目标检测与跟踪作为计算机视觉领域重点难点之一,一直一来受到广泛的关注与研究。目前,运动物体的检测与跟踪主要运用与人机交互、智能家具、视频监控等领域。尽管目标检测与跟踪发展迅速也提出了很多有效的方法。但在实际应用中任然存在各种困难,如跟踪目标体积变化,周围环境突变,跟踪目标被遮挡等。
目前主流的跟踪算法基本都基于检测跟踪,TLD就是基于检测的跟踪算法,TLD(Tracking-Learning-Detection)跟踪算法对长时间跟踪有较好的鲁棒性,因而受到广泛关注,然而TLD算法也存在着自身的不足,如目标物体被遮挡时,形态变化,光照变化,TLD就无法预测与跟踪目标。
本文主要想通过加入卡尔曼滤波来改进TLD算法,通过减少检测的窗口数量,从而减少检测目标花费的时间,并且提高对小区域目标的跟踪的鲁棒性,卡尔曼滤波预测目标状态也可以解决目标物体被遮挡的情况。在该算法中也加入了人脸检测算法,可以实现对人物的追踪。
Tracking-Learning-Detection介绍
当我们在进行物体追踪的时候,追踪目标无可避免的会发生形变,从当前帧中消失,消失目标在过段时间后再次出现,对于这样的情况,传统的算法都是采用先对追踪目标进行训练,然后在追踪的过程中将视频中的物体与训练的样本进行对照,如果对比成功,则追踪到目标,如果对比失败,则追踪失败,这样的机制灵活性较差。而Tracking-Learning-Detection(TLD)算法即可适应与长时间跟踪也可以解决传统算法的不足问题,因而受到广泛的关注[5]。该算法主要有检测器,跟踪器,学习器[11]三个部分组成。跟踪器通过上一帧和当前帧采用金字塔光流calcOpticalFlowPyrLK来跟踪目标,若目标消失则跟踪失败。而检测器采用扫描整个窗口的策略来检测当前帧中是否存在目标,最后综合模块对检测器检测到的目标与跟踪器追踪到的目标进行综合验证,输出两种方法的最有值,从而确认目标的位置。学习器通过Positive-Negative学习,对分类器进行不断的改正,从而提高检测器的正确率。TLD算法由于是对每一帧都采取全部扫描因此具有良好的重检测能力,但是由于是对整个窗口进行扫描,难免会比较耗时,并且无法应对遮挡等问题
TLD模型
Tracking-Learning-Detection(TLD)主要由跟踪器,检测器,学习器三个部分组成的一种在线单目标检测跟踪算法。模型图如图所示。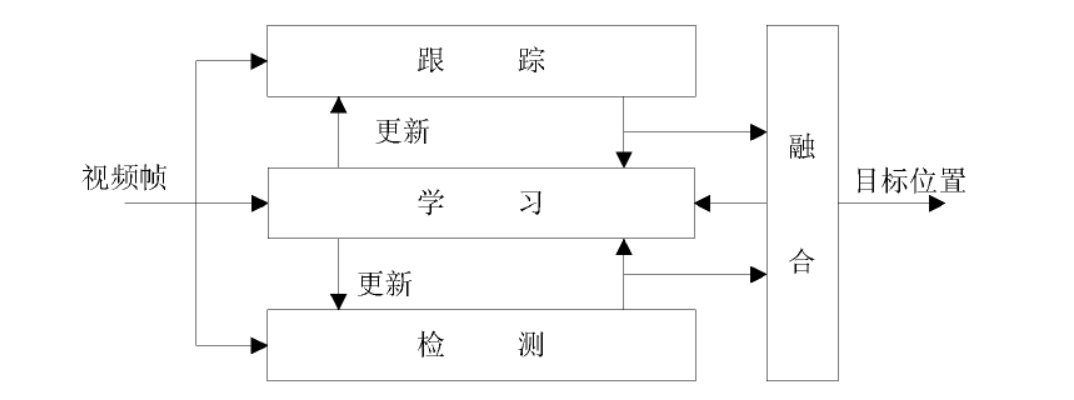
跟踪器主要采用金字塔光流calcOpticalFlowPyrLK进行前向追踪和后向追踪来跟踪目标。原理较为简单:假如对图像上的A点进行跟踪,首先获取A点的位置,然后利用金字塔光流法来判断A点在当前帧中的位置B,然后利用同样的原理使用B点来反向预测A点的位置A’然后计算A点与A’点的距离FB_Error,如果距离FB_error小于一定的阈值,则表明该点追踪成功,如果FB_error的距离大于一定的阈值,则表明对该点的追踪失败,在从而通过上一帧可以检测出当前帧的位置,但是跟踪器无法对丢失的目标进行重新恢复跟踪。
检测器主要采用扫描整个窗口的策略来检测当前帧中是否存在检测目标。可以通过检测器对丢失的目标进行重新检测。
学习器主要是对通过检测器与跟踪器所跟踪的目标对分类器进行不断的改正,从而提高检测器的正确率。
检测器介绍
检测器是一种级联分类器,主要由方差检测模块,集合分类器检测模块,最近邻分类器检测模块组成。如图所示。
