AmoebaNet
这篇文章还是出自Google Brain,是对他们之前发表在CVPR2018的论文《Learning Transferable Architectures for Scalable Image Recognition》的进一步改进,而这篇文章则发表在了AAAI 2019。原文可见Regularized Evolution for Image Classifier Architecture Search。
摘要
尽管进化算法已被反复应用于神经网络拓扑,但由此发现的图像分类器仍不如人工模型。本文开发了一种图像分类器–AmoebaNet-A,该分类器首次超过了手工设计。为此作者通过引入年龄特性来改进锦标赛选择进化算法,使之更适合年轻的基因型(也就是在算法中引入年龄的概念,并在进化时倾向于选择更年轻的模型)。尺寸匹配的情况下,AmoebaNet-A具有与通过更复杂的NAS方法发现的SOTA的ImageNet模型相当的准确性。缩放到更大尺寸后可以实现SOTA的ImageNet精度。在与一个著名的强化学习算法的对照中,作者证明了在相同的硬件条件下,进化可以更快地获得结果,特别是在搜索的早期阶段。当可用的计算资源较少时这就很关键了,所以说进化是有效发现高质量架构的简单方法。
1. 引言
一般而言,大多数最先进的图像分类架构都是手工设计的。为了加快这一进程,研究人员研究了自动化方法也就是NAS。现在进化算法/遗传规划产生的体系结构还没有达到人类专家直接设计的体系结构的精度。
那为了能超越手工设计,本文对标准的进化过程做了两个增改:
- 首先,对已有的锦标赛选择进化算法提出了一个改进,作者称之为老化进化或正则进化。作者建议将每个基因型与年龄联系起来,并偏向选择更年轻的基因型。
- 其次,实现了最简单的一组突变,这些突变将允许在NASNet搜索空间中进化。此搜索空间将卷积神经网络体系结构与小的有向图相关联,其中顶点表示隐藏状态,标记的边缘表示常见的网络操作(例如卷积或池化层)。这里的变异规则只是通过随机地将边的原点重新连接到不同的顶点,并通过随机地重新标记边,从而覆盖整个搜索空间来改变结构。
此外,本文还提出了针对图像分类任务的架构搜索算法的第一个比较案例研究,并将证明进化可以用一种更简单的方法获得类似的结果。实验证明进化搜索比RL和随机搜索更快,特别是在早期阶段,这在实验由于计算资源限制而无法长时间运行时非常重要。
2. 相关工作
- 强化学习
