RDD,也就是 弹性分布式数据集 的简称,它是spark处理的分布式元素集合。
对于RDD的操作包括:
创建RDD(从外部数据或者内存中的数据),转化RDD(利用筛选条件等),调用RDD操作求值。
**注意:RDD的操作分为两种:一种是
“转化操作”,这种操作相当于只是定义了RDD,例如从一个RDD筛选出另一个RDD。转化操作的特点就是:返回结果仍然是一个RDD对象,转化操作并不会立刻执行,而是会惰性的执行,也就是到了不得不执行的时候才执行。另一种是
“行动操作”,是指调用RDD对象的方法返回一些值,例如统计一个文本RDD有多少行等.
**对于可能重复使用的RDD,可以使用persist()方法将其保存在内存中(也可以通过选项将其保存在磁盘上),默认情况下,cache()方法与persist()方法效果一样。
一、创建RDD的方法
①可以直接使用sc的parallelize()方法将数组参数转换成RDD对象,例如:
>>> line=
sc.parallelize(["hello this is the first line","this is the second line","hi I am the third","this is the last line"])
>>> for a in line.take(line.count()):
... print(a)
...
hello this is the first line
this is the second line
hi I am the third
this is the last line
>>>
这是在python脚本中执行的方法,如果是在java中的话,使用方法如下:
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("test02");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//从内存中插入
JavaRDD<String> line1 = javaSparkContext.parallelize(Arrays.asList("this is first line", "second line", "last line bye"));
//输出(行动操作)
int n = (int) line1.count();
List<String> list1 = line1.take(n);
for (int i = 0; i < list1.size(); i++) {
System.out.println(list1.get(i));
}
但是在大数据处理过程中,一般这种做法是不存在的,因为大量数据是不会从内存中导入的,而是要从磁盘中读取。
②从磁盘中读取文本文件的方法
从磁盘中读取文本文件使用方法如下:
>>> line=
sc.textFile("D:\spark\README.md")
>>> line2=line.filter(lambda a:"Java" in a)
>>> for m in line2.take(line2.count()):
... print(m)
...
high-level APIs in Scala, Java, Python, and R, and an optimized engine that
>>>
这里使用了python中的lambda表达式筛选出含有Java的行数。
在java应用程序中使用这种方式也类似:
//从外部文本文件读取
JavaRDD<String> line2 = javaSparkContext.textFile("D:\\spark\\README.md");
//筛选(转化操作)
line2 = line2.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("Python");
}
});
//输出
int m = (int) line2.count();
List<String> list2 = line2.take(m);
for (int i = 0; i < list2.size(); i++) {
System.out.println(list2.get(i));
}
关于惰性求值:当执行转化操作,例如 sc.textFile(" ... ") 的时候,其实并没有从文件中读取数据,所以即使文件路径不存在,也不会报错,但是我们可以通过行动操作来检测前面的转化操作有没有问题。
二、RDD的相关操作
①筛选元素的转化操作,
filter()
在java中,使用filter要传入一个Function<String,Boolean>类的继承类,该类的public Boolean call(String s)方法返回一个bool值,返回true表示符合筛选条件。
line2 = line2.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("Python");
}
});
②联合两个RDD的方法,
union()
使用方法在各个语言中一样,都是传入一个RDD参数,然后将两个RDD联合在一起。
下面是shell中使用的示例:
>>> line1=sc.parallelize(["hello world","second line","last line"])
>>> line2=sc.parallelize(["another line","really last line"])
>>> line1.count()
3
>>> line2.count()
2
>>> for a in line1.take(3):
... print(a)
...
hello world
second line
last line
>>> for a in line2.take(2):
... print(a)
...
another line
really last line
>>> line3 = line1.union(line2)
>>> line3.count()
5
>>> for a in line3.take(5):
... print(a)
...
