Github传送门:https://github.com/JosephPai/PythonCrawler-Html2Pdf
欢迎点赞~
环境
python3.6
准备工具
爬虫依旧采用requests+BeautifulSoup组合,reuqests 用于网络请求,beautifusoup 用于操作 html 数据。
此外,涉及到把 html 文件转为 pdf,我们采用 wkhtmltopdf ,它可以用适用于多平台的 html 到 pdf 的转换,
pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包
pip install requests
pip install beautifulsoup4
pip install pdfkitpdfkit使用参考:pdfkit文档
安装 wkhtmltopdf
Windows平台直接在 http://wkhtmltopdf.org/downloads.html 下载稳定版的 wkhtmltopdf 进行安装,
安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,
否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”。
在运行程序过程中可能会出现no such file or directory:b”
这种错误在python中出现时,意味着有.exe文件需要被调用,而该.exe文件没有被安装或者在控制面板的环境变量中没有添加该.exe的路径。
请再三确认是否已经将wkhtmltopdf安装的bin文件夹路径添加到path中
如果仍旧无法解决问题,程序中需添加代码
config=pdfkit.configuration(wkhtmltopdf=r"D:\software\wkhtmltopdf\bin\wkhtmltopdf.exe")
pdfkit.from_file(htmls, self.name + ".pdf", options=options,configuration=config)即手动导入.exe文件路径
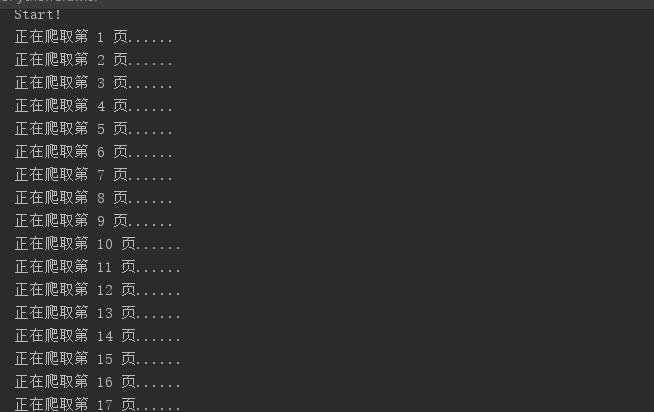
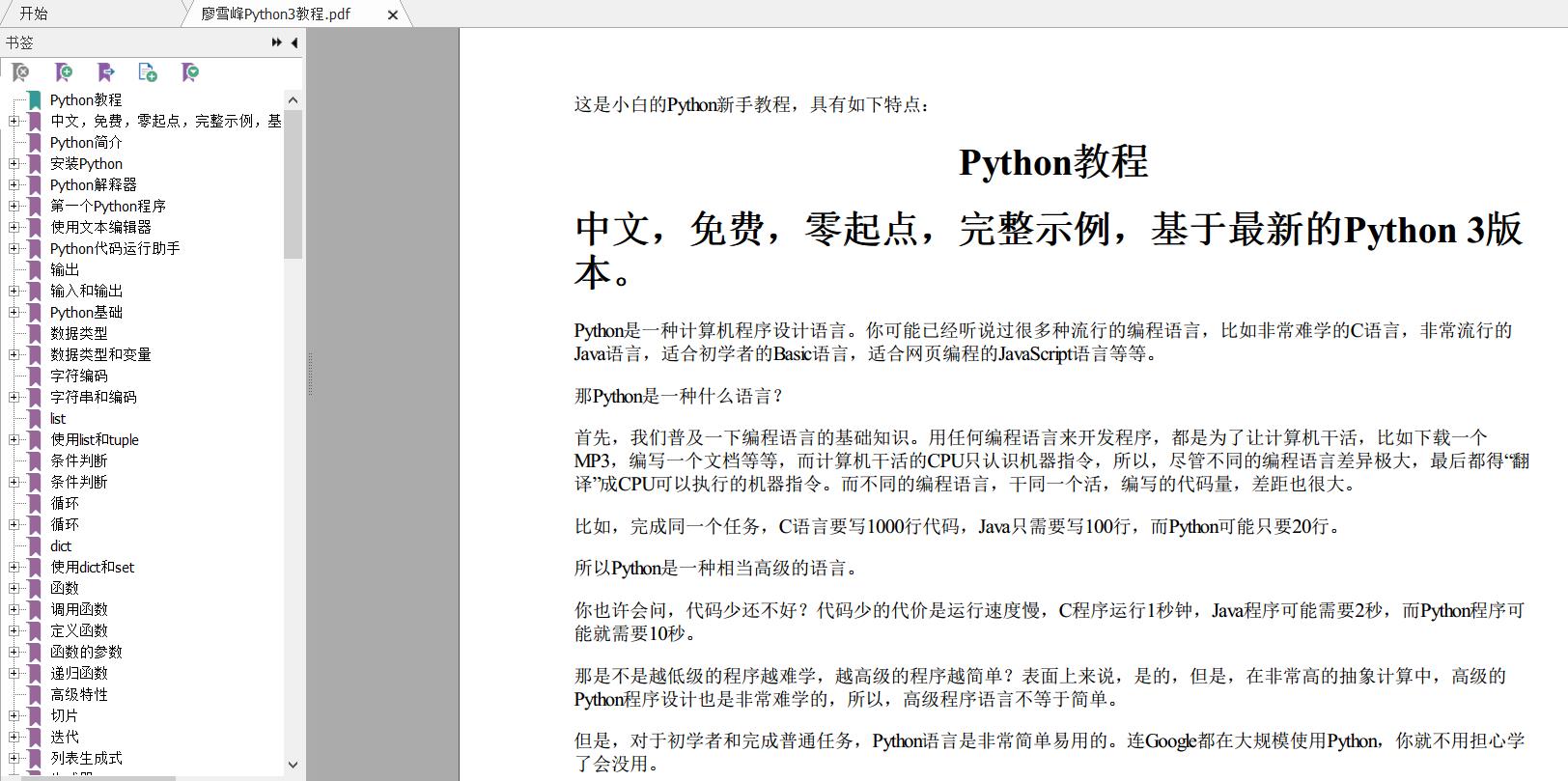
运行
python LiaoPythonCrawler.py效果图
class Crawler(object):
"""
爬虫基类,所有爬虫都应该继承此类
"""
name = None
def __init__(self, name, start_url):
"""
初始化
:param name: 将要被保存为PDF的文件名称
:param start_url: 爬虫入口URL
"""
self.name = name
self.start_url = start_url
self.domain = '{uri.scheme}://{uri.netloc}'.format(uri=urlparse(self.start_url))
@staticmethod
def request(url, **kwargs):
"""
网络请求,返回response对象
:return:
"""
response = requests.get(url, **kwargs)
return response
def parse_menu(self, response):
"""
从response中解析出所有目录的URL链接
"""
raise NotImplementedError
def parse_body(self, response):
"""
解析正文,由子类实现
:param response: 爬虫返回的response对象
:return: 返回经过处理的html正文文本
"""
raise NotImplementedError
def run(self):
start = time.time()
print("Start!")
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'outline-depth': 10,
}
htmls = []
count=1
for index, url in enumerate(self.parse_menu(self.request(self.start_url))):
html = self.parse_body(self.request(url))
f_name = ".".join([str(index), "html"])
with open(f_name, 'wb') as f:
print("正在爬取第 %d 页......" % count)
f.write(html)
count += 1
htmls.append(f_name)
print("HTML文件下载完成,开始转换PDF")
pdfkit.from_file(htmls, self.name + ".pdf", options=options)
print("PDF转换完成,开始清除无用HTML文件")
for html in htmls:
os.remove(html)
total_time = time.time() - start
print(u"完成!总共耗时:%f 秒" % total_time)
class LiaoxuefengPythonCrawler(Crawler):
"""
廖雪峰Python3教程
"""
def parse_menu(self, response):
bsObj = BeautifulSoup(response.content, "html.parser")
menu_tag = bsObj.find_all(class_="uk-nav uk-nav-side")[1]
for li in menu_tag.find_all("li"):
url = li.a.get("href")
if not url.startswith("http"):
url = "".join([self.domain, url]) # 补全为全路径
yield url
def parse_body(self, response):
try:
bsObj = BeautifulSoup(response.content, 'html.parser')
body = bsObj.find_all(class_="x-wiki-content")[0]
# 加入标题, 居中显示
title = bsObj.find('h4').get_text()
center_tag = bsObj.new_tag("center")
title_tag = bsObj.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "(<img .*?src=\")(.*?)(\")"
def func(m):
if not m.group(2).startswith("http"):
rtn = "".join([m.group(1), self.domain, m.group(2), m.group(3)])
return rtn
else:
return "".join([m.group(1), m.group(2), m.group(3)])
html = re.compile(pattern).sub(func, html)
html = html_template.format(content=html)
html = html.encode("utf-8")
return html
except Exception as e:
logging.error("解析错误", exc_info=True)完整代码:https://github.com/JosephPai/PythonCrawler-Html2Pdf/blob/master/LiaoPythonCrawler.py