- 进化算法:代际算法(generational algorithms)如NEAT。实时算法(Real-time algorithms)如rtNEAT、锦标赛选择(tournament selection)(与代际算法不同的是,这些算法根据模型的性能丢弃模型,或者根本不丢弃,从而导致模型在种群中存活很长时间,甚至在整个实验中都是如此)。作者证明在保持其效率的同时,老化进化的有限生命期比直接的锦标赛选择能提供更好的结果。
- 降低计算成本:渐进式复杂度搜索(progressive-complexity search)、超网(hypernet)、精度预测、热启动、ensembling 、并行化、reward shaping 和早停止(early stopping)或Net2Net变换。
- 年龄(age)的概念:本文中的年龄被分配给个体(而不是基因),并且只用于跟踪种群中年龄最大的个体,从而允许在每个周期中移除这些最老的个体(保持恒定的种群规模)。
3. 方法
3.1 搜索空间
这里搜索空间沿用前一篇文章的NASNet搜索空间(如图1所示),具体可以看上一篇博客的介绍。
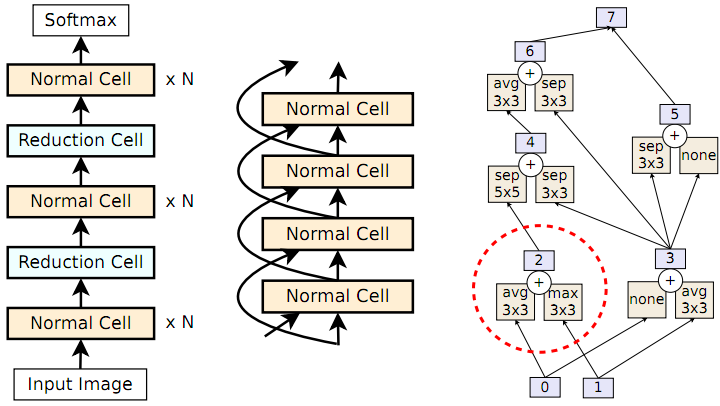
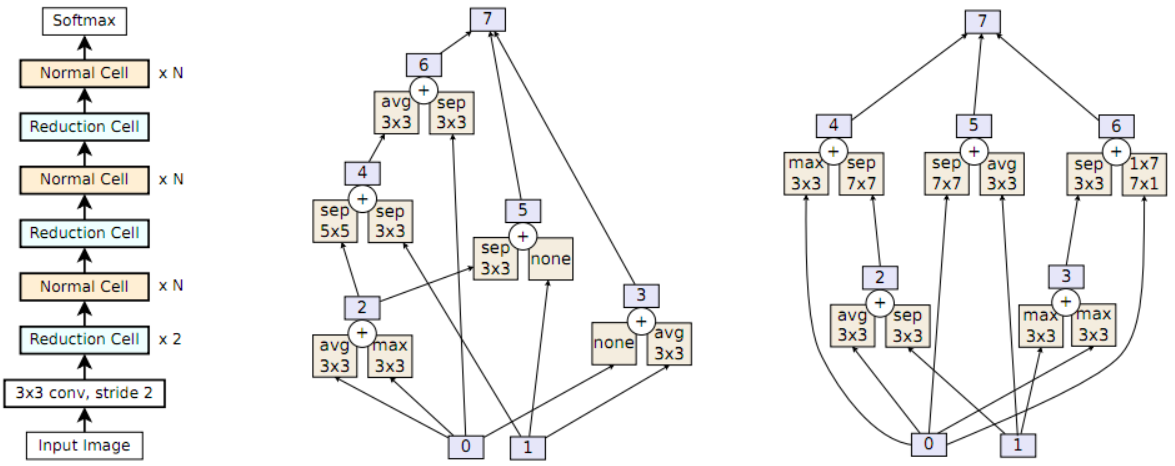
正如上一篇文章中也提到的一样,实际NAS需要搜索的就是两种cell的结构。而这两种cell即Normal Cell和Reduction Cell必须符合以下构造。两个cell的输入张量分别是隐藏状态“0”和“1”,然后通过成对组合构造更多的隐藏状态。图1描述了一个成对组合(图1最右子图的虚线圆圈内)。它将一个操作应用于一个现有的隐藏状态,再将另一个操作应用于另一个现有的隐藏状态,然后将两个结果加起来生成一个新的隐藏状态。这里的操作从一组固定的常见CNN操作中获得,如卷积和池化。允许在组合中重复隐藏状态或操作。举个例子,在图1(右)的cell示例中,第一个成对组合将 平均池化操作应用于隐藏状态0,将 最大池化操作应用于隐藏状态1,以生成隐藏状态2。下一个成对组合现在可以从隐藏状态0、1和2中选择以生成隐藏状态3(在图1中是选择了0和1),依次类推。在获得五对组合之后,任何未使用的隐藏状态(图1中就是隐藏状态5和6)被concat起来形成cell的输出(这里就是隐藏状态7)。
这里网络架构被事先指定,模型仍然有两个自由参数可用于改变其大小(及其精度):每个堆栈的Normal Cell数(N)和卷积运算的输出滤波器数(F)。N和F是手动确定的。
3.2 进化算法