hello world
second line
last line
another line
really last line
>>>
**注意:filter()和union()函数不会改变原来的两个RDD,而是会新生成RDD,所以需要赋值给新的变量
③计算文本行数的行动操作,count()
count()是一个行动操作,当在某一个RDD上执行count()函数的时候,它所依赖的转化操作,例如筛选等会依次被执行。
④取RDD的前n行作为字符串列表,take(n)
⑤java向spark传递函数的方法

三、RDD的其它常用转化操作和行动操作
①转化操作
filter()
与
map()
的区别
filter()简单来说就是一个过滤器。可以只筛选出符合函数参数的数据,而map()函数则可以修改对元素做一对的修改,即将元素作为参数,根据映射关系改变元素的值(这个说法不确切,应该说是修改元素副本的值,返回的也是副本)。
filter()的使用方法在之前已经说过了,这里主要介绍一下map()的用法。
在shell中:
>>> line=sc.parallelize([1,2,3,3])
>>> line2=line.map(lambda x:x*x)
>>> line2.count()
4
>>> for a in line2.take(4):
... print(a)
...
1
4
9
9
>>>
这里注意:无论是filter()还是map(),都是转化操作,只要是转化操作都不会改变原来RDD的数据,而是会把新的RDD作为返回值。
在java中使用map将元素做映射:
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("test03");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<Integer> line = sc.parallelize(Arrays.asList(1, 2, 3, 4));
//使用map对数据集中的每一个元素做映射处理
JavaRDD<Integer> line2 = line.map(new Function<Integer, Integer>() {
public Integer call(Integer integer) throws Exception {
return (int)Math.pow(integer,3);
}
});
int num = (int) line2.count();
List<Integer> list = line2.take(num);
for (int i = 0; i < num; i++) {
System.out.println(list.get(i));
}
sc.stop();
}
这里仍然是需要Function的实例,只不过泛型不同。
②
map()
与
flatMap()
的区别
上面看到map()函数可以将元素做一对一的映射从而达到处理数据的目的,而flatMap()函数则可以对函数做一对多的映射,即将一个元素映射成为多个元素,原先后面的元素依然排在后面。举个例子,例如将每个元素是一句话,想要把每句话映射成为一个个空格分开的单词,如果使用map就只能返回一个数组,最后返回的RDD是由数组组成的。但是使用flatMap就可以返回一个由所有单词组成的元素个数变长了的RDD。
下面是shell中的例子:
>>> line=sc.parallelize(["hello a world","hello second world","good hello word"])
>>> line2=line.map(lambda s:s.split(" "))
>>> line2.first()
['hello', 'a', 'world'] #可以看到这里第一个元素变成了一个数组
>>> line2.count()
3
>>> line3=line.flatMap(lambda s:s.split(" "))
>>> line3.count()
9
>>> for a in line3.take(9):
... print(a)
...
hello
a
world
hello
second
world
good
hello
word
>>>
java中使用flatMap的示例:
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("test04");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> line = sc.parallelize(Arrays.asList("hello world", "good very hello", "you me hi"));
JavaRDD<String> line2 = line.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
});
int num = (int)line2.count();
List<String> strs = line2.take(num);
for(int i = 0;i<num;i++){
System.out.println(strs.get(i));
}
sc.stop();
}
③伪集合操作
RDD本身不是严格意义上的集合(因为它不满足唯一性),但是它也支持许多集合操作。例如并集、交集、差集等等。
注意:只有数据类型相同的两个RDD才能做集合运算。
*去除RDD数据集中的重复元素的转化操作可以使用
distinct()函数,但是需要注意:该函数开销比较大,因为这中间存在一个混洗(将所有数据通过网络与其他机器上的数据比较)的操作。
shell示例:
>>> line=sc.parallelize([1,2,3,4,1,3])
>>> line2=line.distinct()
>>> line2.count()
[Stage 18:> (0 + 2) / 2]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 19:> (0 + 2) / 2]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
4
>>> for a in line2.take(4):
... print(a)
...
