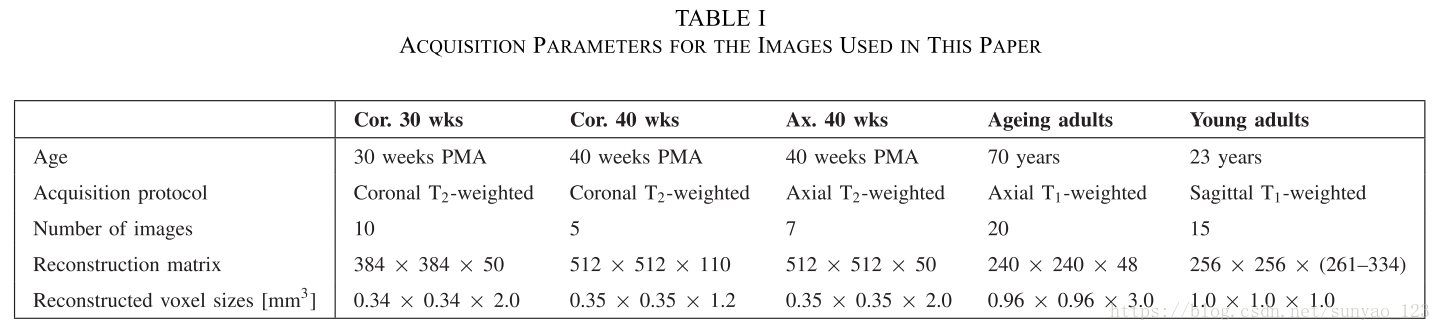
一,数据:

二,方法:
使用不同patch size大小的原因:大的patch包含空间信息,可以定位到这个像素位于图像中的位置(使用大的kernel);小的patch提供局部相邻像素的细节信息(使用小的kernel)。
每类训练数量相同,防止数据不平衡。
为了提供更多的数据,网络训练的每个周期的数据是不同的,每个周期重新提取训练数据。(由于每个训练周期之间提取数据,这样回增加寻来你时间,我们在训练之前就提取好所有数据,随机打乱)。
使用ReLu激活函数,在全连接层使用Drop-out。使用RMSprop进行优化。损失函数使用交叉熵。
三,网络:
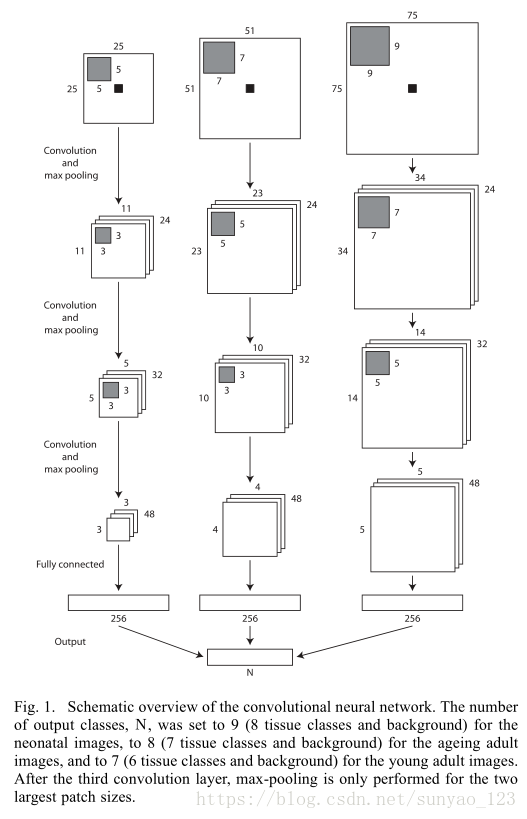
输入大小是奇数,可以使得要判断的像素位于patch的中央。只有第3次卷积最小的patch没有进行maxpooling。
