参考:
https://zhuanlan.zhihu.com/p/46377151
https://zhuanlan.zhihu.com/p/29957294
记录下几个ML的数据处理方法
归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。
常见的映射范围有 [0, 1] 和 [-1, 1] ,最常见的归一化方法就是 Min-Max 归一化:

标准化就是将数据缩放到以0为中心,标准差为1
标准化后的特征形式服从正态分布,这样学习权重参数更容易。此外,标准化后的数据保持异常值中的有用信息,使得算法对异常值不太敏感,这一点归一化就无法保证。

正则化是用来引入模型复杂度的惩罚项,防止模型过拟合的方法.
正则项是对现在损失函数的惩罚项,它鼓励权重参数小一点的值,换句话说,正则项是惩罚的大权重参数.
正则化的作用是选择经验风险与模型复杂度同时较小的模型。
常见的有正则项有 L1 正则 和 L2 正则 以及 Dropout ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。


此外,记录下tensorflow和pytorch的normalize函数
torch.nn.functional.normalize(input, p=2, dim=1, eps=1e-12, out=None)
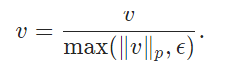
本质上就是按照某个维度计算范数,p表示计算p范数(等于2就是2范数),dim计算范数的维度(这里为1,一般就是通道数那个维度)
参考:https://blog.csdn.net/u013066730/article/details/95208287
tf.nn.l2_normalize(x, dim, epsilon=1e-12, name=None)
上式:
x为输入的向量;
dim为l2范化的维数,dim取值为0或0或1;
epsilon的范化的最小值边界;
