摘要:Spark编程基础_RDD初级编程
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1.RDD编程基础
1.1 RDD创建
【1】从文件系统中加载数据创建RDD
Spark采用textFile()方法来从文件系统中加载数据创建RDD
该方法把文件的URL作为参数,这个URL可以是:
本地文件系统的地址
或者是Amazon S3的地址等等
(1)创建RDD之前的准备工作
在即将进行相关的实践操作前,我们首先要登录linux系统,然后,打开命令行“终端”,输入

cd /usr/local/hadoop
进入相应文件夹
然后:
./sbin/start-dfs.sh

然后启动spark-shell
输入
cd /usr/local/spark
./bin/spark-shell
之后新建空白终端,进入“/usr/local/spark/mycode”目录,在这个文件夹下创建新的rdd子目录用来存放相关代码及文件;
cd /usr/local/spark/mycode/
mkdir rdd
之后用vim编辑器,在rdd下创建一个word.txt文件,随便输入几行英文字母;
(2)从文件系统中加载数据:
下面我切换回spark-shell窗口,看一下如何从本地文件系统中加载数据:
scala>val lines=sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
lines:org.apache.spark.rdd.RDD[String]=file:///usr/local/spark/mycode/rdd/word.txt MapPartitions RDD[12] at textFile at <console>:27
输出:

(3)从分布式文件系统HDFS中加载数据
scala> val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
scala> val lines = sc.textFile("/user/hadoop/word.txt")
scala> val lines = sc.textFile("word.txt")
输出:

三条语句是完全等价的,可以使用其中任意一种方式。
【2】通过并行集合(数组)创建RDD
可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
|
1
2
3
4
|
scala>
val
array
=
Array(
1
,
2
,
3
,
4
,
5
)
array
:
Array[Int]
=
Array(
1
,
2
,
3
,
4
,
5
)
scala>
val
rdd
=
sc.parallelize(array)
rdd
:
org.apache.spark.rdd.RDD[Int]
=
ParallelCollectionRDD[
13
] at parallelize at <console>
:
29
|
或者,也可以从列表中创建:
|
1
2
3
4
|
scala>
val
list
=
List(
1
,
2
,
3
,
4
,
5
)
list
:
List[Int]
=
List(
1
,
2
,
3
,
4
,
5
)
scala>
val
rdd
=
sc.parallelize(list)
rdd
:
org.apache.spark.rdd.RDD[Int]
=
ParallelCollectionRDD[
14
] at parallelize at <console>
:
29
|
1.2 RDD操作
1. 转换操作
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果(统计结果) |
案例:
filter(func) //筛选出包含Spark的行
|
1
2
3
4
5
|
scala>
val
lines
=
sc.textFile(file
:
///usr/local/spark/mycode/rdd/word.txt)
scala>
val
linesWithSpark
=
lines.filter(line
=
> line.contains(
"Spark"
))
//另外一个实例,每一行用空格分割
scala>
val
lines
=
sc.textFile(
"file:///usr/local/spark/mycode/rdd/word.txt"
)
scala>
val
words
=
lines.map(line
=
> line.split(
" "
))
|
map(func) //map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集
|
1