如下所示是文中所用的进化算法。在整个实验过程中,它保持了P个训练模型的规模。种群由具有随机结构的模型初始化(算法1中的“while |population|”)。所有符合上述的搜索空间的架构都是可能的,而且是同样可能的。

此后,进化改进了周期中的初始种群(算法1中的“ while |history|”)。在每一个周期,它从种群中随机抽样S个模型。选择该样本中具有最高验证精度的模型作为parent,一个新的架构child则由parent通过一个称为变异的转换来构建。变异导致架构的简单和随机修改。一旦构建了child,它就被训练、评估并添加到种群中。上述的这个过程就叫做锦标赛选择(tournament selection)。
在锦标赛选择中,通常将种群规模固定在初始值P上。这通常在每个周期内通过一个额外的步骤来完成:丢弃(或杀死)随机的S个样本中最坏的模型。作者把这个称作“非老化进化”。本文则提出了一种新的方法:杀死种群中最老的模型,即从种群中移除训练最早的模型(算法1中的“remove dead
from left of population”),这有利于种群中较新的模型。作者将这种方法称为老化进化。在NAS的背景下,老化进化允许更多地探索搜索空间,而不是像非老化进化那样过早地关注于好的模型。

直觉上,可以认为突变提供了探索(exploration),而parent提供了开发(exploitation)。参数S控制了开发的侵略性:S=1减少为一种随机搜索,2 S P导致不同贪婪程度的进化。
通过对现有模型应用变异,以随机方式转换其架构来构造新模型。为了浏览上述的NASNet搜索空间,本文使用了两个主要的突变,分别称为隐藏状态突变和op突变。 第三个突变,即恒等变换(identity),也是可能的。 在每个循环中仅应用其中一个突变,并在它们之间随机选择。
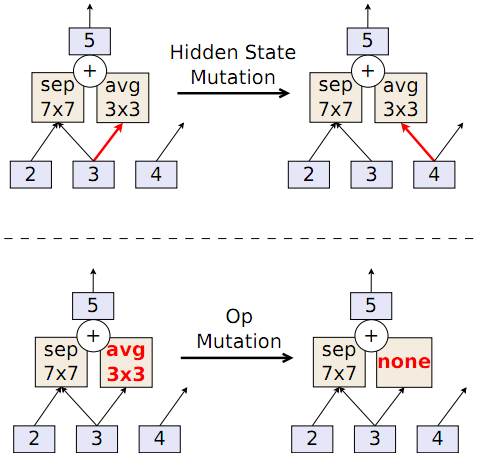
隐藏状态突变首先随机选择是修改Normal Cell还是Reduction Cell。 一旦选择了某一个cell,突变就会随机地均匀挑选出五个成对组合之一。 一旦选择了某个成对组合,就随机地均匀选择其中的两个元素之一。 所选元素具有一种隐藏状态,然后用cell内的另一个隐藏状态替换掉,但要遵守不成环的限制(以保持卷积网络的前馈性质)。 图2(顶部)是一个示例。
op突变的行为类似于隐藏状态突变,比如选择两个cell中的一个、五个成对组合中的一个以及成对的两个元素中的一个。不同之处在于它修改了操作而不是隐藏状态。它通过从固定的操作列表中随机选择一个操作来替换现有的操作。图2(底部)是一个示例。
