import gzip
import os
import click
import paddle.v2 as paddle
from config import TrainerConfig as conf
from network_conf import Model
from reader import DataGenerator
from utils import get_file_list, build_label_dict, load_dict
"""
@click.command('train')
@click.option(
"--train_file_list_path",
type=str,
required=True,
help=("The path of the file which contains "
"path list of train image files."))
@click.option(
"--test_file_list_path",
type=str,
required=True,
help=("The path of the file which contains "
"path list of test image files."))
@click.option(
"--label_dict_path",
type=str,
required=True,
help=("The path of label dictionary. "
"If this parameter is set, but the file does not exist, "
"label dictionay will be built from "
"the training data automatically."))
@click.option(
"--model_save_dir",
type=str,
default="models",
help="The path to save the trained models (default: 'models').")
"""
def train(train_file_list_path, test_file_list_path, label_dict_path,
model_save_dir):
if not os.path.exists(model_save_dir):
os.mkdir(model_save_dir)
train_file_list = get_file_list(train_file_list_path)
test_file_list = get_file_list(test_file_list_path)
if not os.path.exists(label_dict_path):
print(("Label dictionary is not given, the dictionary "
"is automatically built from the training data."))
build_label_dict(train_file_list, label_dict_path)
char_dict = load_dict(label_dict_path)
dict_size = len(char_dict)
data_generator = DataGenerator(
char_dict=char_dict, image_shape=conf.image_shape)
paddle.init(use_gpu=conf.use_gpu, trainer_count=conf.trainer_count)
# Create optimizer.
optimizer = paddle.optimizer.Momentum(momentum=conf.momentum)
# Define network topology.
model = Model(dict_size, conf.image_shape, is_infer=False)
# Create all the trainable parameters.
params = paddle.parameters.create(model.cost)
trainer = paddle.trainer.SGD(cost=model.cost,
parameters=params,
update_equation=optimizer,
extra_layers=model.eval)
# Feeding dictionary.
feeding = {'image': 0, 'label': 1}
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % conf.log_period == 0:
print("Pass %d, batch %d, Samples %d, Cost %f, Eval %s" %
(event.pass_id, event.batch_id, event.batch_id *
conf.batch_size, event.cost, event.metrics))
if isinstance(event, paddle.event.EndPass):
# Here, because training and testing data share a same format,
# we still use the reader.train_reader to read the testing data.
result = trainer.test(
reader=paddle.batch(
data_generator.train_reader(test_file_list),
batch_size=conf.batch_size),
feeding=feeding)
print("Test %d, Cost %f, Eval %s" %
(event.pass_id, result.cost, result.metrics))
with gzip.open(
os.path.join(model_save_dir, "params_pass_%05d.tar.gz" %
event.pass_id), "w") as f:
trainer.save_parameter_to_tar(f)
trainer.train(
reader=paddle.batch(
paddle.reader.shuffle(
data_generator.train_reader(train_file_list),
buf_size=conf.buf_size),
batch_size=conf.batch_size),
feeding=feeding,
event_handler=event_handler,
num_passes=conf.num_passes)
if __name__ == "__main__":
# train("Training_GT/gt.txt","Challenge2_Test_Task3_GT.txt","label_dict.txt","model")
train("Train_GT/Challenge2_Test_Task3_GT.txt","Challenge2_Test_Task3_GT.txt","label_dict.txt","model")源码来自:http://www.paddlepaddle.org/docs/develop/models/scene_text_recognition/README.html
运行结果是:
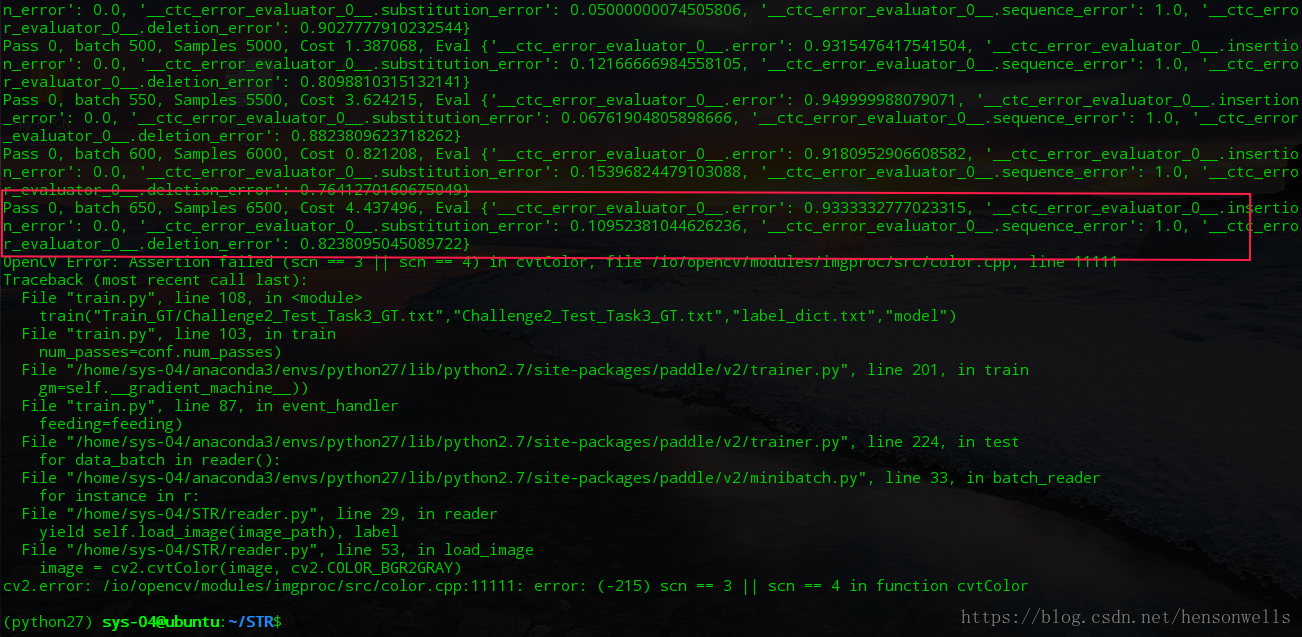
经过分析得知,里面定义的reader通过文本路径用来读取数据集直接喂给trainer,训练时候没有设置offset,数据集只能喂一遍过,所以遍历一遍数据集后往后获取的数据集为空引起的错误,这……难道不是一个bug?难道数据集不需要多次遍历训练???