2
3
|
scala> data
=
Array(
1
,
2
,
3
,
4
,
5
)
scala>
val
rdd
1
=
sc.parallelize(data)
scala>
val
rdd
2
=
rdd
1
.map(x
=
>x+
10
)
|
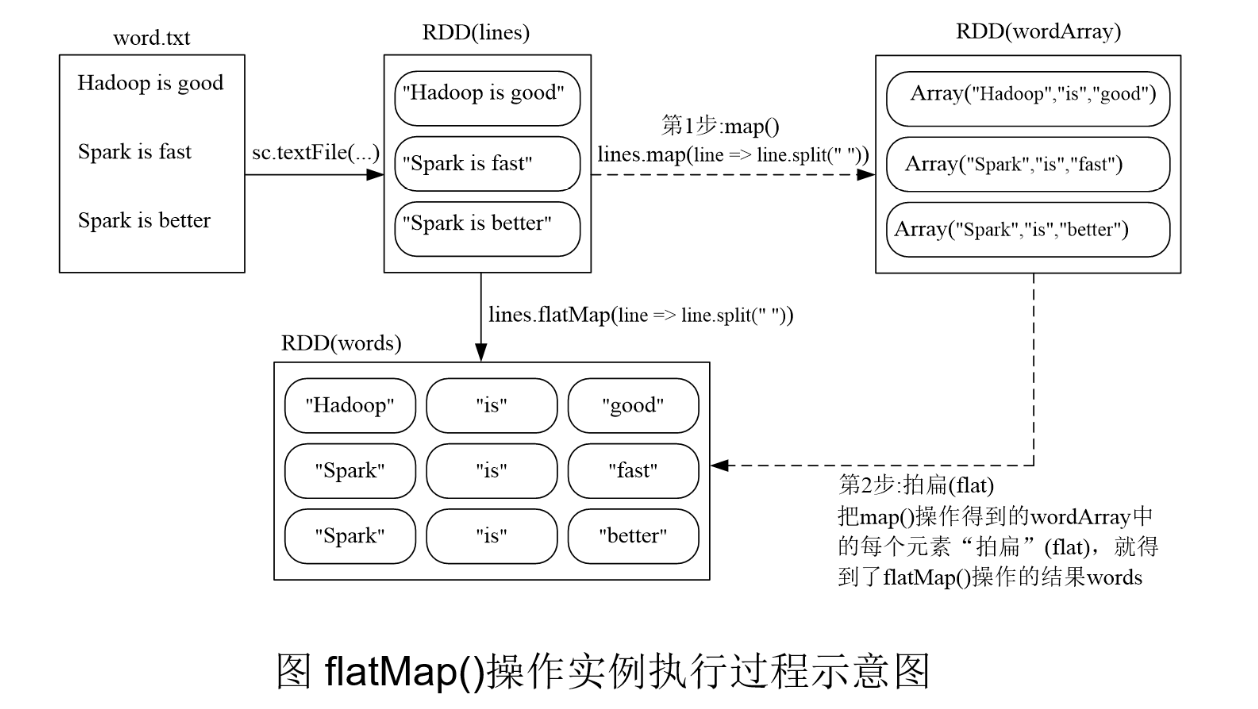
flatMap(func)
|
1
2
|
scala>
val
lines
=
sc.textFile(
"file:///usr/local/spark/mycode/rdd/word.txt"
)
scala>
val
words
=
lines.flatMap(line
=
> line.split(
" "
))
|
groupByKey()
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集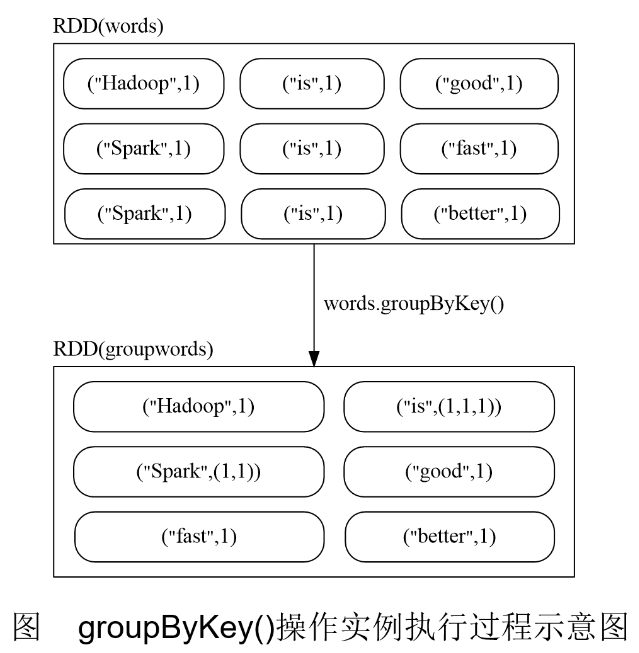
reduceByKey(func)
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果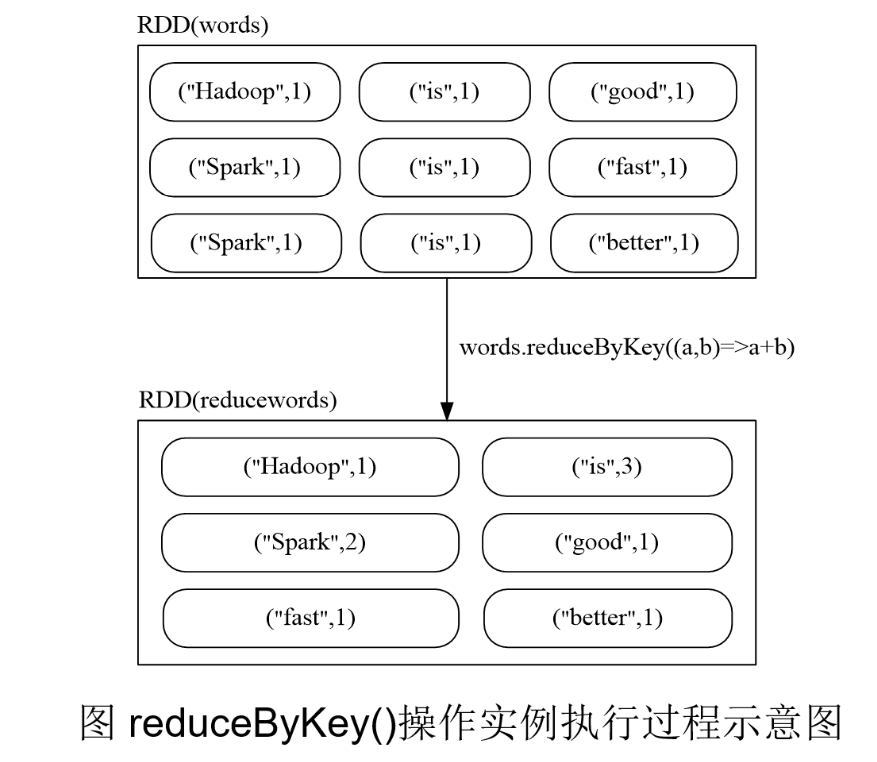
2. 行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
scala>
val
rdd
=
sc.parallelize(Array(
1
,
2
,
3
,
4
,
5
))
rdd
:
org.apache.spark.rdd.RDD[Int]
=
ParallelCollectionRDD[
1
] at parallelize at <console>
:
24
scala> rdd.count()
res
0
:
Long
=
5
res
1
:
Int
=
1
scala> rdd.take(
3
)
res
2
:
Array[Int]
=
Array(
1
,
2
,
3
)
scala> rdd.reduce((a,b)
=
>a+b)
res
3
:
Int
=
15
scala> rdd.collect()
res
4
:
Array[Int]
=
Array(
1
,
2
,
3
,
4
,
5
)
scala> rdd.foreach(elem
=
>println(elem))
1
2
3
4
5
|
3. 惰性机制
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。这里给出一段简单的语句来解释Spark的惰性机制。
|
1
2
3
|
scala>
val
lines
=
sc.textFile(
"data.txt"
)
scala>
val
lineLengths
=
lines.map(s
=
> s.length)
scala>
val
totalLength
=
lineLengths.reduce((a, b)
=
> a + b)
|
1.3 持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据
|
1
2
3
4
5
6
7
8
|
scala>
val
list
=
List(
"Hadoop"
,
"Spark"
,
"Hive"
)
list
:
List[String]
=
List(Hadoop, Spark, Hive)
scala>
val
rdd
=
sc.parallelize(list)
rdd
:
org.apache.spark.rdd.RDD[String]
=
ParallelCollectionRDD[
22
] at parallelize at <console>
:
29
scala> println(rdd.count())
//行动操作,触发一次真正从头到尾的计算
3
scala> println(rdd.collect().mkString(
","
))
//行动操作,触发一次真正从头到尾的计算
Hadoop,Spark,Hive
|
可以通过持久化(缓存)机制避免这种重复计算的开销
可以使用persist()方法对一个RDD标记为持久化
之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
persist()的圆括号中包含的是持久化级别参数:
persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容
persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上
一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)
