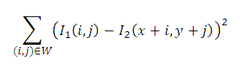跟踪部分
代码解读:
tld_utils.h
#include "opencv2/opencv.hpp"
#pragma once
void drawBox(cv::Mat& image, CvRect box, cv::Scalar color = cvScalarAll(255), int thick=1);
void drawPoints(cv::Mat& image, std::vector<cv::Point2f> points,cv::Scalar color=cv::Scalar::all(255));
cv::Mat createMask(const cv::Mat& image, CvRect box);
float median(std::vector<float> v);
std::vector<int> index_shuffle(int begin,int end);
tld_utils.cpp
#include <tld_utils.h>
using namespace cv;
using namespace std;
/*vector是C++标准模板库STL中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的
模板类和函数库。vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,
简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。
为了可以使用vector,必须在你的头文件中包含下面的代码:
#include <vector>
vector属于std命名域的,因此需要通过命名限定,如下完成你的代码:
using std::vector;
*/
void drawBox(Mat& image, CvRect box, Scalar color, int thick){
rectangle( image, cvPoint(box.x, box.y), cvPoint(box.x+box.width,box.y+box.height),color, thick);
}
//函数 cvRound, cvFloor, cvCeil 用一种舍入方法将输入浮点数转换成整数。
//cvRound 返回和参数最接近的整数值。 cvFloor 返回不大于参数的最大整数值。
//cvCeil 返回不小于参数的最小整数值。
void drawPoints(Mat& image, vector<Point2f> points,Scalar color){
for( vector<Point2f>::const_iterator i = points.begin(), ie = points.end(); i != ie; ++i )
{
Point center( cvRound(i->x ), cvRound(i->y)); //类似于int i(3)的初始化,但center为何没用到?
circle(image,*i,2,color,1);
}
}
Mat createMask(const Mat& image, CvRect box){
Mat mask = Mat::zeros(image.rows,image.cols,CV_8U);
drawBox(mask,box,Scalar::all(255),CV_FILLED);
return mask;
}
//STL中的nth_element()方法找出一个数列中排名第n的那个数。
//对于序列a[0:len-1]将第n大的数字,排在a[n],同时a[0:n-1]都小于a[n],a[n+1:]都大于a[n],
//但a[n]左右的这两个序列不一定有序。
//用在中值流跟踪算法中,寻找中值
float median(vector<float> v)
{
int n = floor((double)v.size() / 2);
nth_element(v.begin(), v.begin()+n, v.end());
return v[n];
}
//<algorithm> //random_shuffle的头文件
//shuffle 洗牌 首先简单的介绍一个扑克牌洗牌的方法,假设一个数组 poker[52] 中存有一副扑克
//牌1-52的牌点值,使用一个for循环遍历这个数组,每次循环都生成一个[0,52)之间的随机数RandNum,
//以RandNum为数组下标,把当前下标对应的值和RandNum对应位置的值交换,循环结束,每个牌都与某个
//位置交换了一次,这样一副牌就被打乱了。 理解代码如下:
/*
for (int i = 0; i < 52; ++i)
{
int RandNum = rand() % 52;
int tmp = poker[i];
poker[i] = poker[RandNum];
poker[RandNum] = tmp;
}
*/
//需要指定范围内的随机数,传统的方法是使用ANSI C的函数random(),然后格式化结果以便结果是落在
//指定的范围内。但是,使用这个方法至少有两个缺点。做格式化时,结果常常是扭曲的,且只支持整型数。
//C++中提供了更好的解决方法,那就是STL中的random_shuffle()算法。产生指定范围内的随机元素集的最佳方法
//是创建一个顺序序列(也就是向量或者内置数组),在这个顺序序列中含有指定范围的所有值。
//例如,如果你需要产生100个0-99之间的数,那么就创建一个向量并用100个按升序排列的数填充向量.