3.3 基线算法
- RL算法:也就是前一篇文章NASNet中用到的算法。
- 随机搜索RS:每个模型都是随机构造的,这样搜索空间中的所有模型都与进化算法中的初始种群一样具有相同的可能性。也就是说,RS实验中的模型不是通过对已有模型进行变异来构造的,从而使新模型独立于已有模型。
3.4 实验设置
- 所有方法都使用相同的代码进行网络构建、训练和评估。
- 实验总是在CIFAR-10数据集上进行搜索。
- 先搜索小模型,再放大N和F得到大模型并训练更长时间以跟baseline比较
4. 方法细节
主要是复现实验的一些细节,有需要的自己看论文去吧:-)。
5. 结果
5.1 与RL和RS基线的比较
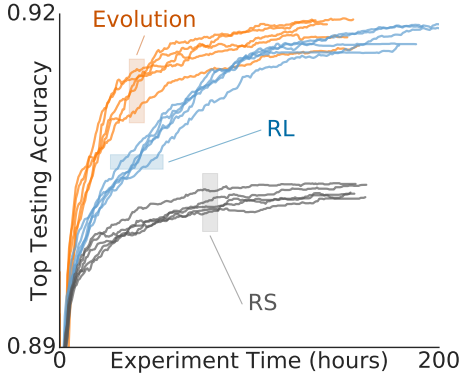
图3显示了随着实验的进行,模型的准确性的变化,很明显进化算法在早期阶段产生了更准确的模型,这在资源受限的情况下可能变得很重要,因为在这种情况下,可能必须尽早停止实验。在后期,进化产生的模型具有与RL相似的精度。而且,进化和RL都优于RS。
NAS是在小模型上进行的,目的是为了更快训练。然后再使用之前说的模型增强技巧将搜索发现的体系结构转化为一个更大尺寸的、精确的模型。
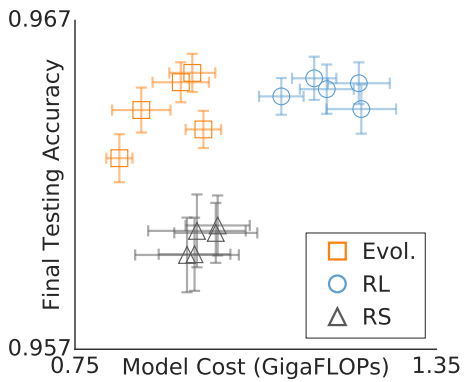
图4比较了三组实验中增强后的最好模型,图中显示了测试准确性和模型计算成本(以FLOPs表示,越低越好)。进化算法得到的体系结构比用RS获得的体系结构具有更高的精度(和相似的FLOPs),而与RL获得的体系结构相比具有更低的FLOPs(和相似的精度)。参数量显示出与FLOPs相似的行为。总的来说,进化算法在这个图中占据了理想的相对位置(即越靠左上越好)。
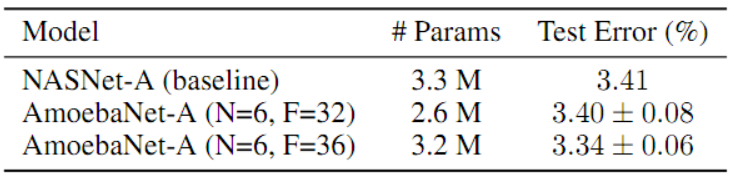
接着作者又选择验证精度最高的进化架构,并将其称为AmoebaNet-A(如图5所示)。 表1中,与NASNet-A比较了测试准确性,可以看到AmoebaNet-A精度略高(匹配模型尺寸时),或者尺寸略小一些(匹配模型精度时)。
5.2 ImageNet上的结果
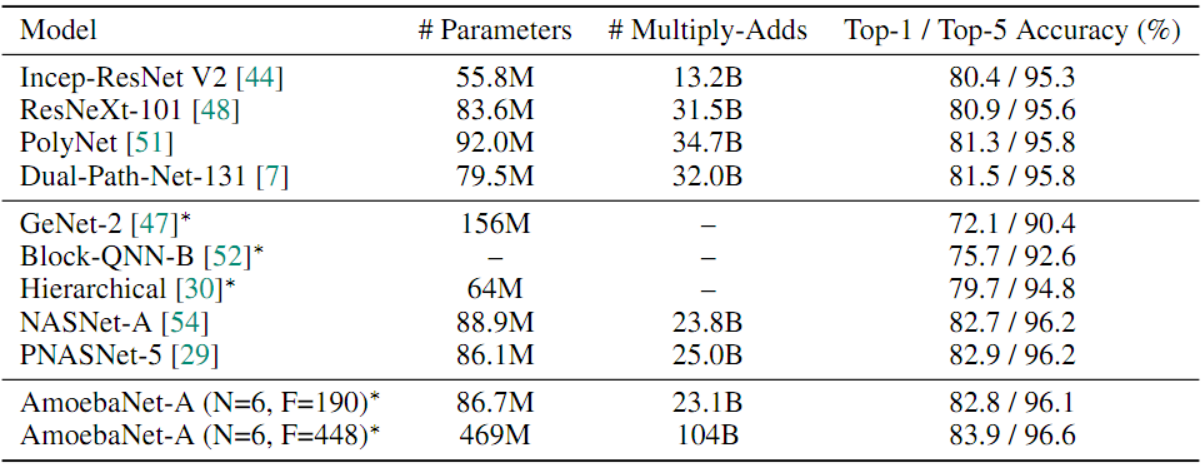
再次使用在CIFAR-10上验证准确性最高的AmoebaNet-A,迁移到ImageNet上进行重新训练,可以看到在相同参数量下,AmoebaNet-A的性能与NASNet-A相当。进化后的AmoebaNet-A(底行)以相似的模型尺寸达到了SOTA,并在更大的尺寸上获得了一个新的SOTA。