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
2
4
1
3
>>>
可以看到:混洗(shuffle)之后的数据是无序的(这一点还需要深入研究)
*
union()函数可以取并集,这个之前说过,不再赘述
*
intersection(other) 方法可以取交集,不过这里会自动去重,所以也会有混洗的过程,运行比较慢。
>>> line1=sc.parallelize([1,2,3,2,1,4])
>>> line2=sc.parallelize([2,4,5,6])
>>> line3=line1.intersection(line2)
>>> line3.count()
[Stage 32:> (0 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 32:=============================> (2 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 33:> (0 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 33:==============> (1 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 33:=============================> (2 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
2
>>> for a in line3.take(2):
... print(a)
...
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 37:> (0 + 2) / 2]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
4
2
>>>
*
subtract(other) 函数可以取两个集合的差集。
>>> line1=sc.parallelize([1,2,3,4,4,5,1])
>>> line2=sc.parallelize([1,3,6,7])
>>> lin3=line1.subtract(line2)
>>> line3.count()
[Stage 39:> (0 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 39:==============> (1 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 39:=============================> (2 + 2) / 4]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
2
>>> for a in line3.take(2):
... print(a)
...
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
[Stage 43:> (0 + 2) / 2]D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
D:\spark\python\lib\pyspark.zip\pyspark\shuffle.py:58: UserWarning: Please install psutil to have better support with spilling
4
2
>>>
可以看到,这里取差集也会执行混洗操作自动去重
*求两个RDD数据集的笛卡尔积:
cartesian() 函数,返回一个由二元组组成的RDD
>>> line1=sc.parallelize([1,2,3,4,4,5,1])
>>> line2=sc.parallelize([2,4,5,6])
>>> line3=line1.cartesian(line2)
>>> line3.count()
28
>>> for a in line3.take(28):
... print(a,end='')
...
(1, 2)(1, 4)(2, 2)(2, 4)(3, 2)(3, 4)(1, 5)(1, 6)(2, 5)(2, 6)(3, 5)(3, 6)(4, 2)(4, 4)(4, 2)(4, 4)(5, 2)(5, 4)(1, 2)(1, 4)(4, 5)(4, 6)(4, 5)(4, 6)(5, 5)(5, 6)(1, 5)(1, 6)>>>
④行动操作
*
collect() 函数可以将RDD的所有值全部以集合或者值的形式返回回来,但是这个函数一般只能用在单元测试中,因为实际的数据量太大,无法一次性读入到内存。
>>> line1.collect()
[1, 2, 3, 4, 4, 5, 1]
>>>
*
take(n) 函数,可以取前n个数据,之前说过,这里不再赘述。
*
reduce() 函数,常用在求和中,该函数接受一个函数作为参数,使用该函数从头开始计算两两数据,最后得到一个值,但是该函数的缺点是计算结果只能与数据类型相同。
shell示例:
>>> line=sc.parallelize([1,3,2,4])
>>> total=line.reduce(lambda x,y:x+y)
>>> total
10
>>
*
aggregate()函数算是reduce()函数的升级版,它可以指定两个元素操作之后的结果。该函数需要传入三个参数:初始值,本地当前结果与下一个元素的操作函数,节点之间计算结果的操作函数。
例如想要求平均值,就需要返回一个总值和总个数的二元组。使用python脚本示例如下:
>>> line=sc.parallelize([1,3,2,4,4,2])
>>> ave = line.aggregate((0,0),lambda x,v:(x[0]+v,x[1]+1),lambda y,z:(y[0]+z[0],y[1]+z[1]))
>>> ave[0]/ave[1]
2.6666666666666665
>>> ave[0]
16
>>> ave[1]
6
>>>
在这个示例中,(0,0) 是初始值,分别表示初始总和和初始元素个数,第二个参数指定了当前结果(即一个二元组)与下一个元素操作的函数,第三个参数指定了多个节点之间的结果如何合并。
java中的实现如下:
public class TestAggregate {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("test05");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> line = sc.parallelize(Arrays.asList(1, 2, 3, 4, 2, 1));
AveResult ave = line.aggregate(new AveResult(), new Function2<AveResult, Integer, AveResult>() {
public AveResult call(AveResult aveResult, Integer integer) throws Exception {
AveResult aveResult1 = new AveResult();
aveResult1.setSum(aveResult.getSum() + integer);
aveResult1.setNum(aveResult.getNum() + 1);
return aveResult1;
}
}, new Function2<AveResult, AveResult, AveResult>() {
public AveResult call(AveResult aveResult, AveResult aveResult2) throws Exception {
AveResult aveResult1 = new AveResult();
aveResult1.setSum(aveResult.getSum() + aveResult2.getSum());
aveResult1.setNum(aveResult.getNum() + aveResult2.getNum());
return aveResult1;
}
});
System.out.println(ave.getAve());
sc.stop();
}
}
/**
* 注意:这里一定要实现序列化接口,否则会报错
*/
class AveResult implements Serializable{
private int sum;
private int num;
public AveResult() {
sum = 0;
num = 0;
}
public double getAve() {
return ((double) sum) / num;
}
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
这里特别注意:
自定义的返回值类型一定要实现序列化接口!!
*
foreach(func) 函数,有时我们会对 RDD 中的所有元素应用一个行动操作,但是不把任何结果返回到驱动器程 序中,这也是有用的。比如可以用 JSON 格式把数据发送到一个网络服务器上,或者把数 据存到数据库中。不论哪种情况,都可以使用 foreach() 行动操作来对 RDD 中的每个元 素进行操作,而不需要把 RDD 发回本地。
*
takeSample(withReplacement, num, seed) 函数可以让我们从数据中获取一个采样,并指定是否替换。
这个返回值是不确定的:
>>> line.takeSample(0,2)
[4, 4]
>>> line.takeSample(0,2)
[3, 1]
>>> line.takeSample(0,2)
[1, 2]
>>>
四、持久化
如前所述,Spark RDD 是惰性求值的,而有时我们希望能多次使用同一个 RDD。如果简单 地对 RDD 调用行动操作,Spark 每次都会重算 RDD 以及它的所有依赖。这在迭代算法中 消耗格外大,因为迭代算法常常会多次使用同一组数据。
为了避免多次计算同一个 RDD,可以让 Spark 对数据进行持久化。当我们让 Spark 持久化 存储一个 RDD 时,计算出 RDD 的节点会分别保存它们所求出的分区数据。如果一个有持 久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果 希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份到多个节点上。
出于不同的目的,我们可以为 RDD 选择不同的持久化级别(如表 3-6 所示)。在 Scala(见 例 3-40)和 Java 中,默认情况下
persist() 会把数据以序列化的形式缓存在 JVM 的堆空 间中。在 Python 中,我们会始终序列化要持久化存储的数据,所以持久化级别默认值就是 以序列化后的对象存储在 JVM 堆空间中。当我们把数据写到磁盘或者堆外存储上时,也 总是使用序列化后的数据。
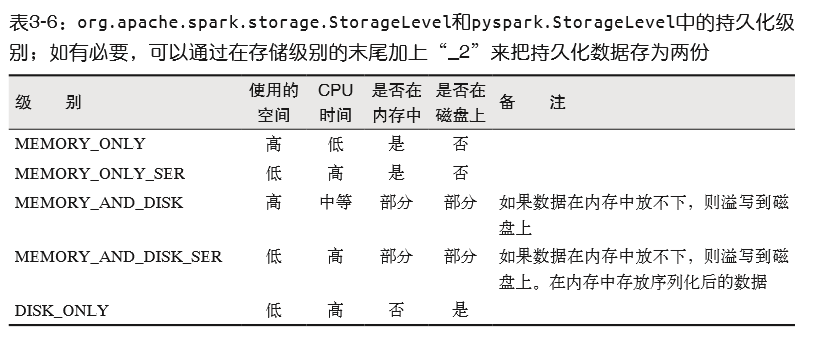
!!注意:如果只是调用persist()函数,并不会触发强制求值,只是会保存下这个从策略,只有当调用行动操作的时候才会真正计算RDD
最后,RDD 还有一个方法叫作
unpersist(),调用该方法可以手动把持久化的 RDD 从缓 存中移除。
五、java中不同RDD类型的转换
