目标视觉跟踪算法介绍
目标视觉跟踪(Visual Object Tracking),普遍认为可分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪tracking-by-detection,下面我做简单介绍。
generative:在当前帧对目标区域建模,在下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。举个例子,从当前帧知道了目标区域80%是红色,20%是绿色,然后在下一帧,搜索算法就像无头苍蝇,到处去找最符合这个颜色比例的区域,推荐算法ASMS和DAT。
其中,ASMS与DAT都是仅提取颜色特征的算法而且速度很快,依次是VOT2015的第20名和14名,在VOT2016分别是32名和31名(普通水平)。ASMS是VOT2015官方推荐的实时算法,平均帧率125FPS,在经典mean-shift框架下加入了尺度估计,经典颜色直方图特征,加入了两个先验(尺度不剧变+可能偏最大)作为正则项,和反向尺度一致性检查。已经有开源的C++代码:https://github.com/vojirt/asms。
discriminative:OTB50里面的大多数方法都是这一类,也就是CV中的经典套路图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,利用机器学习方法去训练分类器,下一帧用训练好的分类器去寻找最优区域。

与 generative最大的区别是,分类器采用机器学习,训练中用到了背景信息,这样分类器就能专注区分前景和背景,所以判别类方法普遍都比生成类好。举个例子,在训练时告诉tracker目标特征,还告诉它背景中有其他特征,要格外注意区分,这样的分类器知道更多信息,效果也相对更好。其实,tracking-by-detection我已经搞不清楚和检测算法里的区别了不过效果好比什么都强,如经典行人检测使用的是用HOG+SVM,Struck用到了haar+structured output SVM,跟踪中为了尺度自适应也需要多尺度遍历搜索,区别仅在于跟踪算法对特征和在线机器学习的速度要求更高,检测范围和尺度更小而已。这点其实并不意外,大多数情况检测识别算法复杂度都比较高不可能每帧都做,这时候用复杂度更低的跟踪算法就很合适了,只需要在跟踪失败(drift)或一定间隔以后再次检测去初始化tracker就可以了。其实我就想说在工程实际中FPS才是最重要的指标,慢的算法已经不适合我们做实际工程的人去研究,就让那些大神(非人类)去研究,嘻嘻我们只需拿来用就行。经典判别类方法推荐Struck和TLD,都能实时性能还行,Struck是2012年之前最好的方法,TLD是经典long-term的代表,它也是我们接下来需要认真去讲的,它里面的思想是十分值得借鉴的。
其实,现在最为火热的跟踪算法类是相关滤波类方法(correlation filter)简称CF或DCF。其中最经典的相关滤波方法是CSK,KCF、DCF和CN。

是不是看到这张表很兴奋啊,CF算法在precision和FPS都完全碾压其他算法。但是不好意思,我写这篇博客还是主要讲TLD跟踪算法。大家如果想要了解CF算法的话,可以自己去找找资料或者关注我后续的博客。
TLD算法
Tracking-Learning-Detection(TLD)Zdenek Kalal提出的一种对视频中单个物体长时间跟踪的算法,该算法主要由3个部分组成,分别为:跟踪器(tracking),学习模块(learning)和检测器(detection)。下面是算法框架图:

跟踪器
跟踪器的作用是跟踪连续帧间的运动。其工作原理为:利用目标在当前顿的位置估计其在下一帧中的位置,它能够准确跟踪的前提是:目标一直在场景中可见。在TLD算法中,主要用到的是中值光流(Median-Flow)跟踪算法。在进行跟踪前,首先需要选取特征点。TLD跟踪器采用的是光流特征,在选定的跟踪目标框中均匀撒点,最多有10*10共100个特征点。中值光流跟踪算法主要采用以LK光流算法(Lucas-Kanade)进行跟踪,同时利用前后向误差(FB)和特征点前后帧的相似度进行检测和判断。下面是FB误差计算原理图:

TLD算法利用前后向误差进行跟踪的方法为:
(1)对当前要跟踪的点,使用金字塔化光流法跟踪原理预测当前时刻到下一时刻的前向轨迹。
(2)再用与步骤(1)同样的原理,从下一时刻往回跟踪,预测下一时刻到上一时刻的后向轨迹。
(3)计算前向轨迹和后项轨迹的误差,得到FB误差。
(4)对所有点的前向后向误差求和,取其平均值,作为判断前向后向误差是否符合条件的阈值。
(5)再从当前图像帧和前一图像帧,分别特征点作为中心点,提取周围若干单位长度像素矩形,然后对前 后帧的这两个像素矩形进行匹配,得到匹配后的映射图像,最后求出点NCC相关系数,作为相似度。
(6)求出所有点的相关系数,取其平均值,作为相似度的阐值,用来判断匹配的点是否符合条件。
(7)如果某一个点的前向后向误差小于前向后向误差阈值并且该点相似度大于相似度阈值,就保留该特 征点,否则舍弃该点。
(8)根据跟踪成功点的坐标分布,预测出目标框的位置。
(9)如果认为跟踪结果有效,则将目标框对应的图像块归一化大小,并且计算该图像块与样本库目标的相 关相似度,如果相关相似度过小,则认为跟踪器跟踪失败,如果相关相似度大于一定的阀值,则认为跟踪器 跟踪成功。
TLD算法的跟踪器具有计算量小,实时性好,在简单场景下可以稳定的跟踪目标等优点。但是该跟踪器也存在致命的缺点:如果出现跟踪目标从场景中消失再出现的情况,则无法继续跟踪,为了解决该问题,引入了检测器。

检测器
检测器的作用是通过检测方法,在当前帧中搜索目标,找出与目标相似度最大的目标作为本帧的跟踪结果输出。在TLD算法中检测器还具有估计跟踪器误差,如果误差过大,改正跟踪器结果的作用。检测器主要由3个分类器级联而成。这3个分类器分别为;方差分类器,集成分类器和最近邻分类器,这3个分类器是独立运行的。

(1)方差分类器
该分类器主要计算待分类样本像素灰度值的方差,把方差小于目标图像块方差50%的图像块(待分类样本)全部排除。50%是TLD作者自己定义的一个经验值,可根据实际项目进行更改。待检测的滑动窗口数量非常的大,而利用积分图方法计算其方差的速度很快,这样子就能在很短的时间內求出所有的方差,方差描述的是图像片与图像片之间幅度的相似性,选取目标框图像片方差的一半作为阈值的目的是一方面能最大可能过滤掉不符合要求的滑动矩形框,另一方面又能最大可能保证相似的目标框没有被过滤掉,从而最大程度的保留符合条件的目标框。
(2)集成分类器
进入集合分类器的待检测矩形框,都是已经被方差分类器筛选过的。集合分类器相当于决策树构建的森林,决策树用像素的灰度差值来判断不同的属性,决策树信息的采集是在每个在扫描窗口上按照初始化时确定的像素点对来采集的。每一个决策树会根据对应的灰度差值在对应的叶子节点确定结果,所有的结果节点的编码便构成了此棵决策树判断的结果。根据编码求出后验概率,再取森林中的所有这些独立的决策树的后验概率均值。均值大于指定的阔值就认为此扫描窗口有前景目标,通过了集合分类器,否则丢弃掉。
集合分类器有n个基本分类器,每一个分类器有13个判断节点,每个判断节点的特征点是2bitBP特征,每一个节点的判断的结果是0或者1,这样每一个基本分类器就有2^13种可能。求出每一个基本分类器的0 1排列的可能情况,然后求出其后验概率,就是1的个数除于总数13,得出一个后验概率,这样对于一个图像片共有n个后验概率,再求出其后验概率的平均值,如果其后验概率的平均值大于给定的阈值,就认为这个矩形框图像片含有前景目标,予保留否则舍去。
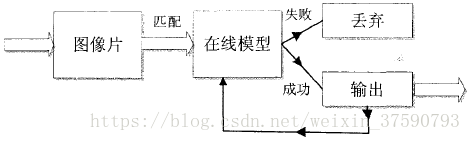
(3)最近邻分类器
最后通过方差分类器与集合分类器后,只剩下非常少的部分扫描窗口。它们会通过最近邻分类器。最近邻分类器有两个功能,一是依次匹配每一个图像块(就是通过的扫描窗口)与在线模型的相似度,二是更新在线模型的正样本空间。具体过程如下图所示:
学习模块
TLD框架中学习模块,它主要有二大功能,其一,完成初始化过程,初始化主要指的是对在线模型、集合分类器和最近邻分类器进行初始化;其二,在TLD算法运行的过程中,更新在线模型的正样本库;其三,反馈训练检测模块中的随机森林分类器和最近邻分类器。它在整个过程中利用P-N学习理论区分正样本和负样本,从而完成相关模块样本库的更新,提高检测的性能。虽然两类专家自身都产生错误,但是P与N是相互独立的,它们又能彼此补偿判断错误。
P-N学习理论:P-N学习是一种半监督学习,P指的是积极(正)约束,其作用是发现当前目标新的特性,以扩展样本中的正样本数,相反,N指的是消极(负)约束,其作用是生成负样本数,前景目标的周围均为负样本。P-N学习受到积极约束与消极约束共同控制,它对得到的结果进行相关的评估,寻找那些与约束条件相矛盾的样本,将这些样本重新训练,直到满足某个条件为止。由于在跟踪目标的时候,其目标的形态容易改变,跟丢的情况时有发生,如果对跟踪的目标进行P-N学习检测,将能动态改变判决条件提高检测的准确率。
P-N学习主要过程如下:(1)准备少量的标记过的训练样本和大量需要测试的样本集;(2)初始化分类器使用标记过的样本,并对约束条件进行修正;(3)用分类器对测试的数据标签标记,找出和约束条件矛盾的样本;(4)将出现矛盾的样本予以修正,添加到训练集,重新训练分类器。(5)反复重复上述过程,直到满足相关条件。具体见下图所示:

P-N学习由四部分构成:1、分类器—将没有标记的数据进行分类。2、训练集—存放要训练的正负样本。3、监督训练—训练改善分类器性能。4、P-N专家——在学习修正训练集中的正负样本。
看前面是不是看得有点懵,在这我举个小栗子,假设对于一个要跟踪的视频目标,在这个视频目标中,存在有大量相关特征点,它们构成一个样本。在这些样本中有少量样本集合是被标记的标签,大量的样本是没有被标记待测的样本。P-N学习就是通过送些少量被标记的样本训练学习得到一个分类器,然后用这个分类器对大量未标记的样本进行测试,然后重新调整训练样本,进一步重新训练分类器,通过这样逐渐改进分类器的性能,提高准确度。通过这个例子,我们可以看出P专家增加了分类器的鲁棒性,N专家增加了分类器的判别能力。
P-N理论在学习模块的应用:首先是如何产生大量的正负样本问题。具体步骤如下:在初始化的时候,会产生大量的滑动窗口,一一计算出滑动窗口与框定的目标框的重叠度,挑选出重叠度最好的若干个目标框作为训练的正样本,挑选出重叠度很低的矩形框的作为训练的负样本。随后将上述的负样本分为两部分,用其中的一部分负样本和所有正样本來训练分类器;在初始训练分类器的时候会给定一个初始经验阈值,利用P-N学习理论对正负样本进行划分,然后根据给定的正样本和负样本来不断纠正阈值,直到训练完所有的样本,最后在将剩余的一部分没有使用的负样本来检测训练的效果进一步纠正改善训练器的效果。

当集合分类器和最近邻分类器都利用初始条件训练好了以后,就可用它来对每一帧运行过程中生成的滑动窗口进行检测,如果最后通过所有通过分类的滑动窗口满足一定的条件后,又可用这些满足条件的图像片作为样本来通过学习模块进一步训练分类器。这样每到视频序列每次走过一帧时,重复上述过程,集合分类器和最近邻分类器的阈值就能不断的进行修正,从而动态的保证这个过程最佳。
综合模块
综合模块是跟踪、检测结果汇总输出。检测模块会影响到跟踪模块的最终结果,没有跟踪到目标也有可能最终通过检测模块得到目标框,跟踪模块和检测模块共同定位输出的跟踪目标框位置。

TLD算法综合模块的处理框架。首先,求得所有通过的检测模块(就是成功通过兰大分类器后的)的矩形框两两之间的重爵度和其相似度,然后将重叠度和相似度进行聚类得到聚类后的重叠度与相似度,将此结果保存;其次,求出跟踪模块的重叠度与相似度,将结果予保存。最后对两个结果进行比对,综合相关条件进行判断,从而输出最后定位的目标框位置。
综合模块将跟踪与检测模块的结果予以汇总判断,完成定位跟踪目标的边界框。按照检测模块能否检测成功,跟踪模块是能否跟踪成功的原则,两两进行组合。会有四种情况,即就是跟踪成功检测成功;跟踪成功检测失败;跟踪失败检测成功;跟踪失败检测失败。
(1)跟踪成功检测成功
检测成功指的是至少有一个滑动窗口通过检测模块,所以根据通过通过检测的滑动窗口数量,分为3种情况考虑。一是,如果通过后只有一个矩形框,不进行聚类,直接计算相关相似度,得到的信息直接进入信息综合判定处。二是,如果通过后有两个矩形框,则首先计算两个矩形框的重叠度,再计算相似度,最后将他们的结果聚类输出到信息综合判定处。三是,如果通过后的矩形框多于两个,则分别计算窗口两两之间的重叠度,按照重叠度与阈值的关系将其分为多个等价类。为了便于理解,特举一实例。如果此时通过检测模块后有七个矩形框,通过计算两两间的重叠度并与阈值相比较,发现1,2,3是一类计为A类,4,5是一类计为B类,6,7是一类计为C类,这个过程就完成了聚类。然后统计出A类、B类、C类的相关信息,如坐标信息,高度、宽度,保守相似度等。对于每一种类型信息求其平均值作为最终的参数值保存输出到信息综合判定处。
另一方面,跟踪模块也有通过的矩形框。计算通过检测模块的矩形框与通过跟踪模块的矩形框的重叠度。如果重叠度很小但是通过检测模块矩形框的保守相似度大于通过跟踪模块矩形框的保守相似度,这时候认为寻找成功了一个聚类中心离跟踪模块得到的矩形框距离较远但是比跟踪模块更加可信。这时候重新用检测模块的那个矩形框的参数重新初始化跟踪器,并输出定位目标。如果重叠度很大则将通过检测模块的矩形框和通过跟踪模块的矩形的信息值按照权位值累加方式求其平均值,其中跟踪模块占据的比重大,检测模块占据的比重小,即就是检测模块辅助纠正跟踪模块定位的矩形框。
总之如果有跟踪到目标框并检测到目标框,那么对检测到的结果聚类得到相关输出结果,判断聚类中心、与跟踪器的重叠率和可信度,如果两者重叠度低且检测模块的可信度更高,那么用检测模块的结果修正跟踪模块的结果,也即用检测器修正跟踪器;如果重叠率接近,那么用检测器和跟踪器结果加权平均得到结果作为最终输出结果,其中跟踪器的权重更大。
(2)跟踪成功检测失败
如果特征矩形框通过跟踪模块后,跟踪成功。但是检测器分类后没有矩形框,这时候认为跟踪成功,直接将跟踪成功的矩形框输出作为最终的定位目标框的参数。
(3)跟踪失败检测成功
如果跟踪模块跟踪失败,但是通过检测模块有至少一个矩形框检测成功。将检测模块的矩形框进行聚类,如果最终聚类的结果只有一个聚类中心,则用此聚类的结果重新初始化跟踪模块,并将聚类的结果作为定位输出结果。如果聚类中也有多个,说明虽然通过了检测器,但是有多个不同的位置,也认为检测失败,不输出结果。
(4)跟踪失败检测失败
如果跟踪和检测模块均失败了,则认为此次检测之间无效,丢弃。
对于综合模块来说,其实就是用跟踪模块和检测模块的结果进行综合考虑,前提是检测器有检测到目标框的结果,对目标框进行聚类得到聚类结果,然后根据跟踪器的结果的情况来分析:如果根据模块跟踪的结果存在,观察跟踪模块与检测模块聚类后的重叠率,如果重叠率低但是检测模块的可信度高,用检测模块聚类后的结果去修正跟踪模块的参数;如果重叠率接近,将跟踪模块的结果和检测模块聚类后加权平均得到当前倾跟踪结果的输出结果,但是跟踪器权重较大;如果跟踪模块没有跟踪到目标框,看检测模块中聚类结果是否只有一个中心,则其为当前帧跟踪结果,如果不只一个中心则将聚类结果丢弃,当前帧没有跟踪到。
TLD开源代码:
给几个开源的代码。
https://www.cnblogs.com/molakejin/p/7396132.html