6. 讨论
这一节主要是讨论一些未来可能的研究方向。
6.1 结果范围
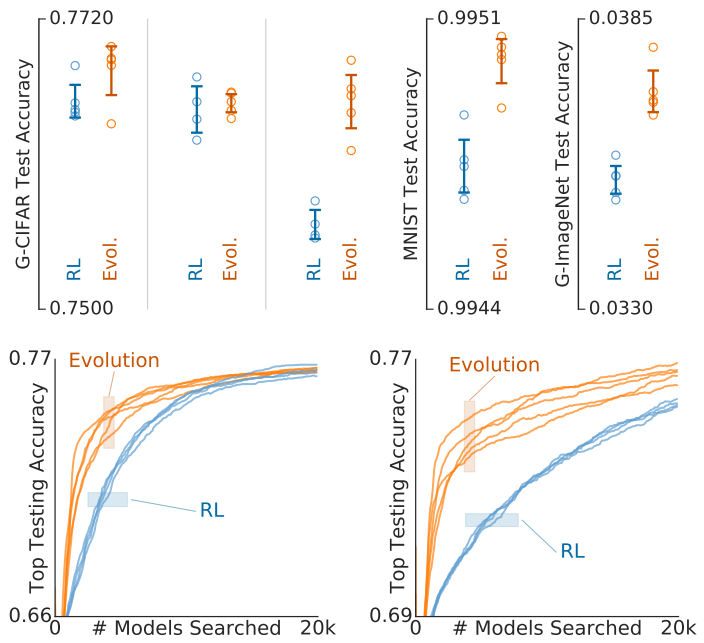
本文中的发现可能受限于使用的搜索空间和数据集。因此未来工作的一个方向就是扩展到更多的搜索空间、数据集和任务,或扩展到使用更多的算法。如图6所示是在三种搜索空间、三个数据集上对比进化算法和RL,可以看到进化算法在各种情况下都要得到跟RL相比相近或更好的精度。
6.2 算法速度
当探索更大的空间时,算法速度可能更为重要,因为在更大的空间中,达到最优可能需要比可用资源更多的计算资源。在图6右下角可以看到进化的速度要快得多,因此未来的工作可以探索在更大的空间上进行进化算法。
6.3 模型速度
图4证明了进化得到的模型更快,这可能是因为异步进化会在训练固定epoch时减少FLOPs从而间接地优化速度:更快的模型因为可以更快地“重现”,所以即使一开始精度不如其他更慢的模型,后来也可以做得更好。这可能可以是未来工作的一个主题。另外,本文只用了异步算法(与世代进化方法相对)来确保高资源利用率。 未来的工作可能会探索异步和世代算法在模型准确性方面的比较。
6.4 老化进化的好处
在其他小计算资源的实验中,老化演化似乎是有利的,如图7所示。这些实验是在CPU而不是GPU上进行的,并使用CIFAR-10的灰度版本来减少计算需求。

6.5 老化进化和正则化
因为模型有时可能仅仅靠运气就能达到高精度,在非老化进化中,这样的幸运模型可能在种群中甚至在整个实验中持续很长时间。因此,一个这样的幸运模型可以产生许多子模型,使得算法专注于此,减少了探索。
另一方面,在老化进化下,所有模型的寿命都很短,因此种群更新频繁,导致更多的多样性和探索性。在老化进化中,因为模型很快就会消亡,所以一个架构能在种群中长期存在的唯一方法就是一代又一代地从父代传给子代。每次继承架构时,都必须对其进行重新训练。如果它在重新训练时产生了一个不准确的模型,那么这个模型就不会被进化所选择,架构也会从种群中消失。一个架构要在种群中长期存在,唯一的办法就是反复进行良好的再训练。换言之,老化只能通过继承重新训练良好的架构来改善种群。(相比之下,非老化进化可以通过积累体系结构/模型来改善种群,而这些体系结构/模型在它们第一次训练时是幸运的)。也就是说,老化进化不得不关注架构而不是模型。换而言之,老化会在进化过程中引入额外的信息:架构应该很好地重新训练。这一附加信息防止了对训练噪声的过度拟合,使其成为广义数学意义上的正则化形式。
