一、NAS
论文地址:https://arxiv.org/abs/1611.01578
代码连接:https://github.com/tensorflow/models
ICLR2017由Googlebrain推出的论文
二、Motivation for architecture search:
•Designing neural network architectures is hard
•Lots of human efforts go into tuning them
•There is not a lot of intuition into how to design them well
•Can we try and learn good architectures automatically?
总结来说就是手工设计网络代价较大,并且并无直觉指导设计,希望能够自动生成网络结构。
三、Related work:
(1)超参数优化,尽管取得了成功,但这些方法仍然有限,因为他们只能从固定长度的空间搜索模型。换句话说,要求他们生成一个规定网络结构和连接性的可变长度配置是很困难的。在实践中,如果这些方法提供了良好的初始模型这些方法往往会更好地工作。有贝叶斯优化方法可以用来搜索非固定尺寸的建筑物,但与本文提出的方法相比,它们不那么一般和灵活。
注:神经网络架构并不位于欧式空间,因为架构所包含的层级数和参数数量并不确定,很难将参数化为固定长度的向量。传统的高斯过程(GP)在传统上是用于欧式空间的,在神经网络搜索中可以考虑使用贝叶斯优化(后续此系列会对论文:Auto-keras : Efficient Neural Architecture Search with Network Morphism做分析,其中便使用了贝叶斯优化来引导神经网络的态射,在ENAS的基础上降低计算成本,引入神经网络核(edit-distance)、tree/graph structure采集函数优化算法)
(2)现代神经进化算法,例如Wierstra等人(2005年); Floreano等人(2008);另一方面,斯坦利等人(2009)在组成新模型方面更加灵活,然而它们在大规模时是无法实用的。它们的局限性在于它们是基于搜索的方法,因此它们很慢或需要许多启发式才能运行良好。
(3)神经架构搜索,与程序合成和归纳编程有一些相似之处,它们从例子中搜索程序(Summers,1977; Biermann,1978)。在机器学习中,概率性程序诱导已成功用于许多环境中,比如学习简单问答(Liang et al。,2010; Neelakantan et al。,2015; Andreas et al。,2016),对数字列表(Reed &de Freitas,2015年),并以极少数例子进行学习(Lake等,2015)。
神经架构搜索中的控制器是自动回归的,这意味着它预测一次一次的超参数,并以先前的预测为条件。这个想法是从decoderin端对端序列借鉴序列学习(Sutskever等,2014)。与序列学习序列不同,我们的方法优化了一个不可区分的度量标准,这是子网络的准确性。因此它类似于神经机器翻译中的BLEU优化工作(Ran-zato等,2015; Shen等,2016)。与这些方法不同,我们的方法直接从没有任何监督引导的信号中学习。
与我们的工作相关的还有学习学习或元学习的想法(Thrun&Pratt,2012),这是一个使用在一项任务中学到的信息来改进未来任务的通用框架。更密切相关的是使用神经网络学习另一网络的梯度下降更新(Andrychowicz et al。,2016)以及使用强化学习为另一网络找到更新策略的想法(Li&Malik,2016)。
meta-learning也是一个大坑。。。待我慢慢挖。。。哭唧唧
四、reinforcement learning 背景介绍:
强化学习:是通过和环境交互获得反馈,再根据反馈调整动作以期望总奖励最大化。强化学习强调如何基于环境而行动,以取得最大化的预期利益。
loss & reward
强化学习与监督学习的loss训练方法不同,不是用误差而是用reward(奖励机制)来进行更新。
强化学习算法:
value -based:q learning;sersa;DQN
policy-based:policy gradient(直接输出行为)
Policy gradient 不像 Value-based 方法 (Q learning,Sarsa),但也要接受环境信息 (observation),不同的是要输出不是 action 的 value, 而是具体的那一个 action,这样 policy gradient 就跳过了 value 这个阶段,这种反向传递的目的是让这次被选中的行为更有可能在下次发生。

强化学习的目标函数:
其中E[……]表示在策略πθ条件下一轮交互(0到t步)中的累计奖励的期望值
五、Methods:
这篇文章通过一个controller在搜索空间(search space)中得到一个网络结构(child network),然后用这个网络结构在数据集上训练得到准确率,再将这个准确率回传给controller,controller继续优化得到另一个网络结构,如此反复进行直到得到最佳的结果。

通过一个controllerRNN在搜索空间(search space)中得到一个网络结构(论文中称为child network),然后用这个网络结构在数据集上训练,在验证集上测试得到准确率R,再将这个准确率回传给controller,controller继续优化得到另一个网络结构,如此反复进行直到得到最佳的结果,整个过程称为Neural Architecture Search。
(1)如何生成模型:
Question:为什么用RNN作为controller?
Our work is based on the observation that the structure and connectivity of a neural network can be typically specified by a variable-length string. It is therefore possible to use a recurrent network – the controller – to generate such string.
通过观察发现目前的神经网络的结构和内部连接是一个可变的长度string来指定的,所以可以使用RNN去产生如此的可变长度的网络结构。
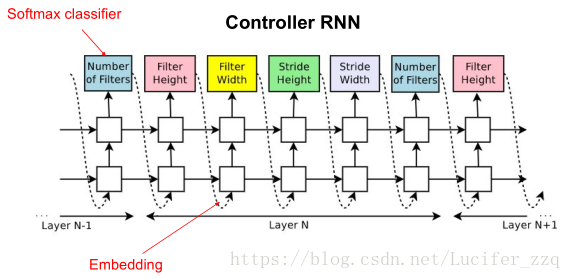
图中预测的网络只包含conv层,使用RNN去预测生成conv层的超参数,这些超参数如图2所示,包括:卷积核的Height、卷积核的Width、卷积核滑动stride的Height、卷积核滑动stride的Width、卷积核数量。RNN中每一个softmax预测的输出作为下一个的输入。 Controller生成一个网络结构后,用训练数据进行训练直到收敛,然后在验证集上进行测试得到一个准确率。论文中提到生成网络结构的终止条件是当网络层数达到一个值时就会停止。
(2)Training with reinforce
将RNN控制器预测一系列输出对应为一系列的actions:a1-T去设计network。
生成的网络在验证集上测试得到一个准确率R,将R作为reward信号并使用policy gradient的方法去更新此RNN(参数θc)。
目标函数:

更新θc求导: 
近似:

m:是控制器在训练过程中一个batch中不同神经网络结构的数量,
T:是控制器设计网络结构中预测的超参数的数量,
Rk:是第k个神经网络训练完后在验证集上的测试准确率。
上述为无偏估计,为了降低方差引入b(bias):
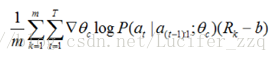

RNN输出会经过softmax来选着architecture的参数。