论文速读 – Efficient Spatial-Temporal Information Fusion for LiDAR-Based 3D Moving Object Segmentation
先赞后看,养成好习惯。有帮助的话,点波关注!我会坚持更新,感谢您的支持!
参考:
1.MotionSeg3D paper
2.MotionSeg3D code
3.近两年激光雷达运动物体分割论文阅读小结
一. 摘要
准确的运动物体分割是必不可少的自动驾驶的任务。对于许多下游任务,它可以提供有效的信息,例如避障,路径规划和静态地图构建。使用基于range图像的双分支结构来分别处理空间和时间信息,结合运动引导的注意力模块;使用点提炼模块通过 3D稀疏卷积融合来自 LiDAR 距离图像和点云的信息,表示并减少边界上的伪影。
二. 介绍
MOS 被视作高层次的“二分类”静态分割任务。有别于基本的语义分割任务,更关注运动物体属性。点云分割,流行的表征方式有基于点(point-based),基于体素(voxel-based),基于深度图(range image-based)。基于深度图方式作为轻量级的代表,实用于实时性推理。
主要贡献:
1)提出一种由运动引导注意力模块桥接的双分支结构,以更好地利用残差图像中的时序运动信息。
2) 我们使用从粗到细架构以减少对象边界上的模糊伪影。
相关工作:
几何方法:基于预制clean-map的方式,当前帧在地图中查找,无法实时。
基于场景流的方法: 低速物体和传感器噪声会干扰。
LMNet 直接使用现成的分割网络, 通过简单地连接残差来利用时空信息。
三. 网络与方法
3.1 预处理
Range image 表征
使用(u,v)对点云进行索引,range image包含五个channel:x,y,z,r(range),intensity。
残差图像
- 过去帧与当前帧 坐标系对齐
- 过去帧的range image 投影
- 计算像素参差
meta-kernal卷积算子
卷积时采用笛卡尔坐标系,来充分利用3D几何信息。
3.2 网络架构
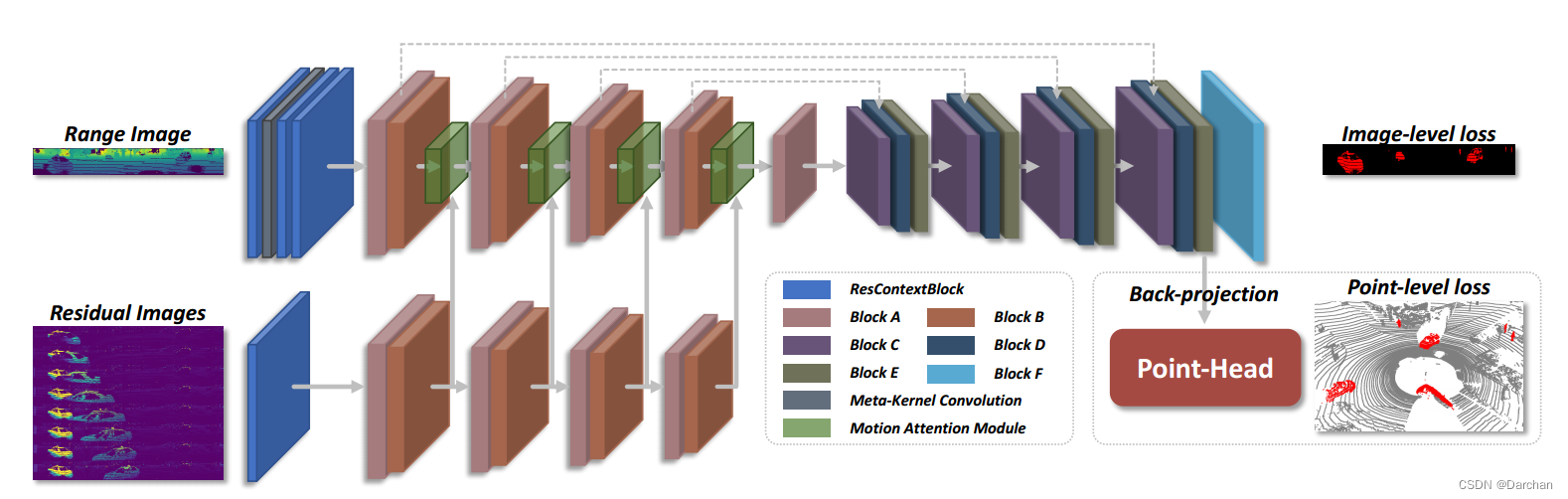
基于SalsaNext,一种基于深度图的编码解码网络。