//填充完向量之后,用random_shuffle()算法打乱元素排列顺序。
//默认的random_shuffle中, 被操作序列的index 与 rand() % N 两个位置的值交换,来达到乱序的目的。
//index_shuffle()用于产生指定范围[begin:end]的随机数,返回随机数数组
vector<int> index_shuffle(int begin,int end){
vector<int> indexes(end-begin);
for (int i=begin;i<end;i++){
indexes[i]=i;
}
random_shuffle(indexes.begin(),indexes.end());
return indexes;
}
LKTracker.h
#include"tld_utils.h"
#include "opencv2/opencv.hpp"
//使用金字塔LK光流法跟踪,所以类的成员变量很多都是OpenCV中calcOpticalFlowPyrLK()函数的参数
class LKTracker{
private:
std::vector<cv::Point2f> pointsFB;
cv::Size window_size; //每个金字塔层的搜索窗口尺寸
int level; //最大的金字塔层数
std::vector<uchar> status; //数组。如果对应特征的光流被发现,数组中的每一个元素都被设置为 1, 否则设置为 0
std::vector<uchar> FB_status;
std::vector<float> similarity; //相似度
std::vector<float> FB_error; //Forward-Backward error方法,求FB_error的结果与原始位置的欧式距离
//做比较,把距离过大的跟踪结果舍弃
float simmed;
float fbmed;
//TermCriteria模板类,取代了之前的CvTermCriteria,这个类是作为迭代算法的终止条件的
//该类变量需要3个参数,一个是类型,第二个参数为迭代的最大次数,最后一个是特定的阈值。
//指定在每个金字塔层,为某点寻找光流的迭代过程的终止条件。
cv::TermCriteria term_criteria;
float lambda; //某阈值??Lagrangian 乘子
// NCC 归一化交叉相关,FB error与NCC结合,使跟踪更稳定 交叉相关的图像匹配算法??
//交叉相关法的作用是进行云团移动的短时预测。选取连续两个时次的GMS-5卫星云图,将云图区域划分为32×32像素
//的图像子集,采用交叉相关法计算获取两幅云图的最佳匹配区域,根据前后云图匹配区域的位置和时间间隔,确
//定出每个图像子集的移动矢量(速度和方向),并对图像子集的移动矢量进行客观分析,其后,基于检验后的云
//图移动矢量集,利用后向轨迹方法对云图作短时外推预测。
void normCrossCorrelation(const cv::Mat& img1, const cv::Mat& img2, std::vector<cv::Point2f>& points1, std::vector<cv::Point2f>& points2);
bool filterPts(std::vector<cv::Point2f>& points1,std::vector<cv::Point2f>& points2);
public:
LKTracker();
//特征点的跟踪??
bool trackf2f(const cv::Mat& img1, const cv::Mat& img2,
std::vector<cv::Point2f> &points1, std::vector<cv::Point2f> &points2);
float getFB(){return fbmed;}
};
LKTracker.cpp
#include <LKTracker.h>
using namespace cv;
//金字塔LK光流法跟踪
//Media Flow 中值光流跟踪 加 跟踪错误检测
//构造函数,初始化成员变量
LKTracker::LKTracker(){
////该类变量需要3个参数,一个是类型,第二个参数为迭代的最大次数,最后一个是特定的阈值。
term_criteria = TermCriteria( TermCriteria::COUNT + TermCriteria::EPS, 20, 0.03);
window_size = Size(4,4);
level = 5;
lambda = 0.5;
}
bool LKTracker::trackf2f(const Mat& img1, const Mat& img2, vector<Point2f> &points1, vector<cv::Point2f> &points2){
//TODO!:implement c function cvCalcOpticalFlowPyrLK() or Faster tracking function
//Forward-Backward tracking
//基于Forward-Backward Error的中值流跟踪方法
//金字塔LK光流法跟踪
//forward trajectory 前向轨迹跟踪
calcOpticalFlowPyrLK( img1,img2, points1, points2, status, similarity, window_size, level, term_criteria, lambda, 0);
//backward trajectory 后向轨迹跟踪
calcOpticalFlowPyrLK( img2,img1, points2, pointsFB, FB_status,FB_error, window_size, level, term_criteria, lambda, 0);
//Compute the real FB-error
//原理很简单:从t时刻的图像的A点,跟踪到t+1时刻的图像B点;然后倒回来,从t+1时刻的图像的B点往回跟踪,
//假如跟踪到t时刻的图像的C点,这样就产生了前向和后向两个轨迹,比较t时刻中 A点 和 C点 的距离,如果距离
//小于一个阈值,那么就认为前向跟踪是正确的;这个距离就是FB_error
//计算 前向 与 后向 轨迹的误差
for( int i= 0; i<points1.size(); ++i ){
FB_error[i] = norm(pointsFB[i]-points1[i]); //norm()求矩阵或向量的范数??绝对值?