进一步验证这个推测可能是未来的工作之一,注意理论结果也可能有助于此问题。
6.6 老化进化的简单性
进化算法的一个值得注意的特点是其简单性。通过设计,变异的应用会导致随机变化。因此,构建新体系结构的过程是完全随机的,而进化不同于随机搜索的是,只有好的模型被选择进行变异。随着时间的推移,这种选择倾向于提升种群。从这个意义上说,进化就是“随机搜索加选择”。概括地说,该过程可以简略地描述:“保持N个模型的种群并循环进行:在每个循环中,对S个随机模型中的最佳模型进行复制变异,并杀死该种群中最老的模型”。 最后,进化也很简单,因为它只有很少的元参数,其中大多数不需要调整(比如本文的实验就只需要调整2个元参数)。相反,RL的优化就需要调整更多的元参数。当然,通过仔细的调整,RL有可能可以产生比进化算法更好的模型,但这种调整可能需要跑许多实验,成本更高。如果运行很长时间,随机搜索也有可能产生同样好的模型,但这将是非常昂贵的。
6.7 解释架构搜索
未来工作的另一个重要方向是分析架构搜索实验(无论使用何种算法),试图发现新的神经网络设计模式。例如,作者发现在其所有实验中,具有高输出顶点扇入(进入输出顶点的边数)的架构往往是受欢迎的。实验也证明随着扇入值的增加,准确度增加。发现更广泛的模式可能需要为此目的专门设计搜索空间。
6.8 额外的AmoebaNets
说了一下AmoebaNet-B/C/D怎么来的。
7. 总结
- 本文出了老化进化,是锦标赛选择的一种变体,其基因型会根据年龄而消亡,从而有利于年轻的基因型。 这在标准锦标赛选择上有所改善,同时仍允许通过异步种群更新大规模地提高效率。还实现了简单的变异,从而允许将进化应用于流行的NASNet搜索空间。
- 进化具有更快的搜索速度,并且在稀缺资源/早期停止的状态下脱颖而出。 进化算法使用更简单的方法在最终模型质量上也与RL相匹敌。
- 开发了AmoebaNet-A。 在ImageNet上,它是超越手工设计的第一个进化模型。 尺寸匹配的情况下,AmoebaNet-A的准确性可与其他架构搜索方法发现的顶级图像分类器相媲美。 大尺寸的情况下,它实现了新的SOTA。
个人看法
本文主要就是将前一篇论文用的强化学习改成进化算法,并模仿自然种群中的老龄化自然规律,引入年龄这个属性形成老化进化算法,并通过实验证明确实效果更好了。但是,还是用450GPU跑了7天,依旧劝退平民玩家。下面依然会再看一下继续提高搜索速度的论文。
