次数。 之后,作者还做了一个很有意义的比较:
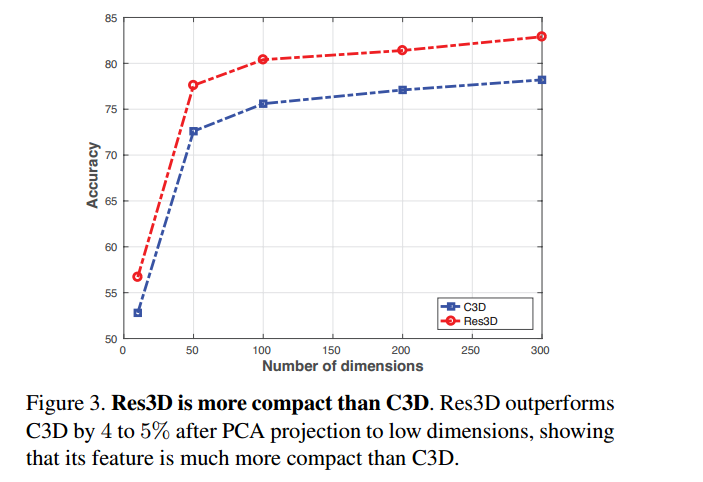
这张图的意思是,把C3D和C3D-Resnet的特征同时用PCA降维处理后,在低维情况下进行了比较,发现它的效果好。这个还是比较有实际意义的,因为应用上不可能有高维特征,把它降维之后,才方便产品落地。 最后,给出整体的网络框架,大家会发现和2D-CNN的Resnet类似。
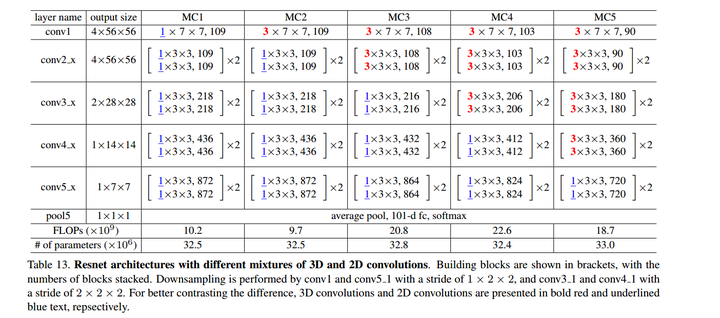
这是混合的2D-CNN和3D-CNN的Resnet.
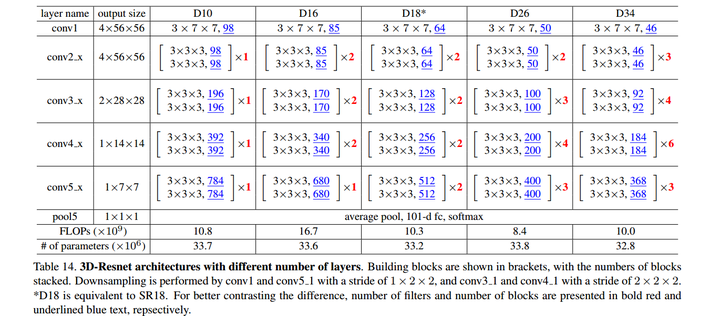
这是不同深度的3D-CNN的Resnet. 总结: 虽然这篇升级版的C3D不一定是state of art,但是我最大的收获是从作者的思路中学习到如何讨论科研问题和改进模型结构的方法,这一点很重要。所以我很欣赏这篇文章,接地气,硬件条件有限的情况下也可以实现,从头训练讨论问题,排除了依靠大数据迁移学习,提升效果而忽略算法本事的问题。(PS:大概是贫穷限制了我的想象!)