引言:今天周末,想找本电子书看看。发现了一个很好的电子书下载网站。为了以后找书方便,顺便练习一下python3写爬虫,于是就有了今天的小成果,python3爬取电子书网站所有链接。
第一步:网站分析
首先,这是网站的首页:http://www.ireadweek.com/index.php/index/1.html。
点击网站的尾页,看看总共有多少网页。如下图:

点击之后,发现网址变为:http://www.ireadweek.com/index.php/index/218.html。 这说明总共有218个父页面。每个主页面是如下图这样的列表:

点击链接,进入任意子页面,要爬取下面的5个框框。

2.开始写代码
先获取每个父页面所有书名链接。

取得页面结构。

根据以上分析,先写代码,拼接出所有的父页面。
if __name__ == "__main__":
try:
pool = multiprocessing.Pool(processes=8)
for i in range(1, 219):
url = "http://www.ireadweek.com/index.php/index/" + str(i)+".html"#这里就是所有父页面
pool.apply_async(get_index_url, args=(url,)) # 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool.close()
pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
except:
print('abort')
然后,获取某一父页面中所有书名链接:
wbdata = requests.get(url, headers=header).content
soup = BeautifulSoup(wbdata, 'html.parser')
links = soup.select('html > body > div > div > ul > a') #这个是由上面copy selector得到的
然后,拼接子页面来获取子页面的网页内容:
book_page_url = "http://www.ireadweek.com"+page_url
wbdata2 = requests.get(book_page_url, headers=header).content.decode('utf-8')
soup2 = BeautifulSoup(wbdata2, 'html.parser')
再,在子页面中获取上面的5个框框里面的信息,方法也是如上,书名上鼠标右键->审查元素,得到下图:

于是,得到这样的结构分支:
body > div > div > div.hanghang - za > div: nth - child(1)
#用beautifulsoup的select来获取。注意这里要在前面加上html。获取情况需要加print打印来调试
book_name = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-za-title')[0].text
print(book_name)
通过同样的方式,将其他信息获取。
dowrload_url = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-box > div.hanghang-shu-content-btn > a')[0].get('href')
print(dowrload_url)
# body > div > div > div.hanghang - za > div.hanghang - shu - content > div.hanghang - shu - content - font > p: nth - child(1)
author = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[0].text
print(author)
category = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[1].text
print(category)
book_info = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[4].text
print(book_info)
# body > div > div > div.hanghang - za > div: nth - child(1)
book_name = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-za-title')[0].text
print(book_name)
终端打印如下:

3.遇到的问题:
1)如何提取类似下面这样内容里面的网址链接?
<a class="name" href="http://www.imooc.com/profile.do?id=222222222" target="_blank" title="ZZZ">ZZZ</a>
解决:如下,
book_name = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-box > div.hanghang-shu-content-btn > a')[0].get('href')
2)如下写法会报错。
soup= BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
报错:UserWarning: Youprovided Unicode markup but also provided a value for from_encoding. Yourfrom_encoding will be ignored.
解决方法: 删除【from_encoding="utf-8"】
原因:python3 缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉,去掉【from_encoding="utf-8"】这一个好了 。
3)写入csv文件后,用notepad打开正常显示,用Excel打开是乱码。如下
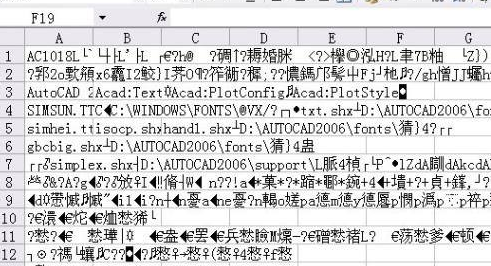
解决:代码中打开方式这样写:
with open("C:/BookDownload.csv",'a',encoding='utf-8',newline='') as f:#这句会乱码
with open("C:/BookDownload.csv",'a',encoding='gb18030',newline='') as f: #这句解决对策
好啦,解决了以上问题,终于可以爬取了。如果觉得有帮助的话,请支持一下。
下面上完整代码:
#!/usr/bin/env python3
# -*- coding: utf-8
#author:wangqiyang
import re
import pymysql
import csv
import time
import requests
import multiprocessing
import random
import codecs
from bs4 import BeautifulSoup
#假装不同的浏览器,这次暂时没有用上。
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; WOW64; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; InfoPath.2; .NET CLR 3.5.30729; .NET CLR 3.0.30618; .NET CLR 1.1.4322)',
]
#这个实际不用写这么多,为了防止被封,就多写点吧
header = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",#user_agent_list[random.randint(0, 5)],
'Connection': 'keep-alive',
'Cookie': '这里粘贴自己cookie',
'Host': 'www.ireadweek.com',
'Referer': 'http://www.ireadweek.com/index.php/Index/index.html',
'Upgrade-Insecure-Requests': '1'
}
def get_index_url(url):
wbdata = requests.get(url, headers=header).content
soup = BeautifulSoup(wbdata, 'html.parser')
links = soup.select('html > body > div > div > ul > a')
for link in links:
try:
time.sleep(random.randint(1,3))
page_url = link.get('href')
print("page_url:"+"http://www.ireadweek.com"+page_url)
book_page_url = "http://www.ireadweek.com"+page_url
wbdata2 = requests.get(book_page_url, headers=header).content.decode('utf-8')
# print(wbdata2)
soup2 = BeautifulSoup(wbdata2, 'html.parser')
dowrload_url = "NONE"
dowrload_url = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-box > div.hanghang-shu-content-btn > a')[0].get('href')
print(dowrload_url)
# body > div > div > div.hanghang - za > div.hanghang - shu - content > div.hanghang - shu - content - font > p: nth - child(1)
author = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[0].text
print(author)
category = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[1].text
print(category)
book_info = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-shu-content > div.hanghang-shu-content-font > p')[4].text
print(book_info)
# body > div > div > div.hanghang - za > div: nth - child(1)
book_name = soup2.select('html > body > div > div > div.hanghang-za > div.hanghang-za-title')[0].text
print(book_name)
with open("C:/BookDownload.csv",'a',encoding='gb18030',newline='') as f:
try:
# f.write(codecs.BOM_UTF8)
f.write(book_name)
f.write(',')
f.write(author)
f.write(',')
f.write(category)
f.write(',')
f.write(dowrload_url)
f.write(',')
f.write("\n")
except:
pass
except:
print("link not found!!!"+link)
pass
if __name__ == "__main__":
try:
pool = multiprocessing.Pool(processes=8)
print("---------------------1---------------")
for i in range(1, 219):
url = "http://www.ireadweek.com/index.php/index/" + str(i)+".html"
print("---------------------2---------------"+url)
pool.apply_async(get_index_url, args=(url,)) # 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool.close()
pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
except:
print('abort')