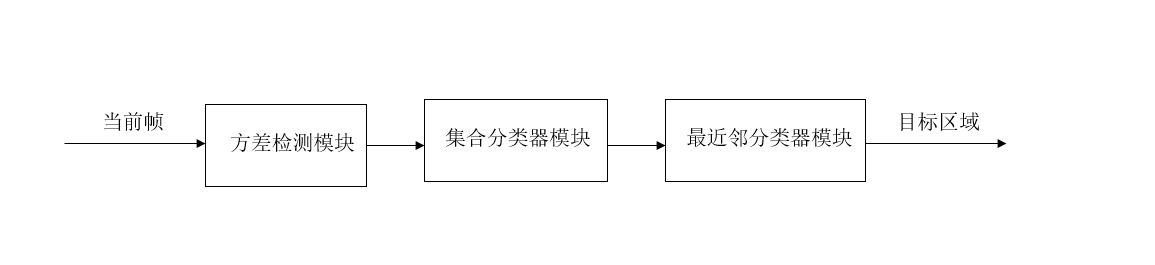
TLD将整个图像作为目标候选区域,当目标候选区域中的某一块区域全部通过方差检测模块,集合分类器模块,最近邻分类器模块时该区域才可能是目标区域。而只要有一项无法通过,则被认为不是目标区域。
方差检测模块原理:首先求出待测窗口的方差然后与目标图像框的方差的一半做对比,如果方差大于该阈值,则通过方差分类器,如果方差小于该阈值,则不通过方差分类器。
集合分类器原理:图像区域输入到集合分类器后,会得到相应的后验概率,通过后验概率的大小来判断是否通过。
最近邻分类器原理:将通过方差分类器,集合分类器的图片作为最近邻分类器的素材,判断图像区域与目标区域的相似度,用过NNConf函数处理
跟踪器介绍
跟踪器主要采用金字塔光流calcOpticalFlowPyrLK进行前向追踪和后向追踪来跟踪目标,光流法是一种简单实用的图像运动表达方式,即空间运动物体表面上的点在视觉传感器成像表面上的体现。在TLD算法中,首先在目标区域中选取特征点(最多100个特征点),首先采用前向轨迹跟踪,假设当前帧了F1,下一刻的帧为F2,通过F1中的特征点来预测F2中的特征点,然后得到F2中特征点的位置 ,然后采用后向轨迹跟踪,由F2中的特征点方向预测F1中的特征点。通过这种向前向后的轨迹预测来得出位移偏差。如果反向预测的特征点的位置与原有特征点的位置位移偏差大于阈值,则认为该特征点追踪失败。然后使用预测正确的点来预测当前帧中目标的大小及位置。具体例子如图
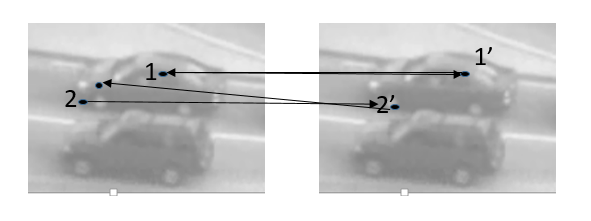
如图所示:当对点1采用前向轨迹跟踪获得1’点,对1’点采用后向轨迹跟踪得到的位置与1位置重合,则说明1特征点追踪成功。而对2特征点采取前向轨迹跟踪获取到2’点,对2’点采用后向轨迹跟踪获取的位置与原有2的位置有较大距离,则舍去该特征点。
综合模块介绍
综合模块主要是对跟踪模块与检测模块所检测的结果值进行判断。一般有四种情况:
(1)跟踪器跟踪成功检测器也检测到目标。首先对检测器所检测到的目标框进行聚类,然后计算检测器检聚类后的框与跟踪器跟踪的目标框的重叠度,如果重叠度小于0.5而检测器保守相似度大于跟踪器的保守相似度,则表示找到一个聚类后的目标框比跟踪器追踪到的目标的可靠性更好,如果只有一个那么就使用检测器检测的来初始化跟踪器。
(2)跟踪器跟踪失败检测器检测到目标。跟踪器跟踪失败,检测器监只检测到一个比较可靠的矩形框,则使用该矩形框来初始化跟踪器。如果有多个矩形框通过检测器,则也不出理。
(3)跟踪器跟踪成功检测器没有检测到目标。如果跟踪器跟踪成功,检测器没有检测到可靠的矩形框,则认为跟踪成功,并且输出跟踪器跟踪到的目标。
(4)跟踪器跟踪失败检测器也没有检测到目标,则认为跟踪失败。
学习器介绍
Tracking-Learning-Detection(TLD)的学习器又叫做P-N(Positive-Negative)学习。P-N学习主要通过标记样本和未标记样本来学习分类器。P-N学习主要包括两种结构约束正约束(Positive约束)和负约束(Negative约束)。所谓正约束就是将未标记样本标记为正样本的条件,TLD将靠近运动轨迹的样本标记为正样本,负约束条件就是将未标记样本标记为负样本的条件,TLD中将远离运动轨迹的样本标记为负样本。通过正样本与负样本的相互不断约束,从而提高了正样本的可信度。
