一、标准化(normalization)
公式为:(X-X_mean)/X_std
将数据按其属性(每列)减去其均值,除以其方差,最后得到的结果是对每个属性/每列来说所有的数据都聚集在0附近,方差值为1。计算时对每个属性/每列分别进行。
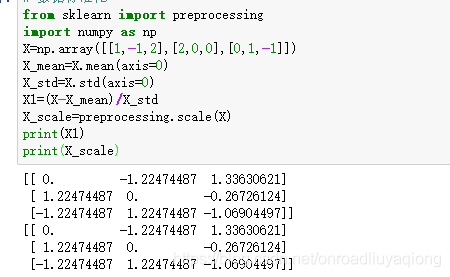
方法一:使用sklearn.preprocessing.scale()函数
说明:x_mean(axis=0)计算X每个特征的平均值
x_std(axis=0)计算X每个特征的方差
preprocessing.scale(x)直接标准化X
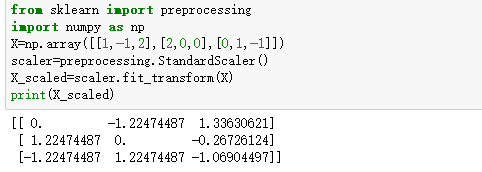
方法二:sklearn.preprocessing.StanderScale类
二、归一化
归一化的好处:提升模型收敛速度,提高模型精度,防止模型梯度爆炸
常用的归一化方法有:
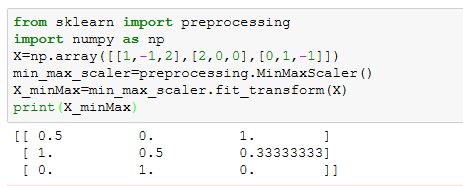
min_max标准化:(X-min)/(max-min),该方法的缺点是当有新数据加入时就要重新定义最大值与最小值。
0_1标准化即zero_mean:(x-均值)/方差,经过处理的数据符合方差为0、标准差为1的正态分布,SPSS默认方法。该方法适用于属性A的最大值与最小值未知或有超出取值范围的离群数据的情况,该种方法要求原始数据近似于高斯分布,所以效果会很糟糕。
log转化:log(X)/log(max),要求所有数据都大于等于1。
atan函数转化:atan(x) *2/π
Decimal scaling小数定标标准化:移动小数点的位置进行标准化
如:
三、正则化
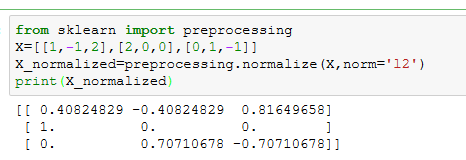
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1)。该方法是文本分析和聚类分析中经常使用的向量空间模型的基础,如果要使用二次型或其他方法计算两个样本之间的相似性,这种方法会很有用。
方法一:使用sklearn.preprocessing.normalize()函数
方法二:使用sklearn.preprocessing.StanderScaler类

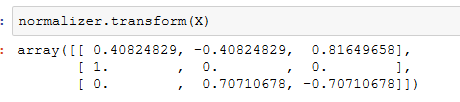
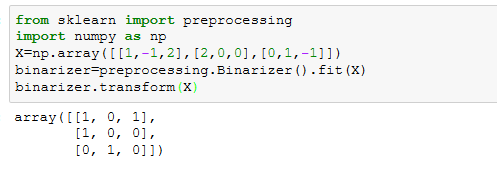
四、二值化(Binarization)
特征的二值化主要是为了将数据特征转化为boolean变量,可以利用sklearn.preprocessing.Binarization来实现。
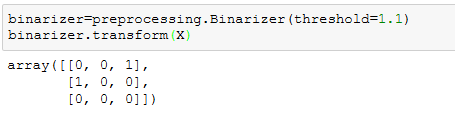
Binarizer也可以设置一个阈值,结果数据值大于阈值的为1,小于阈值的为0
五、缺失值处理
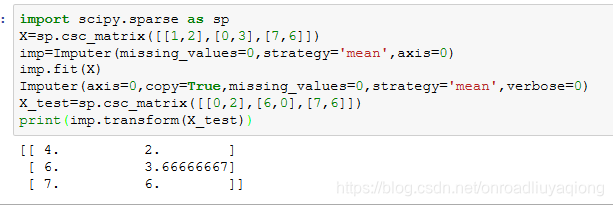
sklearn中的imputer类提供了一些基本的方法来处理缺失值,如均值,中位数或缺失值所在列中频繁出现的数来替换。
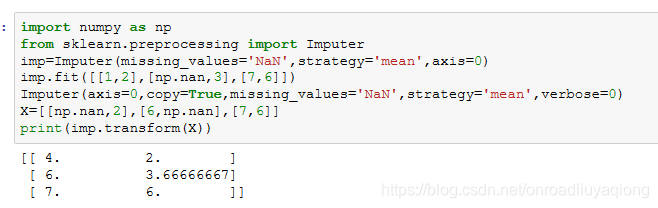
Imputer也支持稀疏矩阵
在矩阵中,为0的数目远远大于非0的数目且非0数据分布没有规律,则称为是稀疏矩阵;反之,若非0数据占据大多数,则为稠密矩阵。
参考文章:
https://blog.csdn.net/ruthywei/article/details/80980746
https://blog.csdn.net/qq_36330643/article/details/78300288