之前学习的过程中,一直以为归一化和标准化效果差不多,老师说让用哪种方法就用哪种方法就行,这可能就是一个经验问题。但是最近在群里讨论,发现这两个方法对数据的分布影响不同,因此搜集了一些资料,做点简单的整理。
参考:【1】https://en.wikipedia.org/wiki/Normalization_(statistics)
【2】https://en.wikipedia.org/wiki/Feature_scaling
【3】https://www.zhihu.com/question/20467170
【4】https://blog.csdn.net/qq_23617681/article/details/51469778
【6】https://blog.csdn.net/pipisorry/article/details/52247379
【7】https://www.cnblogs.com/qingyunzong/p/7592517.html
【8】http://www.cnblogs.com/chaosimple/p/4153167.html
【9】http://www.cnblogs.com/zhaokui/p/5112287.html
【10】https://blog.csdn.net/zenghaitao0128/article/details/78361038
根据维基百科解释,统计学中的规范化(Normalization)可以具有一系列含义。在最简单的情况中,评级的标准化(normalization of ratings)意味着通常在平均之前将在不同尺度上测量的值调整到概念上的共同尺度。在更复杂的情况下,归一化可以指更复杂的调整,目的是使调整值的整个概率分布对齐。在教育评估中的得分标准化(normalization of scores)的例子下,可能有意将分布与正态分布对齐。概率分布归一化的另一种方法是分位数归一化(quantile normalization),其中不同度量的分位数被对齐。
在统计学的另一种用法中,归一化是指创建统计的移位和缩放版本,其意图是这些归一化值允许以消除某些总影响的影响的方式比较不同数据集的相应归一化值,如在一个异常的时间序列( anomaly time series)。某些类型的规范化仅涉及重新缩放,以获得相对于某个大小变量的值。关于测量尺度,这样的比例使仅使比率测量有意义 (其中的测量比率是有意义的),而不是间隔测量(interval measurements)(其中仅距离是有意义的,但不是比)。 In theoretical statistics, parametric normalization can often lead to pivotal quantities – functions whose sampling distribution does not depend on the parameters – and to ancillary statistics – pivotal quantities that can be computed from observations, without knowing parameters.(这句话怎么翻译怎么别扭,决定不翻译了)。
举个例子

关于 特征缩放(Feature scaling),
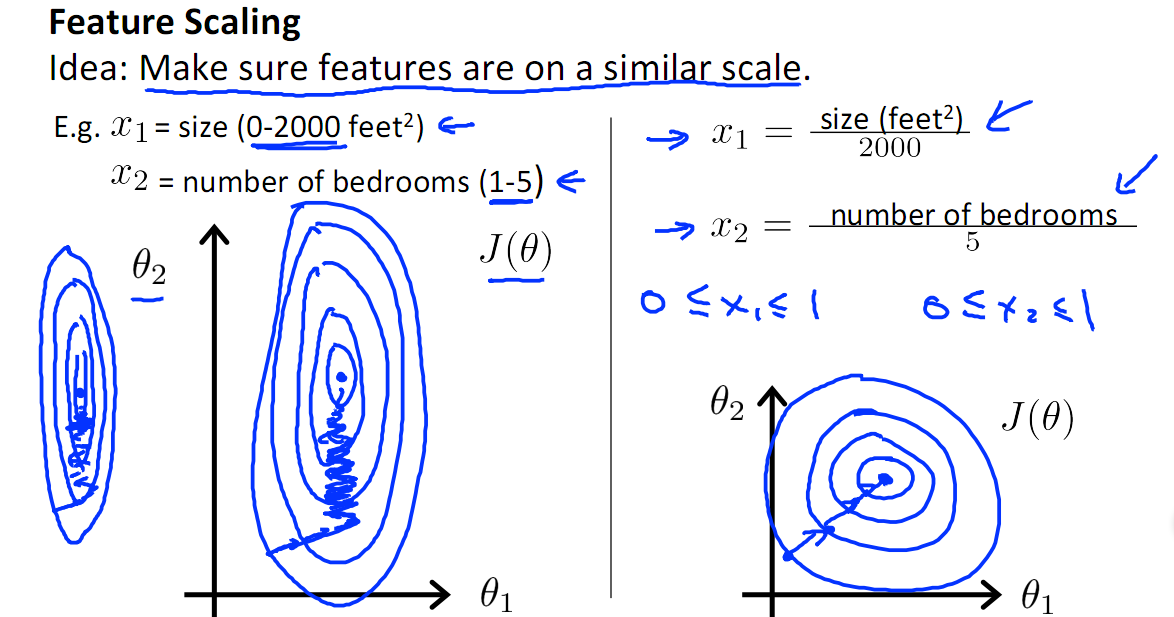
由于原始数据的值范围变化很大,在一些机器学习算法中,如果没有标准化,目标函数将无法正常工作。例如,大多数分类器按欧几里德距离计算两点之间的距离。如果其中一个要素具有宽范围的值,则距离将受此特定要素的约束。因此,应对所有特征的范围进行归一化,以使每个特征大致与最终距离成比例。应用特征缩放的另一个原因是梯度下降与特征缩放比没有它时收敛得快得多,如下图所示,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)
"标准化"和"归一化"这两个中文词要指代四种Feature scaling(特征缩放)方法(以下直接从维基百科搬运过来):
1.Rescaling (min-max normalization)
Also known as min-max scaling or min-max normalization, is the simplest method and consists in rescaling the range of features to scale the range in [0, 1] or [−1, 1]. Selecting the target range depends on the nature of the data. The general formula is given as:

where 

2.Mean normalization

where
3.Standardization
In machine learning, we can handle various types of data, e.g. audio signals and pixel values for image data, and this data can include multiple dimensions. Feature standardization makes the values of each feature in the data have zero-mean (when subtracting the mean in the numerator) and unit-variance. This method is widely used for normalization in many machine learning algorithms (e.g., support vector machines, logistic regression, and artificial neural networks) . The general method of calculation is to determine the distribution mean and standard deviation for each feature. Next we subtract the mean from each feature. Then we divide the values (mean is already subtracted) of each feature by its standard deviation.

Where 

4.Scaling to unit length
Another option that is widely used in machine-learning is to scale the components of a feature vector such that the complete vector has length one. This usually means dividing each component by the Euclidean length of the vector:

In some applications (e.g. Histogram features) it can be more practical to use the L1 norm (i.e. Manhattan Distance, City-Block Length or Taxicab Geometry) of the feature vector. This is especially important if in the following learning steps the Scalar Metric is used as a distance measure.
在知乎上看到有人放了几种规范化后的分布图,感觉比较直观:



从以上几个图,可以明显看出,归一化确实没有对分布改变,而标准化确实对分布改变了。在参考【9】中,博主对归一化、标准化是什么,带来什么变化、怎么用进行了较为详细的介绍,并有一些公式推导,感兴趣可以看看。
最后,来说下这两种方法什么时候用。参考【6】中介绍了机器学习中的算法需要/不需要归一化的模型,
(1)需要归一化的模型:
有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM(距离分界面远的也拉近了,支持向量变多?)。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。
有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression(因为θ的大小本来就自学习出不同的feature的重要性吧?)。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛(模型结果不精确)。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
有些模型/优化方法的效果会强烈地依赖于特征是否归一化,如LogisticReg,SVM,NeuralNetwork,SGD等。
(2)不需要归一化的模型:
(0/1取值的特征通常不需要归一化,归一化会破坏它的稀疏性。)
有些模型则不受归一化影响,如DecisionTree。
ICA好像不需要归一化(因为独立成分如果归一化了就不独立了?)。
基于平方损失的最小二乘法OLS不需要归一化。
另外,在参考【10】中提到如下,
1)最大最小标准化(Min-Max Normalization)
a). 本归一化方法又称为离差标准化,使结果值映射到[0 ,1]之间,转换函数如下:
![]()
b). 本归一化方法比较适用在数值比较集中的情况;
c). 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
d). 应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
2)Z-score标准化方法
a). 数据处理后符合标准正态分布,即均值为0,标准差为1,其转化函数为:
![]()
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
b). 本方法要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕;
c). 应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
3)非线性归一化
a). 本归一化方法经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。
b). 该方法包括 log,正切等,需要根据数据分布的情况,决定非线性函数的曲线:
---log对数函数转换方法
y = log10(x),即以10为底的对数转换函数,对应的归一化方法为:x' = log10(x) /log10(max),其中max表示样本数据的最大
值,并且所有样本数据均要大于等于1.
---atan反正切函数转换方法
利用反正切函数可以实现数据的归一化,即
x' = atan(x)*(2/pi)
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上.
---L2范数归一化方法
L2范数归一化就是特征向量中每个元素均除以向量的L2范数:

1)概率模型不需要归一化,因为这种模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率;
2)SVM、线性回归之类的最优化问题需要归一化,是否归一化主要在于是否关心变量取值;
3)神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是为了弱化某些变量的值较大而对模型产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmod激活函数要好些,因为tanh双曲正切函数的取值[-1,1]之间,均值为0.
4)在K近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微。