假设x是样本库X中的一个样本,y是标号空间Y={0,1}(0为负样本标识,1为正样本标识)的一个标识。集合{Xi,Yi}则表示x样本与y标识所组成的标号集。而{Xi,Yi}则就是P-N建立及训练分类器的素材,然后通过为标记的Xu来提高分类器的性能。P-N学习步骤如图所示:
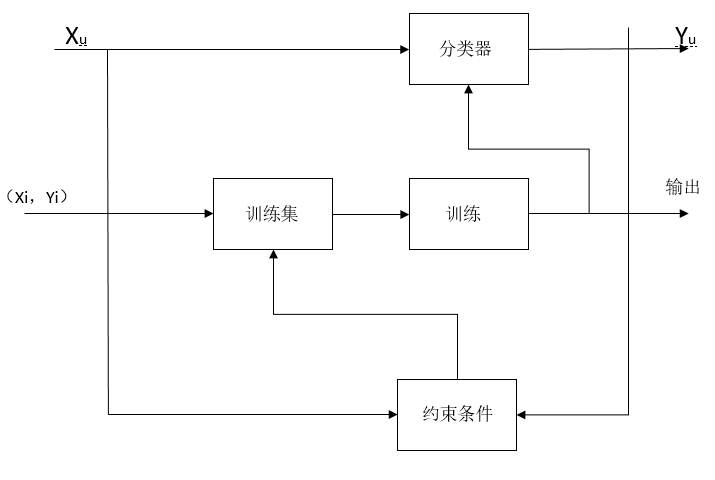
P-N学习首先在初始化时利用标识的正样本与负样本建立分类器然后重复下列几个步骤:
(1) 利用初始建立的分类器对未进行标识的样本进行分类标识;
(2) 通过结构约束对分类标识的样本进行验证,然后分类错误的进行重新标识;
(3) 将通过上述的标识样本加入训练集;
(4) 重新训练分类器。
约束条件的功能:
Xk为将要通过分类器的样本,在通过分类器进行标记后(Xk,Yk),则约束条件的功能就是对分类器进行标记后(Xk,Yk)进行验证是否标识错误然后进行纠正。P约束用于鉴别通过分类器后被标识为负样本,但根据约束条件该样本为正样本,则将该样本修改为正样本,在n次迭代后,P约束条件增加正样本到正样本集中,从而提高扩展正样本集。正约束用于鉴别通过分类器后被标识为负样本,但根据约束条件该样本为负样本,则将该样本修改为负样本,在n次迭代后N约束条件增加负样本到负样本集中,从而提高扩展负样本集,从而提高了负样本的判别属性。总之,在整个过程中,P-N约束就是对通过分类器标识的样本进行纠正,将被分类器分类错误的样本进行重新标识。从而提高样本的可信度。
TLD主要函数分析
(1) 分类器初始化classifier.prepare(scales)函数介绍
该函数传入的scales是一个constvector<Size>类型的数组,该数组里存放的是扫描窗口的大小该函数主要有以下几个功能:1向每一个扫描窗口中填充totalFeatures = nstructs * structSize共130个特征点,TLD中第s种尺度的第i个特征表示为features[s][i] = Feature(x1, y1, x2, y2),x1,y1, x2, y2为两个随机像素点的坐标。2初始化后验概率,每个后验概率都得初始化为0;运行时候在更新。
(2) 正样本generatePositiveData(frame1,num_warps_init)函数介绍
该函数在初始化时通过第一帧样本框Box里的样本来初始化正样本集。具体步骤如下:1首先求出目标图像的标准差和均值和将目标图像归一化为均值为0大小15*15大小的patch;2获取目标图像的中心点坐标作为放射变化的坐标;3对图像进行仿射变换,由函数generator(frame,pt,warped,bbhull.
size(),rng)完成 放射变换,主要生成200个正样本。
(3) 负样本generateNegativeData(frame1)函数介绍
TLD中将检测框中与目标框重叠度小于0.2的作为负样本。对负样本中方差大于var*0.5f的bad_boxes都加入负样本,具体生成负样本的步骤如正样本生成方法一样,只是不需要进行放射变换。共生成100个负样本。
(4) getOverlappingBoxes(box, num_closest_init)函数介绍
此函数根据传入的目标框,在图像中的待扫描窗口中寻找与该目标框重叠度最大的10个num_closest_init窗口,然后把这些窗口归入good_boxes容器。同时,把重叠度小于0.2的,归入bad_boxes容器;相当于对全部的扫描窗口进行筛选。为后边的正负样本的提供素材。
(5) getBBHull()函数介绍
该函数用于找出所有goodbox的做大外接矩形。
(6) trackf2f(img1,img2,points,points2);函数介绍
Track函数主要是完成point1到point2的追踪。主要步骤如下:
1首先在上一帧的目标框中中取特征点(最多100个),存放于point1数组里。
2利于光流金字塔calcOpticalFlowPyrLK对img1上的point1预测在img2上的点存放于point2中,然后通过img2上 point2上的点反向追踪img1上的点存放于pointsFB数组中。
3计算point1[i]中各点的位置与pointsFB[i]中各点的位置距离,存放于FB_error[i]。
4筛选出 FB_error[i] <= median(FB_error) 和 sim_error[i] > median(sim_error) 的特征点即舍弃跟踪结果不好的特征点。
(7) bbPredict(points,points2,lastbox,tbb);
该函数是利于跟踪到的点来预测目标在当前帧中的位置原理如下:
1计算出points于points2中每个特征点在x方向和y方向的偏移值并存于xoff[i]和yoff[i]中。
2求出在x方向和y方向的偏移中值。
3计算出当前特征点之间的距离与先前特征点之间的距离比值norm(points2[1]-points2[2])/norm(points1[1]-points1[2,norm(points2[1]-points2[3])/norm(points1[1]-points1[3]),norm(points2[1]-points2[4])/norm(points1[1]-points1[4])……。
4求出比值的中值作为变化因子。
5计算得出当前帧中目标框的大小。二、人脸检测的实现
本项目所使用的人脸检测主要使用opencv提供的方法与训练好的haarcascade_frontalcatface.xml级联分类器来进行人脸的检测。人脸检测步骤:
(1)加载级联分类器;CascadeClassifier face_cascade;
face_cascade.load("haarcascade_ frontalcatface.xml");
(2)读入视频;
(3)对读入的每一帧图像,首先将图像转化为灰度图,然后对转化为灰度图的图像进行直方图均衡化便于检测人脸。调用detectMultiScale函数,函数详情如下:
void detectMultiScale(
const Mat& image, //待检测灰度图像
CV_OUT vector<Rect>& objects, //被检测物体的矩形框向量
double scaleFactor = 1.1, //扫描窗口的比列系数,默认为1.1,
int minNeighbors = 3, //构成检测目标的相邻矩形的最小个数
int flags = 0,
Size minSize = Size(),
Size maxSize = Size()
);
(4)将检测到的人脸显示在窗口上。三 、加入卡尔曼滤波后的TLD
卡尔曼滤波介绍
卡尔曼滤波是kalman于1960年提出的一种状态评估的方法,可以通过上一时刻的状态预估当前时刻的状态,由于通过观察值和预测值不断对卡尔曼方程做调整,因此卡尔曼滤波具有良好的评估能力。卡尔曼滤波主要运用于目标跟踪,计算机视觉,航天等领域。
卡尔曼滤波的数学模型主要由两部组成:
状态方程:xk =Axk-1+Buk-1+wk-1 (公式4-1-1)
观测方程:zk=Hxk+vk (公式4-1-2)
式中xk 表示k时刻的状态,A表示状态转移矩阵,B为控制矩阵,wk-1表示系统误差,zk 为测量状态,H为测量矩阵,vk为测量误差。
目标跟踪的实质就是获取目标在每一帧图像中的具体位置。因此选取每帧图像的中心位置来当作卡尔曼滤波的观测量于状态量。
假设K时刻目标中心的位置为(Xk ,Yk )速度为(Vxk ,Vyk ),Xk为运动目标在X方向的位置,Yk为运动目标在Y方向的位置,Vxk 表示在K时刻运动目标在X方向的速度,Vyk表示在K时刻运动目标在Y方向的速度。即系统状态量方程为:
Xk=[Vxk-1 ,Vyk-1 , Vxk-1 ,Vyk-1 ]T (公式4-2-1)
观测量为:
Zk=[Vxk ,Vyk]T (公式4-2-2)
在运用中由于每一帧之间的时间间隔非常短,所以可以假设运动目标在每一帧之间的运动式加速运动,则根据牛顿定律Xk=Xk-1+Xk-1t+Wk-1t2/2, Xk 为k时刻的位置,Xk-1为k-1时刻的位置,t为时间Wk-1为加速度。 则可得状态转移矩阵:
A=

控制矩阵:
B=

TLD是通过扫描窗口的形式检测每一帧中是否含有运动目标,通过
const float SHIFT = 0.1; //扫描窗口的移动比为10%
const float SCALES[] = { // 存放的为尺度变换比例为1.2倍(0.16151*1.2=0.19381)
共21种尺度变换:
0.16151,0.19381,0.23257,0.27908,0.33490,0.40188,0.48225,0.57870,0.69444,0.83333,1,1.20000,
1.44000,1.72800,2.07360,2.48832,2.98598,3.58318,4.29982,5.15978,6.19174};
对窗口进行划分,对于340*240的窗口大约会产生六万多个待扫描窗口,计算任务之庞大,大大降低了程序的运算速度。为此通过卡尔曼滤波来预测当前窗口目标中心可能的位置。以该预测位置为中心将预测目标窗口扩大为上一帧检测窗口的2倍,然后将与预测窗口重叠度大于0.1的窗口,送进检测器进行检测,这样大大降低了检测窗口的数量。
卡尔曼主要算法解析
以下为卡尔曼滤波的初始化函数
KalmanFilter KF(4, 2, 0);
KF.transitionMatrix = *(Mat_<float>(4, 4) << 1, 0, 1, 0, 0, 1,0, 1, 0, 0, 1, 0, 0, 0, 0, 1); // 转移矩阵 A
KF.measurementMatrix = *(Mat_<float>(2, 4) << 1, 0, 0, 0, 0, 0,0, 1); //测量矩阵H
setIdentity(KF.measurementMatrix); //测量矩阵H
setIdentity(KF.processNoiseCov, Scalar::all(1e-5)); /系统噪声方差矩阵Q
setIdentity(KF.measurementNoiseCov, Scalar::all(1e-1)); //测量噪声方差矩阵R
setIdentity(KF.errorCovPost, Scalar::all(1)); //后验错误估计协方差矩阵P
float X = box.x + box.width / 2;
float Y = box.y + box.height / 2;
if (X < 0)X = 0.0;
if (Y < 0)Y = 0.0;
KF.statePost = *(Mat_<float>(4, 1) << X, Y, 0, 0); // 系统初始状态 x(0)
Mat measurement = Mat::zeros(2, 1, CV_32F);//定义初始测量值 z(0)
measurement.at<float>(0) = (float)X;
measurement.at<float>(1) = (float)Y;
(1)定义卡尔曼滤波,并初始化状态参数为4,观测参数为2;
(2)初始化转移矩阵A即在4.2节中所得到的A矩阵;
(3)初始化测量矩阵B即在4.2节中所得到的B矩阵;
(4)将系统的初始目标中心点X,Y方向速度为0作为卡尔曼滤波的初始状态值;
(5)将初始目标中心点作为观测值。
卡尔曼滤波器预测
Mat prediction =KF.predict();
PreBox.x = (prediction.at<float>(0) - box.width)>0?(prediction.at<float>(0) - box.width ):0;
PreBox.y = (prediction.at<float>(1) - box.height )>0 ?(prediction.at<float>(1) - box.height) : 0;
PreBox.width = box.width * 2 + PreBox.x > frame.cols ? frame.cols -PreBox.x : box.width * 2;
PreBox.height = box.height * 2 + PreBox.y>frame.rows ? frame.rows -PreBox.y : box.height * 2;
定义Rect变量PreBox来存储卡尔曼滤波器所预测的运动目标位置。prediction.at<float>(0)为预测结果的X坐标,prediction.at<float>(1)为预测结果的Y坐标。
卡尔曼更新
if (status){
//将上一帧的lastbox中心作为观测值
X = tld.lastbox.x + tld.lastbox.width / 2;
Y = tld.lastbox.y + tld.lastbox.height / 2;
}
else
{
X =prediction.at<float>(0);
Y =prediction.at<float>(1);
}
measurement.at<float>(0) = (float)X;
measurement.at<float>(1) = (float)Y;
KF.correct(measurement);//跟新
当运动目标跟踪良好时,将跟踪目标的中心值作为观测值带入卡尔曼滤波进行迭代更新,当运动目标跟踪失败时将预测值作为观测值带入卡尔曼滤波进行迭代更新。tld.lastbox.x为上一帧所获得运动目标的X坐标,tld.lastbox.y为上一帧所获得运动目标的Y坐标。结果如图:
如图所示A区域为预测运动目标所在区域的,B为检测到运动目标区域。通过卡尔曼滤波获取到A区域后将整个待扫描窗口中与A区域有重叠的窗口进行检测,这样大大减少了待测窗口的数量,提高了运算速度。