本文修改了两个分支和两个头的网络任务,使用Enc-A分支编码外在特征,使用参差图像Enc-M分支去编码时序运动信息。使用ImageHead解码来自Enc-A和Enc-M的特征;使用PointHead稀疏卷积模块提升分割结果。
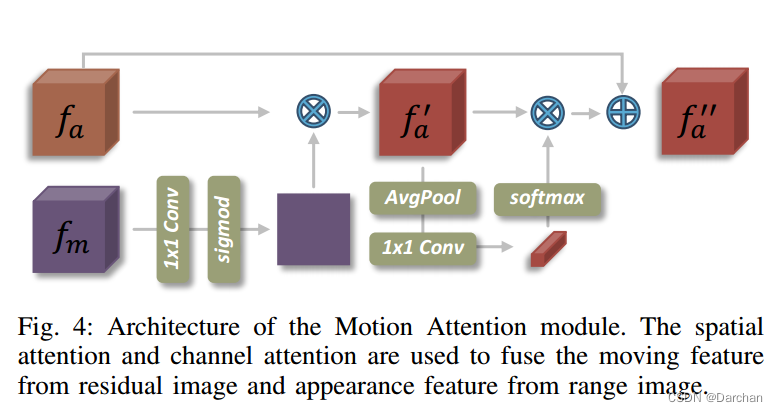
带有注意力引导机制的双分支
受视频目标分割的启发,作者添加了一个空间和通道注意力模块来从残差图像中提取和利用运动信息
,加强外观特征中某些重点区域的响应,最终生成一个时空融合特征。
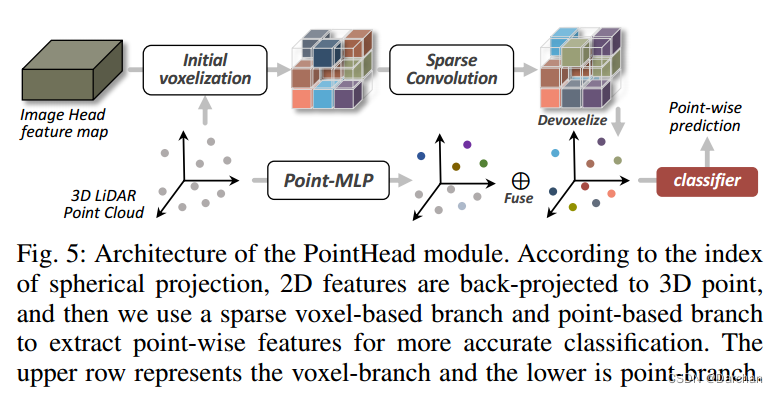
由粗到细:通过3D稀疏卷积点提升模块
不只使用基于像素的loss,我们提出了一个点云的head在2D卷积网络之后,来精细化分割结果。
做法:将网络输出的2D预测图先back-projection为3D点云数据形式,然后进入两个分支。上分支先对点云进行体素化,然后再进行稀疏卷积,最后反体素化为点云数据,计算一个预测误差;下分支利用MLP对点云数据进行处理并输出预测结果,计算一个误差。上下分支的两个误差相加得到最终误差。
3.3 损失函数
带权重的交叉熵loss 和 LovaszSoftmax loss
四. 实验
4.1 数据集
SemanticKITTI-MOS: 数据集包含22连续片段,10个连续片段(19130帧)用于训练,一个片段(4071帧)用于验证,11个连续片段(20351帧)用于测试。点云帧被分为动态帧(动态点100个)和静态帧(动态点少于100个)。训练集中动态帧比例仅仅25.77。
KITTI-road:自己标注了12个连续片段,6个(2905帧用于训练)和6个(2889帧)用于评估,文中提到即将发布此标注好的数据集。
4.2 评估标准
Iou = TP/( TP + FP + FN)
4.3 baseline
- LMNet
- LiMoSeg(未开源)
- Point-Voxel View
4.4 结果
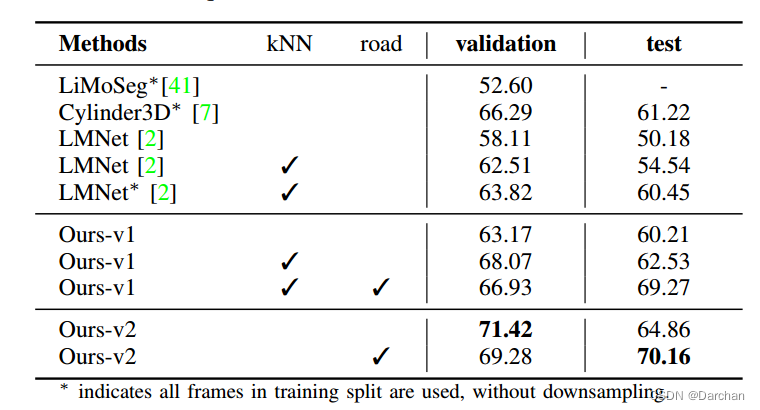
评价结果
其中knn指是否进行knn后处理,road指是否加入KITTI-road额外数据集一起训练。
耗时统计
