机器学习初探
1、什么是机器学习
学习指的是一个人在观察事物的过程中所提炼出的技能,相比于学习,机器学习指的就是让计算机在一堆数据中通过观察获得某些经验(即数学模型),从而提升某些方面(例如推荐系统的精度)的性能(可测量的)。
2、机器学习使用的条件
需要有规则可以学习
有事先准备好的数据
编程很难做到
3、机器学习所组成的元素
输入X 输出 Y 目标函数f:X->Y 数据(训练集):D={(x1,y1),(x2,y2),….(xn,yn)}假设(skill):g:X->Y
4、如何使用机器学习
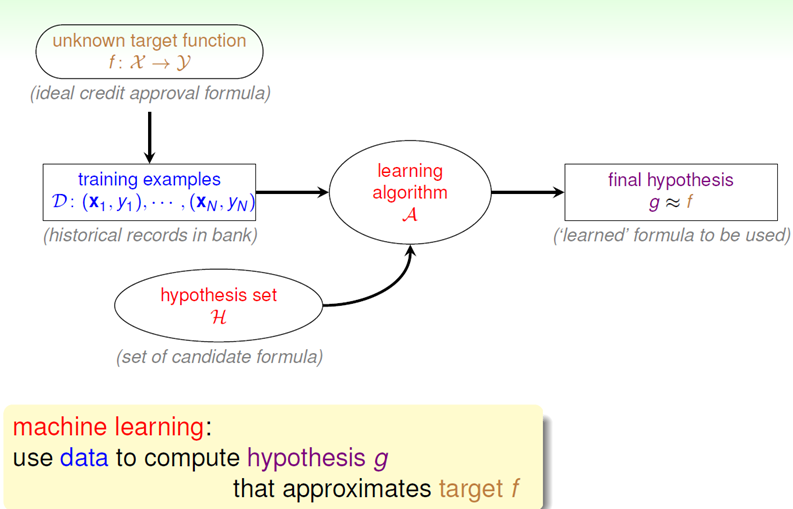
通过两个输入:训练数据集和假设集合(),运用恰当的学习算法,最后得到最终的假设模型g尽量与目标函数f相一致。
PLA算法
课程讲授思路:
- 先举一个案例,是否对客户发放信用卡,引入PLA算法
- 对问题进行数学抽象,得到目标函数
- 详细解释PLA的学习过程
- 证明PLA是否收敛
- 指出PLA的优势和缺陷并引入PA算法
PLA就是一个线性分类器,对所给的结果集进行接受or拒绝划分
对于信用卡申请问题,数学抽象及模型如下:

第一个表达式是信用卡申请问题的数学抽象,即给定客户的特征向量,计算出权重得分,设置一个threshold(即阈值),若特征向量的加权求和得分结果超过阈值,则接受信用卡申请,反之,则拒绝。
第二个表达式则是由此抽象出的数学模型,设置数学符号函数h(x),对特征向量加权求和得分与阈值做差,若大于0,则接受,小于0,则拒绝,最后忽略0
将模型写成点积的形式得:

接下来就是PLA的学习过程:

该算法简单可以概括为,通过不断地修正权重向量W最终找到一条可以将两类结果完全分开的直线,即假设模型g,模型修正方法为:
利用向量相乘的规则,若我们想要的结果为正,而W与X恰巧相反,则我们需要使W接近X,于是使得Wt加上一个正数;若我们想要的结果为负,而Wt与X恰巧接近,则我们需要调整W使得W远离X。
这里有个问题,通过不断地调整W是否会最终找到一个Wt可以将两类结果完全分开,即PLA算法是否会终止,是否是收敛的。
PLA终止的条件为:
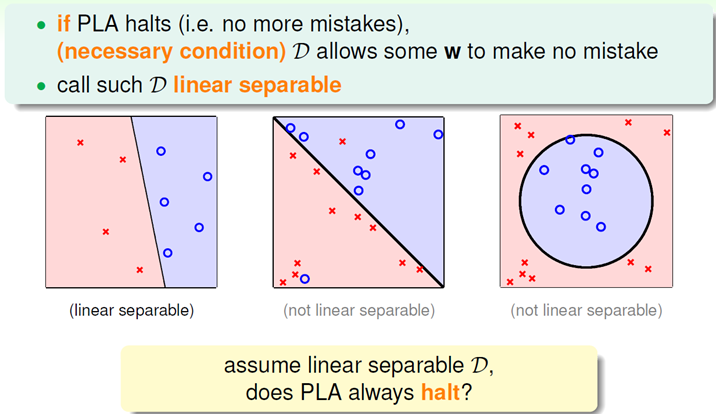
满足这个问题的条件是现有的数据是否线性可分,该课程并未证明这个条件,而是直接证明:linear separable D<=>exists perfect Wf