可以使用unpersist()方法手动地把持久化的RDD从缓存中移除
针对上面的实例,增加持久化语句以后的执行过程如下:
|
1
2
3
4
5
6
7
8
9
|
scala>
val
list
=
List(
"Hadoop"
,
"Spark"
,
"Hive"
)
list
:
List[String]
=
List(Hadoop, Spark, Hive)
scala>
val
rdd
=
sc.parallelize(list)
rdd
:
org.apache.spark.rdd.RDD[String]
=
ParallelCollectionRDD[
22
] at parallelize at <console>
:
29
scala> rdd.cache()
//会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成
scala> println(rdd.count())
//第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
3
scala> println(rdd.collect().mkString(
","
))
//第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
Hadoop,Spark,Hive
|
1.4 分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
1.分区的作用
(1)增加并行度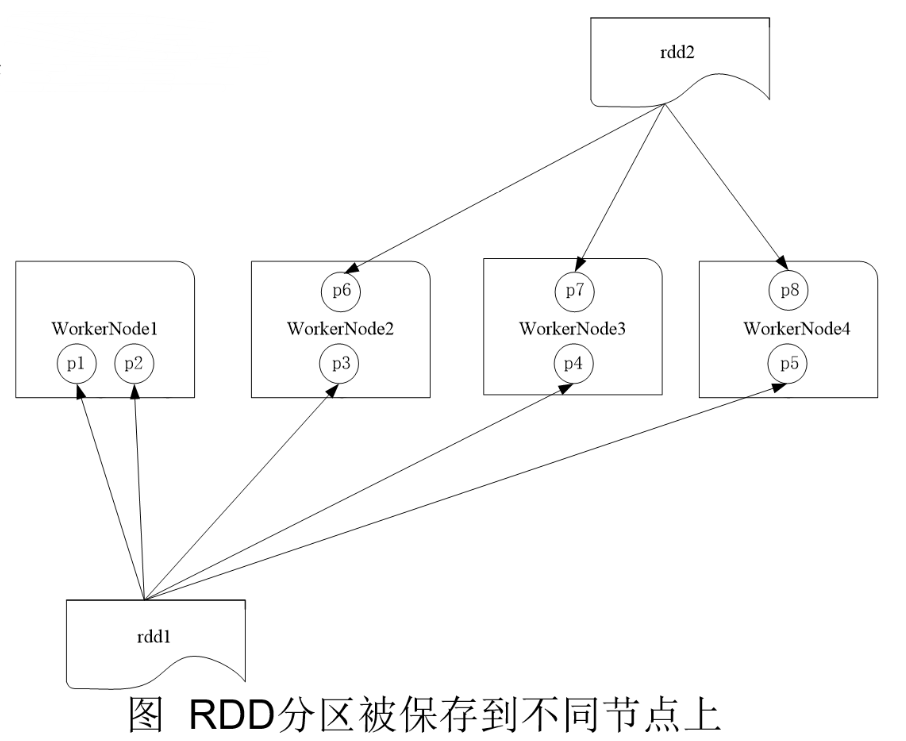
(2)减少通信开销
2.RDD分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目
对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
*本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
*Apache Mesos:默认的分区数为8
*Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
3.设置分区的个数
(1)创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path, partitionNum)
其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
|
1
2
|
scala>
val
array
=
Array(
1
,
2
,
3
,
4
,
5
)
scala>
val
rdd
=
sc.parallelize(array,
2
)
//设置两个分区
|
(2)使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
|
1
2
3
4
5
6
7
8
|
scala>
val
data
=
sc.textFile(
"file:///usr/local/spark/mycode/rdd/word.txt"
,
2
)
data
:
org.apache.spark.rdd.RDD[String]
=
file
:
///usr/local/spark/mycode/rdd/word.txt MapPartitionsRDD[12] at textFile at <console>:24
scala> data.partitions.size
//显示data这个RDD的分区数量
res
2
:
Int
=
2
scala>
val
rdd
=
data.repartition(
1
)
//对data这个RDD进行重新分区
rdd
:
org.apache.spark.rdd.RDD[String]
=
MapPartitionsRDD[
11
] at repartition at
:
26
scala> rdd.partitions.size
res
4
:
Int
=
1
|
4.自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的Partitioner对象来控制RDD的分区方式,从而利用领域知识进一步减少通信开销。
要实现自定义分区,需要定义一个类,这个自定义类需要继承org.apache.spark.Partitioner类,并实现下面三个方法:
numPartitions: Int 返回创建出来的分区数
getPartition(key: Any): Int 返回给定键的分区编号(0到numPartitions-1)
equals() Java判断相等性的标准方法
2 键值对RDD
2.1 键值对RDD的创建
(1)第一种创建方式:从文件中加载
可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
|
1
2
3
4
5
6
7
8
9
|
scala>
val
lines
=
sc.textFile(
"file:///usr/local/spark/mycode/pairrdd/word.txt"
)
lines
:
org.apache.spark.rdd.RDD[String]
=
file
:
///usr/local/spark/mycode/pairrdd/word.txt MapPartitionsRDD[1] at textFile at <console>:27
scala>
val
pairRDD
=
lines.flatMap(line
=
> line.split(
" "
)).map(word
=
> (word,
1
))
pairRDD
:
org.apache.spark.rdd.RDD[(String, Int)]
=
MapPartitionsRDD[
3
] at map at <console>
:
29
scala> pairRDD.foreach(println)
(i,
1
)
(love,
1
)
(hadoop,
1
)
……
|
(2)第二种创建方式:通过并行集合(数组)创建RDD
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
scala>
val
list
=
List(
"Hadoop"
,
"Spark"
,
"Hive"
,
"Spark"
)
list
:
List[String]
=
List(Hadoop, Spark, Hive, Spark)
scala>
val
rdd
=
sc.parallelize(list)
rdd
:
org.apache.spark.rdd.RDD[String]
=
ParallelCollectionRDD[
11
] at parallelize at <console>
:
29
scala>
val
pairRDD
=
rdd.map(word
=
> (word,
1
))
pairRDD
:
org.apache.spark.rdd.RDD[(String, Int)]
=
MapPartitionsRDD[
12
] at map at <console>
:
31
scala> pairRDD.foreach(println)
(Hadoop,
1
)
(Spark,
1
)
(Hive,
1
)
(Spark,
1
)
|
2.2 常用的键值对RDD转换操作
reduceByKey(func) reduceByKey(func)的功能是,使用func函数合并具有相同键的值
|
1
2
3
4
5
6
7
8
|
(Hadoop,
1
)
(Spark,
1
)
(Hive,
1
)
(Spark,
1
)
scala> pairRDD.reduceByKey((a,b)
=
>a+b).foreach(println)
(Spark,
2
)
(Hive,
1
)
(Hadoop,
1
)
|
groupByKey() groupByKey()的功能是,对具有相同键的值进行分组
比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))
|
1
2
|
scala> pairRDD.groupByKey()
res
15
:
org.apache.spark.rdd.RDD[(String, Iterable[Int])]
=
ShuffledRDD[
15
] at groupByKey at <console>
:
34
|
reduceByKey和groupByKey的区别:
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义
groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
|
1
2
3
4
|
scala>
val
words
=
Array(
"one"
,
"two"
,
"two"
,
"three"
,
"three"
,
"three"
)
scala>
val
wordPairsRDD
=
sc.parallelize(words).map(word
=
> (word,
1
))
scala>
val
wordCountsWithReduce
=
wordPairsRDD.reduceByKey(
_
+
_
)
scala>
val
wordCountsWithGroup
=
wordPairsRDD.groupByKey().map(t
=
> (t.
_
1
, t.
_
2
.sum))
|
上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的
(1)当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合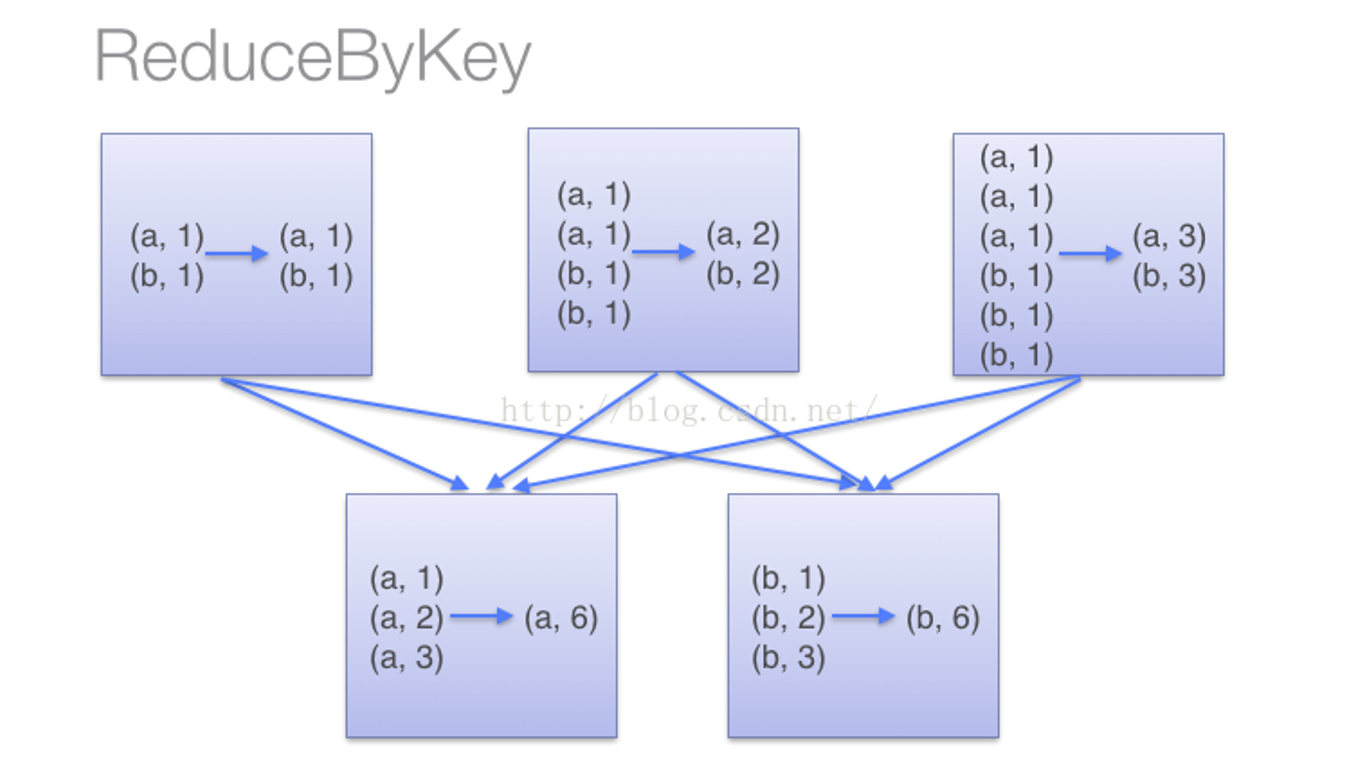
(2)当采用groupByKey时,由于它不接收函数,Spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时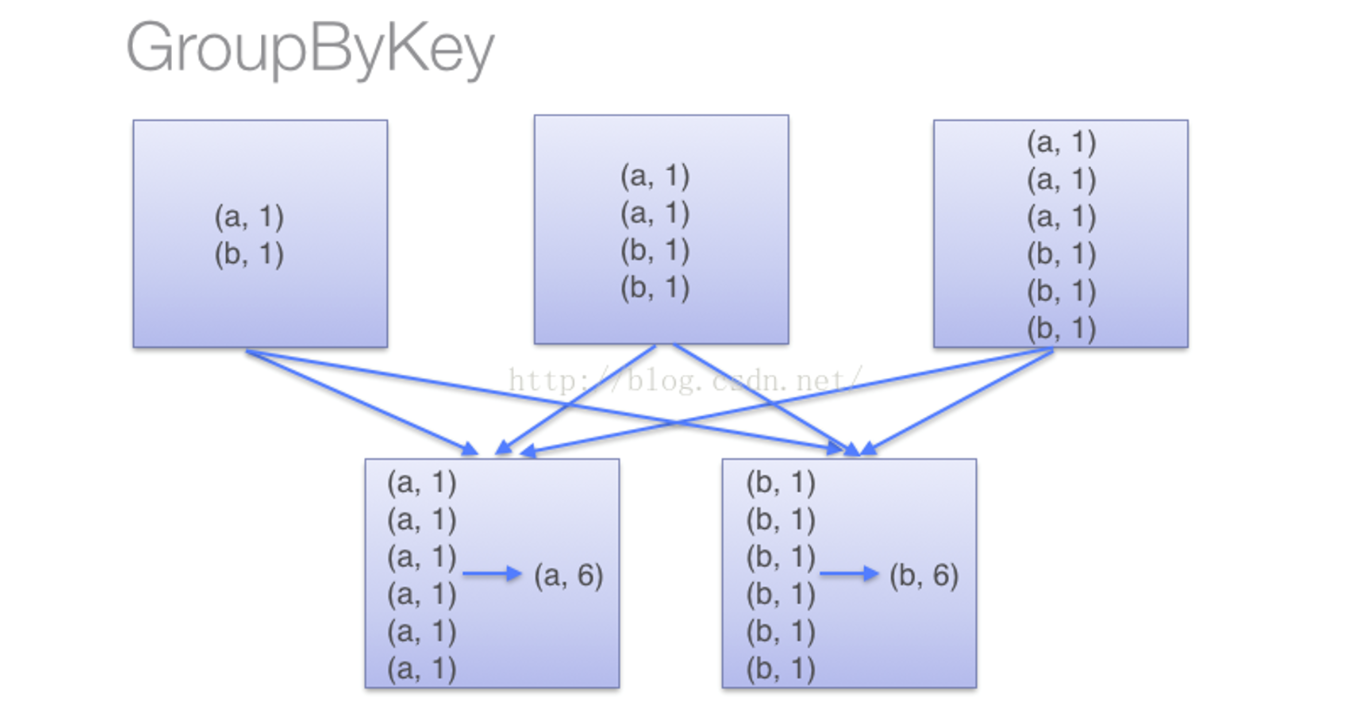
keys keys只会把Pair RDD中的key返回形成一个新的RDD
|
1
2
3
4
5
6
7
8
9
10
11
12
|
(Hadoop,
1
)
(Spark,
1
)
(Hive,
1
)
(Spark,
1
)
scala> pairRDD.keys
res
17
:
org.apache.spark.rdd.RDD[String]
=
MapPartitionsRDD[
17
] at keys at <console>
:
34
scala> pairRDD.keys.foreach(println)
Hadoop
Spark
Hive
Spark
|
values values只会把Pair RDD中的value返回形成一个新的RDD。
|
1
2
3
4
5
6
7
|
scala> pairRDD.values
res
0
:
org.apache.spark.rdd.RDD[Int]
=
MapPartitionsRDD[
2
] at values at <console>
:
34
scala> pairRDD.values.foreach(println)
1
1
1
1
|
sortByKey() sortByKey()的功能是返回一个根据键排序的RDD
|
1
2
3
4
5
6
7
|
scala> pairRDD.sortByKey()
res
0
:
org.apache.spark.rdd.RDD[(String, Int)]
=
ShuffledRDD[
2
] at sortByKey at <console>
:
34
scala> pairRDD.sortByKey().foreach(println)
(Hadoop,
1
)
(Hive,
1
)
(Spark,
1
)
(Spark,
1
)
|
sortByKey()和sortBy()
|
1
2
3
4
5
6
7
|
scala>
val
d
1
=
sc.parallelize(Array((“c
",8),(“b“,25),(“c“,17),(“a“,42),(“b“,4),(“d“,9),(“e“,17),(“c“,2),(“f“,29),(“g“,21),(“b“,9)))
scala> d1.reduceByKey(_+_).sortByKey(false).collect
res2: Array[(String, Int)] = Array((g,21),(f,29),(e,17),(d,9),(c,27),(b,38),(a,42))
scala> val d2 = sc.parallelize(Array((“c"
,
8
),(“b“,
25
),(“c“,
17
),(“a“,
42
),(“b“,
4
),(“d“,
9
),(“e“,
17
),(“c“,
2
),(“f“,
29
),(“g“,
21
),(“b“,
9
)))
scala> d
2
.reduceByKey(
_
+
_
).sortBy(
_
.