}
//Filter out points with FB_error[i] <= median(FB_error) && points with sim_error[i] > median(sim_error)
normCrossCorrelation(img1, img2, points1, points2);
return filterPts(points1, points2);
}
//利用NCC把跟踪预测的结果周围取10*10的小图片与原始位置周围10*10的小图片(使用函数getRectSubPix得到)进
//行模板匹配(调用matchTemplate)
void LKTracker::normCrossCorrelation(const Mat& img1,const Mat& img2, vector<Point2f>& points1, vector<Point2f>& points2) {
Mat rec0(10,10,CV_8U);
Mat rec1(10,10,CV_8U);
Mat res(1,1,CV_32F);
for (int i = 0; i < points1.size(); i++) {
if (status[i] == 1) { //为1表示该特征点跟踪成功
//从前一帧和当前帧图像中(以每个特征点为中心?)提取10x10象素矩形,使用亚象素精度
getRectSubPix( img1, Size(10,10), points1[i],rec0 );
getRectSubPix( img2, Size(10,10), points2[i],rec1);
//匹配前一帧和当前帧中提取的10x10象素矩形,得到匹配后的映射图像
//CV_TM_CCOEFF_NORMED 归一化相关系数匹配法
//参数分别为:欲搜索的图像。搜索模板。比较结果的映射图像。指定匹配方法
matchTemplate( rec0,rec1, res, CV_TM_CCOEFF_NORMED);
similarity[i] = ((float *)(res.data))[0]; //得到各个特征点的相似度大小
} else {
similarity[i] = 0.0;
}
}
rec0.release();
rec1.release();
res.release();
}
//筛选出 FB_error[i] <= median(FB_error) 和 sim_error[i] > median(sim_error) 的特征点
//得到NCC和FB error结果的中值,分别去掉中值一半的跟踪结果不好的点
bool LKTracker::filterPts(vector<Point2f>& points1,vector<Point2f>& points2){
//Get Error Medians
simmed = median(similarity); //找到相似度的中值
size_t i, k;
for( i=k = 0; i<points2.size(); ++i ){
if( !status[i])
continue;
if(similarity[i]> simmed){ //剩下 similarity[i]> simmed 的特征点
points1[k] = points1[i];
points2[k] = points2[i];
FB_error[k] = FB_error[i];
k++;
}
}
if (k==0)
return false;
points1.resize(k);
points2.resize(k);
FB_error.resize(k);
fbmed = median(FB_error); //找到FB_error的中值
for( i=k = 0; i<points2.size(); ++i ){
if( !status[i])
continue;
if(FB_error[i] <= fbmed){
points1[k] = points1[i]; //再对上一步剩下的特征点进一步筛选,剩下 FB_error[i] <= fbmed 的特征点
points2[k] = points2[i];
k++;
}
}
points1.resize(k);
points2.resize(k);
if (k>0)
return true;
else
return false;
}
/*
* old OpenCV style
void LKTracker::init(Mat img0, vector<Point2f> &points){
//Preallocate
//pyr1 = cvCreateImage(Size(img1.width+8,img1.height/3),IPL_DEPTH_32F,1);
//pyr2 = cvCreateImage(Size(img1.width+8,img1.height/3),IPL_DEPTH_32F,1);
//const int NUM_PTS = points.size();
//status = new char[NUM_PTS];
//track_error = new float[NUM_PTS];
//FB_error = new float[NUM_PTS];
}
void LKTracker::trackf2f(..){
cvCalcOpticalFlowPyrLK( &img1, &img2, pyr1, pyr1, points1, points2, points1.size(), window_size, level, status, track_error, term_criteria, CV_LKFLOW_INITIAL_GUESSES);