由于maxpooling不能完整的覆盖奇数大小的图像,所以每次池化之前对maxpooling的输入进行镜像。
每条路径通过各自的第一个全连接层(256)后,连接在一起。最后通过全连接输出最终类别个数。
通过实验,发现每个周期使用50000个训练样本效果比25000个样本效果好。
四,预处理
1.偏移场矫正(bias corrected)[45]。去头颅(BET,46),产生mask。训练和测试时,只使用mask内的数据。在mask内的像素值被映射到0~1023。
五,实验
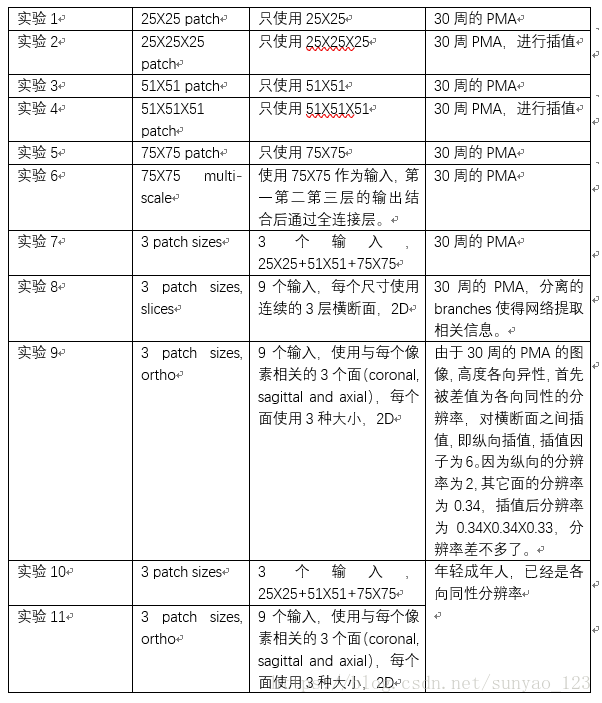
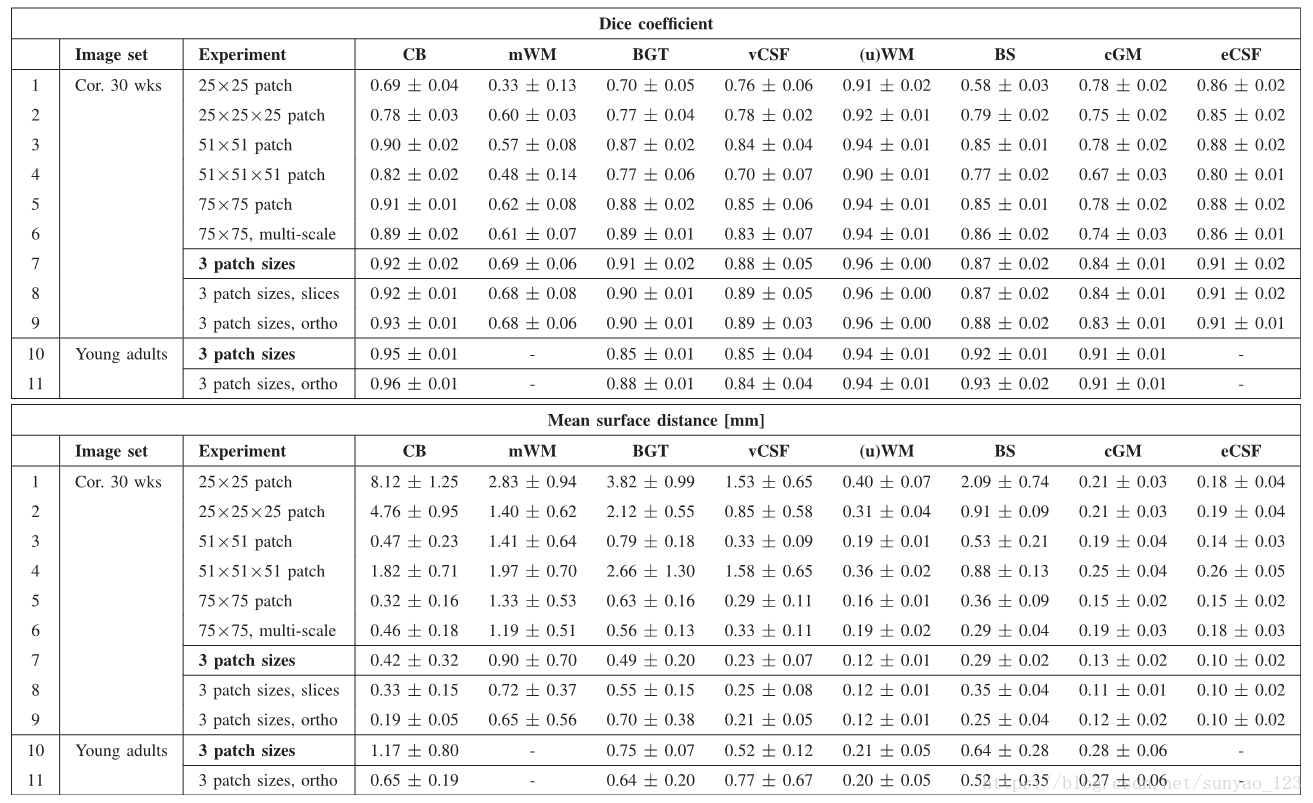
每个实验结果如下图,
tf代码简单实现
与原论文不同的是,没有使用镜像,使用padding 0。提取训练集是对所有人进行随机采样,所以不会出现类别不平衡问题。训练集不使用没有目标的patch。