上图证明Wf与Wt之间是否接近,即将两个向量做了内积,则内积的值越大,表明两个向量越接近或者向量的长度越长,下面要处理向量的长度问题。

利用PLA的“有错才更新”的性质,在犯错误的情况下,通过以上推导,最终得到的结论是,Wt长度的平方在每次更新以后最多增长Xn最长长度的平方。
再利用第一个证明的结论推导得出,推导过程如下:
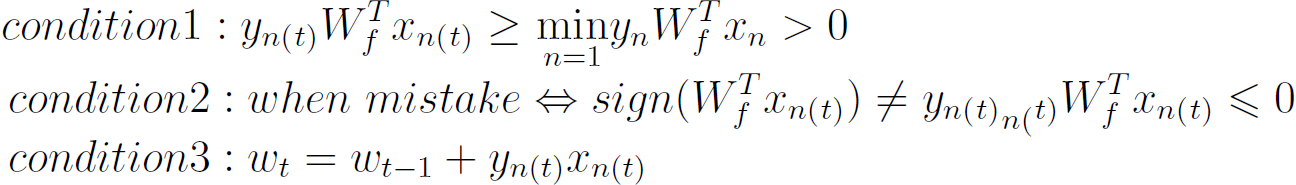
上述为已知的三个条件,有两点需要说明:
1)由于向量夹角的值小于1,所要证明的式子小于1,因此我们只需要证明T也是有边界的,就可以说明该算法是收敛的
2)上式左侧的夹角变得越来越小,即越来越接近,因此我们在使用解决问题的正确方法
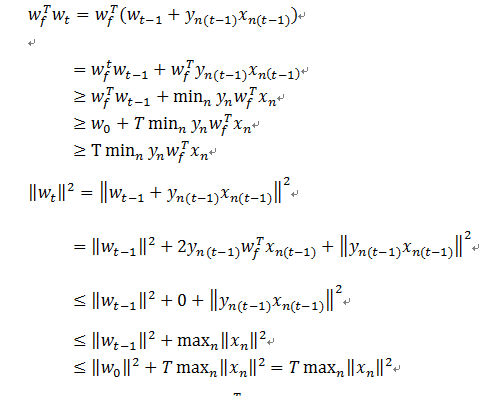
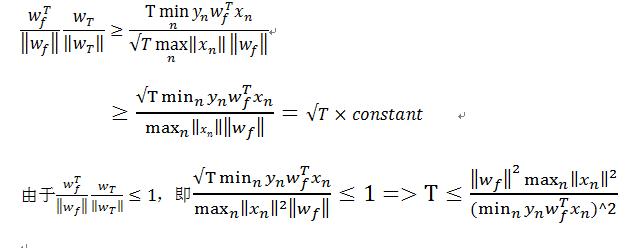
PLA的优缺点:
优点:实现简单,快速,可以在任何维度中实现
缺点:1)需要假设数据是线性可分的
2)不能确定算法会迭代多少次
我们利用贪心算法来解决这个问题,它的本质是逐个对比,取较好的那个结果,实现如下:

台大林轩田老师的讲授技巧很棒,但是这些算法还是要自己去推导才能真正理解。第一次写这类技术博客,很多内容参考的HappyAngel的博客,在此感谢。
*参考资料:
1 Coursera台大机器学习基石
2 HappyAngel博客—-《机器学习定义及PLA算法》*