cvCalcOpticalFlowPyrLK( &img2, &img1, pyr2, pyr1, points2, pointsFB, points2.size(),window_size, level, 0, 0, term_criteria, CV_LKFLOW_INITIAL_GUESSES | CV_LKFLOW_PYR_A_READY | CV_LKFLOW_PYR_B_READY );
}
*/转自http://blog.csdn.net/xavieryoung/article/details/58599609
跟踪算法的实现过程分为四个子模块,也就是特征提取、运动模型、观测模型、模型更新。跟踪算法通常在第一帧框选一个跟踪目标,并初始化观测模型,在之后的视频序列中,首先通过运动模型生成目标的候选区域,或者通过前一帧目标的状态估计出一个目标所在的大致区域。之后,将候选区域或者估计区域的图像送入观测模型,计算它们是目标的概率,通过这种方式,相似度最高的图像片即为当前帧跟踪到的目标,基于观测模型的输出结果,模型更新模块进行判定是否需要更新观测模型。
特征提取:
1. 原始灰度:
这种方法只是简单地将图像转化为灰度图并且缩放到统一的大小,使用灰度图像的像素值作为特征。
2. 原始颜色:
该方法与原始灰度特征基本相同,只是使用图像的颜色空间信息代替灰度信息作为图像特征。
3. Haar-like 特征:
即 Haar特征,是一种常用的特征描述算子,由 Papageorigiou 等人提出用于人脸检测。如图 2.3 所示,每一种特征的计算都是由黑色填充区域的像素值之和与白色填充区域的像素值之和的差值,而计算出来的这个差值就是 Haar-like特征的特征值。图2.3中,对于 A,B,D 这种特征,其特征值计算公式为:v=SUM(白)-SUM(黑),对于 C 这种特征,公式为:v=SUM(白)-2*SUM(黑),之所以将黑色区域像素和乘以 2,是为了使两种矩区域中像素数目一致。Haar 特征反映了图像的灰度变化情况,对光照变化和噪声具有将强的鲁棒性。
4. HOG 特征:
方向梯度直方图(HistogramofOrientedGradient),图像的特征由计算并统计图像局部区域的梯度方向直方图来表示,其基本思想是在一幅图像中,局部目标的形状能够被该区域的梯度或边缘的方向密度分布很好的描述。该特征提取的实现过程首先将图像分成小的连通区域,称之为细胞单元。然后统计细胞单元中各像素点的梯度的或边缘的方向直方图,最终的图像特征描述器则是将这些直方图组合起来。
一个 block 的 4 个细胞块的向量相连,得到一个 36 维的 block 向量。最后将图像中所有 block 的向量相连,就得到了整幅图像的 HOG 特征向量。
5. LBP:
LBP 算子定义为在大小为3*3的局部窗口中,以窗口中心点的像素值为阈值,将其相邻的 8 个像素的灰度值与其进行比较,若周围的像素值大于该阈值,则将该像素点的位置标记为 1,否则标记为 0。通过这种方式, 邻域内的 8 个点经过与中心点像素值的比较可产生 8 位二进制数(通常转换为十进制数即 LBP 码,共256种),该十进制数即为该窗口中心像素点的 LBP 值,使用这个值来表示窗口的图像纹理信息
转自http://blog.csdn.net/crzy_sparrow/article/details/7407604
基于特征点的目标跟踪的一般方法
基于特征点的跟踪算法大致可以分为两个步骤:
1)探测当前帧的特征点;
2)通过当前帧和下一帧灰度比较,估计当前帧特征点在下一帧的位置;
3)过滤位置不变的特征点,余下的点就是目标了。
很显然,基于特征点的目标跟踪算法和1),2)两个步骤有关。特征点可以是Harris角点(见我的另外一篇博文),也可以是边缘点等等,而估计下一帧位置的方法也有不少,比如这里要讲的光流法,也可以是卡尔曼滤波法(咱是控制系的,上课经常遇到这个,所以看光流法看着看着就想到这个了)。
光流法
这一部分《learing opencv》一书的第10章Lucas-Kanade光流部分写得非常详细,推荐大家看书。我这里也粘帖一些选自书中的内容。
另外我对这一部分附上一些个人的看法(谬误之处还望不吝指正):
1.首先是假设条件:
(1)亮度恒定,就是同一点随着时间的变化,其亮度不会发生改变。这是基本光流法的假定(所有光流法变种都必须满足),用于得到光流法基本方程;
(2)小运动,这个也必须满足,就是时间的变化不会引起位置的剧烈变化,这样灰度才能对位置求偏导(换句话说,小运动情况下我们才能用前后帧之间单位位置变化引起的灰度变化去近似灰度对位置的偏导数),这也是光流法不可或缺的假定;
(3)空间一致,一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。这是Lucas-Kanade光流法特有的假定,因为光流法基本方程约束只有一个,而要求x,y方向的速度,有两个未知变量。我们假定特征点邻域内做相似运动,就可以连立n多个方程求取x,y方向的速度(n为特征点邻域总点数,包括该特征点)。
2.方程求解
多个方程求两个未知变量,又是线性方程,很容易就想到用最小二乘法,事实上opencv也是这么做的。其中,最小误差平方和为最优化指标。
自我总结(http://blog.csdn.net/sinat_31135199/article/details/70739106)
TLD跟踪算法运用LK光流法正向追踪这些点到t+1帧,再反向追踪到t帧,计算FB误差,筛选出FB误差最小的一半点作为最佳追踪点。最后根据这些点的坐标变化和距离的变化计算t+1帧包围框的位置和大小(平移的尺度取中值,缩放的尺度取中值。取中值的光流法,估计这也是名称Median-Flow的由来吧)。
还可以用NCC(Normalized Cross Correlation,归一化互相关)和SSD(Sum-of-Squared Differences,差值平方和)作为筛选追踪点的衡量标准。作者的代码中是把FB误差和NCC结合起来的,所以筛选出的追踪点比原来一半还要少。
NCC:
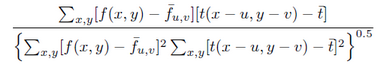
SSD: