我们这次也玩点以前没写过的,使用python中的queue,也就是队列
下面是我从别人那顺来的一些解释,基本爬虫初期也就用到这么多
Python学习资料或者需要代码、视频加Python学习群:960410445
1. 初始化: classQueue.Queue(maxsize)FIFO先进先出2. 包中的常用方法: - queue.qsize() 返回队列的大小
- queue.empty() 如果队列为空,返回True,反之False
- queue.full() 如果队列满了,返回True,反之False
- queue.full 与 maxsize 大小对应
- queue.get([block[, timeout]])获取队列,timeout等待时间3. 创建一个“队列”对象
import queue myqueue = queue.Queue(maxsize = 10)4. 将一个值放入队列中
myqueue.put(10)5. 将一个值从队列中取出
myqueue.get()
开始编码
首先我们先实现主要方法的框架,我依旧是把一些核心的点,都写在注释上面
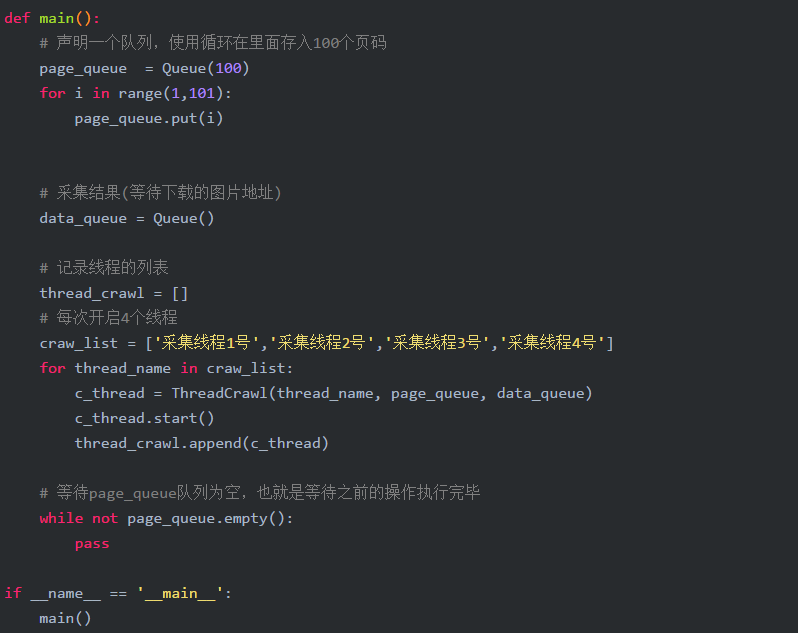
代码运行之后,成功启动了4个线程,然后等待线程结束,这个地方注意,你需要把 ThreadCrawl 类补充完整

运行结果

线程已经开启,在run方法中,补充爬取数据的代码就好了,这个地方引入一个全局变量,用来标识爬取状态
CRAWL_EXIT = False
先在main方法中加入如下代码

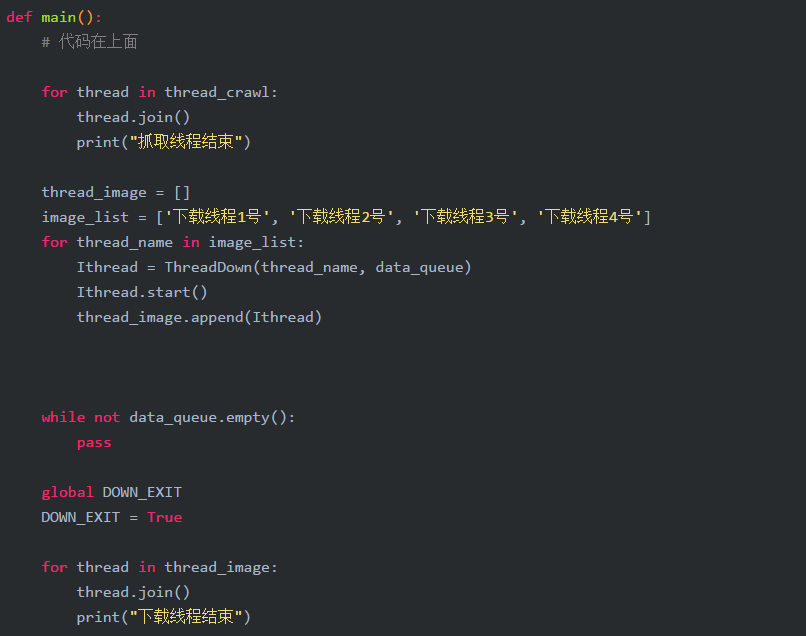
经过测试,data_queue 里面有数据啦!!,哈哈,下面在使用相同的操作,去下载图片就好喽

完善main方法
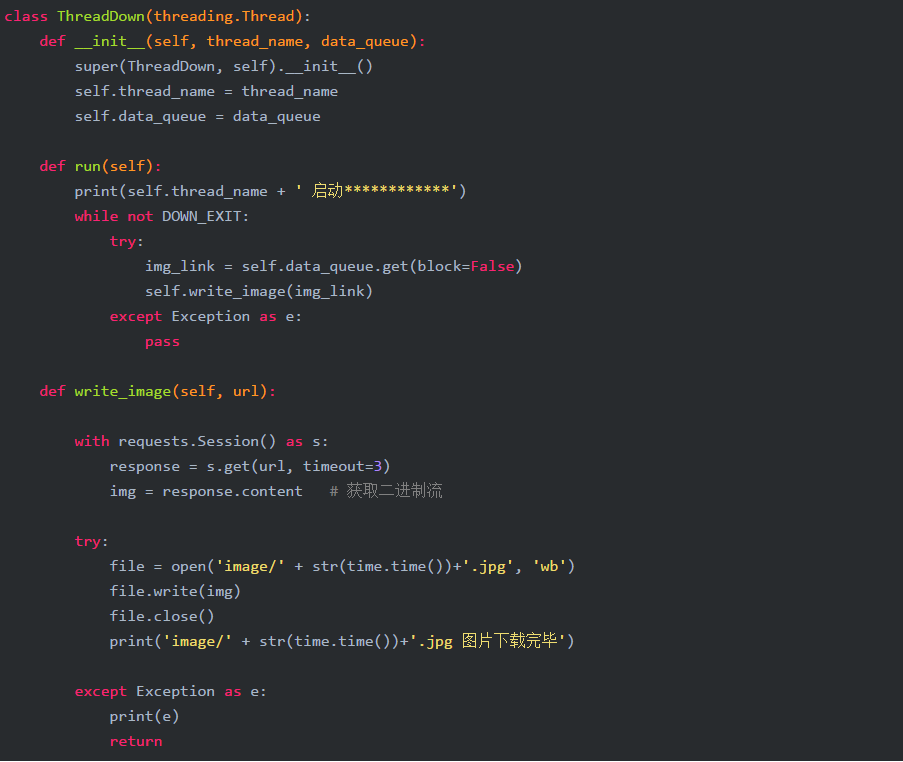
还是补充一个 ThreadDown 类,这个类就是用来下载图片的。
运行之后,等待图片下载就可以啦~~

关键注释已经添加到代码里面了,收图吧 (◕ᴗ◕✿),这次代码回头在上传到github上 因为比较简单