_
2
,
false
).collect
res
4
:
Array[(String, Int)]
=
Array((a,
42
),(b,
38
),(f,
29
),(c,
27
),(g,
21
),(e,
17
),(d,
9
))
|
mapValues(func) 对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
|
1
2
3
4
5
6
7
|
scala> pairRDD.mapValues(x
=
> x+
1
)
res
2
:
org.apache.spark.rdd.RDD[(String, Int)]
=
MapPartitionsRDD[
4
] at mapValues at <console>
:
34
scala> pairRDD.mapValues(x
=
> x+
1
).foreach(println)
(Hadoop,
2
)
(Spark,
2
)
(Hive,
2
)
(Spark,
2
)
|
join join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
scala>
val
pairRDD
1
=
sc.parallelize(Array((
"spark"
,
1
),(
"spark"
,
2
),(
"hadoop"
,
3
),(
"hadoop"
,
5
)))
pairRDD
1
:
org.apache.spark.rdd.RDD[(String, Int)]
=
ParallelCollectionRDD[
24
] at parallelize at <console>
:
27
scala>
val
pairRDD
2
=
sc.parallelize(Array((
"spark"
,
"fast"
)))
pairRDD
2
:
org.apache.spark.rdd.RDD[(String, String)]
=
ParallelCollectionRDD[
25
] at parallelize at <console>
:
27
scala> pairRDD
1
.join(pairRDD
2
)
res
9
:
org.apache.spark.rdd.RDD[(String, (Int, String))]
=
MapPartitionsRDD[
28
] at join at <console>
:
32
scala> pairRDD
1
.join(pairRDD
2
).foreach(println)
(spark,(
1
,fast))
(spark,(
2
,fast))
|
combineByKey
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C)
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C
mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner
mapSideCombine:是否在map端进行Combine操作,默认为true
3 数据读写
1.本地文件系统的数据读写
(1)从文件中读取数据创建RDD
|
1
|
scala>
val
textFile
=
sc.textFile(
"file:///usr/local/spark/mycode/wordcount/word.txt"
)
|
因为Spark采用了惰性机制,在执行转换操作的时候,即使输入了错误的语句,spark-shell也不会马上报错(假设word.txt不存在)
(2)把RDD写入到文本文件中
|
1
2
|
scala>
val
textFile
=
sc.textFile(
"file:///usr/local/spark/mycode/wordcount/word.txt"
)
scala> textFile.saveAsTextFile(
"file:///usr/local/spark/mycode/wordcount/writeback"
)
|
如果想再次把数据加载在RDD中,只要使用writeback这个目录即可,如下:
|
1
|
scala>
val
textFile
=
sc.textFile(
"file:///usr/local/spark/mycode/wordcount/writeback"
)
|
2.分布式文件系统HDFS的数据读写
从分布式文件系统HDFS中读取数据,也是采用textFile()方法,可以为textFile()方法提供一个HDFS文件或目录地址,如果是一个文件地址,它会加载该文件,如果是一个目录地址,它会加载该目录下的所有文件的数据
|
1
2
|
scala>
val
textFile
=
sc.textFile(
"hdfs://localhost:9000/user/hadoop/word.txt"
)
scala> textFile.first()
|
如下三条语句都是等价的:
|
1
2
3
|
scala>
val
textFile
=
sc.textFile(
"hdfs://localhost:9000/user/hadoop/word.txt"
)
scala>
val
textFile
=
sc.textFile(
"/user/hadoop/word.txt"
)
scala>
val
textFile
=
sc.textFile(
"word.txt"
)
|
同样,可以使用saveAsTextFile()方法把RDD中的数据保存到HDFS文件中,命令如下:
|
1
|
scala> textFile.saveAsTextFile(
"writeback"
)
|
3.JSON文件的数据读写
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
Spark提供了一个JSON样例数据文件,存放在“/usr/local/spark/examples/src/main/resources/people.json”中
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
把本地文件系统中的people.json文件加载到RDD中:
|
1
2
3
4
5
|
scala>
val
jsonStr
=
sc.textFile(
"file:///usr/local/spark/examples/src/main/resources/people.json"
)
scala> jsonStr.foreach(println)
{
"name"
:
"Michael"
}
{
"name"
:
"Andy"
,
"age"
:
30
}
{
"name"
:
"Justin"
,
"age"
:
19
}
|
4.读写HBase数据
1. 创建一个HBase表
2. 配置Spark
3. 编写程序读取HBase数据
如果要让Spark读取HBase,就需要使用SparkContext提供的newAPIHadoopRDD这个API将表的内容以RDD的形式加载到Spark中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import
org.apache.hadoop.conf.Configuration
import
org.apache.hadoop.hbase.
_
import
org.apache.hadoop.hbase.client.
_
import
org.apache.hadoop.hbase.mapreduce.TableInputFormat
import
org.apache.hadoop.hbase.util.Bytes
import
org.apache.spark.SparkContext
import
org.apache.spark.SparkContext.
_
import
org.apache.spark.SparkConf
object
SparkOperateHBase {
def
main(args
:
Array[String]) {
val
conf
=
HBaseConfiguration.create()
val
sc
=
new
SparkContext(
new
SparkConf())
//设置查询的表名
conf.set(TableInputFormat.INPUT
_
TABLE,
"student"
)
val
stuRDD
=
sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val
count
=
stuRDD.count()
println(
"Students RDD Count:"
+ count)
stuRDD.cache()
//遍历输出
stuRDD.foreach({
case
(
_
,result)
=
>
val
key
=
Bytes.toString(result.getRow)
val
name
=
Bytes.toString(result.getValue(
"info"
.getBytes,
"name"
.getBytes))
val
gender
=
Bytes.toString(result.getValue(
"info"
.getBytes,
"gender"
.getBytes))
val
age
=
Bytes.toString(result.getValue(
"info"
.getBytes,
"age"
.getBytes))
println(
"Row key:"
+key+
" Name:"
+name+
" Gender:"
+gender+
" Age:"
+age)
})
}
}
|
4. 编写程序向HBase写入数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import
org.apache.hadoop.hbase.HBaseConfiguration
import
org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import
org.apache.spark.
_
import
org.apache.hadoop.mapreduce.Job
import
org.apache.hadoop.hbase.io.ImmutableBytesWritable
import
org.apache.hadoop.hbase.client.Result
import
org.apache.hadoop.hbase.client.Put
import
org.apache.hadoop.hbase.util.Bytes
object
SparkWriteHBase {
def
main(args
:
Array[String])
:
Unit
=
{
val
sparkConf
=
new
SparkConf().setAppName(
"SparkWriteHBase"
).setMaster(
"local"
)
val
sc
=
new
SparkContext(sparkConf)
val
tablename
=
"student"
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT
_
TABLE, tablename)
val
job
=
new
Job(sc.hadoopConfiguration)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val
indataRDD
=
sc.makeRDD(Array(
"3,Rongcheng,M,26"
,
"4,Guanhua,M,27"
))
//构建两行记录
val
rdd
=
indataRDD.map(
_
.split(
','
)).map{arr
=
>{
val
put
=
new
Put(Bytes.toBytes(arr(
0
)))
//行健的值
put.add(Bytes.toBytes(
"info"
),Bytes.toBytes(
"name"
),Bytes.toBytes(arr(
1
)))
//info:name列的值
put.add(Bytes.toBytes(
"info"
),Bytes.toBytes(
"gender"
),Bytes.toBytes(arr(
2
)))
//info:gender列的值
put.add(Bytes.toBytes(
"info"
),Bytes.toBytes(
"age"
),Bytes.toBytes(arr(
3
).toInt))
//info:age列的值
(
new
ImmutableBytesWritable, put)
}}
rdd.saveAsNewAPIHadoopDataset(job.getConfiguration())
}
}
|
学习参考:林子雨大数据原理与应用课件,Chapter5-厦门大学-林子雨-Spark编程基础-第5章-RDD编程(2018年2月).ppt
图片来源:Chapter5-厦门大学-林子雨-Spark编程基础-第5章-RDD编程(2018年2月).ppt
注:本文按照林子雨大数据原理与应用课件,Chapter5-厦门大学-林子雨-Spark编程基础-第5章-RDD编程(2018年2月).ppt来进行学习的,在此期间发现

这种错我发生了好多次,,百度了也没找到结果。。。