代码非常简单,有咱们前面的教程做铺垫,很少的代码就可以实现完整的功能了,最后把采集到的内容写到 csv 文件里面,( csv 是啥,你百度一下就知道了) 这段代码是 IO密集操作 我们采用 aiohttp 模块编写。
Python学习资料或者需要代码、视频加Python学习群:960410445
第1步
拼接URL,开启线程。

上面的代码可以同步开启N多个线程,但是这样子很容易造成别人的服务器瘫痪,所以,我们必须要限制一下并发次数,下面的代码,你自己尝试放到指定的位置吧。

第2步
处理抓取到的网页源码,提取我们想要的元素,我新增了一个方法,采用 lxml 进行数据提取。
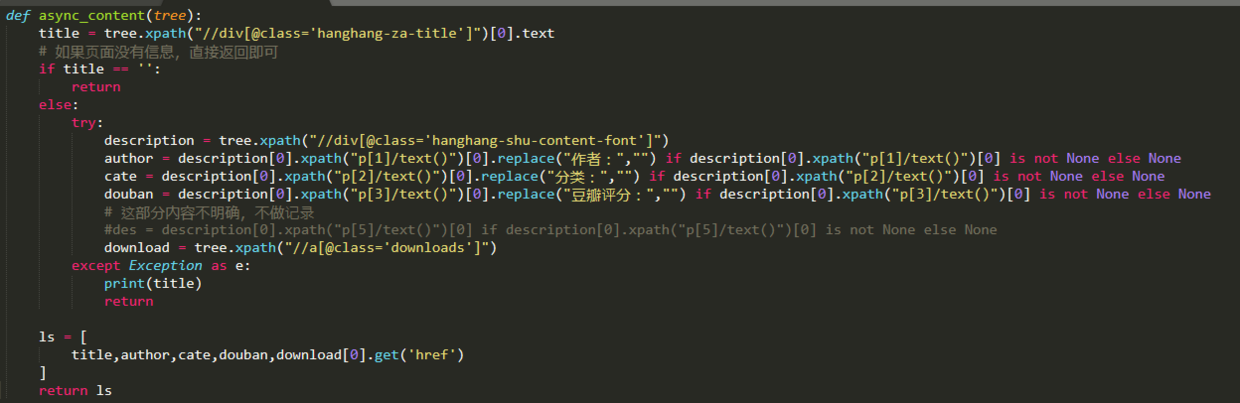
第3步
数据格式化之后,保存到 csv 文件,收工!

运行代码,查看结果
