1、以前学习分类算法时候,一直用分类准确度进行算法的好坏,准确度一定准确吗?
对于极度偏斜(Skewed data)的数据,只使用分类准确度是不够的。比如一种癌症的发病率是0.01%,那么我们系统即使在不分类的情况下,预测健康的情况准确率就可以达到99.99%。这个明显是不符合实际情况的。
因此我们引入一种新的评价指标。首先我们熟悉一个概念:混淆矩阵(Confusion Matrix)

2、 什么是精准率和召回率?
准确率表示预测我们关注事件的准确率

召回率表示 我们算法在已经发生的事件中正确预测个数的比率。
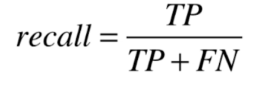
比如下面是我们算法预测10000个人中有癌症的情况:
TN表示9978个人是健康的,并且我们预测正确,为健康人
FP表示12个人是健康的,但是我们预测为有癌症的,预测错误
FN表示1个人是有癌症的,但是我们预测为健康的,预测错误
FP表示8个人是有癌症的,并且我们预测正确,为有癌症人

准确率precision = TP / (FP + TP) = 8 / 20 = 0.4
召回率 recall = TP / (FN + TP) = 8 / 10 = 0.8
3、那如果模型预测结果中,准确率和召回率一个高一个低,如何评价模型的好坏呢?
这要根据具体场景来看。不同场景对精准率和召回率的要求不一样。
比如: 在股票预测中,精准率要比召回率更重要
在癌症诊断中,病人的召回率要比准确率更重要
如果某些场景对这两个指标的重视程度一样的话,就用一个新指标: F1 Score
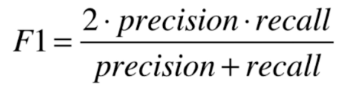
F1 Score 是precision和recall的调和平均值
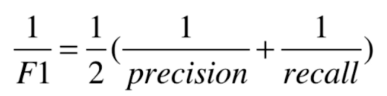
为什么使用调和平均值,而不是算术平均值。因为两个数据不平衡会求出来F1也会很低。只有两个数据都高的时候 F1也会高。而算术平均值无法表现两个极端数据。
4、 如何做到精准率和召回率的平衡?
这个指标之间有内在的联系,并且相互冲突。

在sklearn中有一个方法叫:decision_function,通过这个方法可以调整精准率和召回率
decision_scores = log_reg.decision_function(X_test)
y_predict_2 = np.array(decision_scores >= 5, dtype='int')我们可以通过绘制曲线,进行可视化,这个坐标横轴是threshold的。可以看出precision随着threshold的增加而降低,recall随着threshold的增大而减小。如果某些场景需要precision,recall都保持在80%,可以通过这种方式求出threshold.

同时还有另一种曲线,叫Precision-Recall曲线,简称PR曲线。这个曲线与上面相比,X轴是Recall, Y轴是P热词送。

从上图在0.9左右的时候,曲线突然下降。一般来说这个下降点就是最好的点。
最后附代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
X, target = load_digits(return_X_y=True)
y = target.copy()
y[target == 9] = 1
y[target != 9] = 0
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
y_predict = log_reg.predict(X_test)
confusion = confusion_matrix(y_test, y_predict)
score = log_reg.score(X_test, y_test)
precision = precision_score(y_test, y_predict)
recall = recall_score(y_test, y_predict)
f1_scores = f1_score(y_test, y_predict)
print 'confusion matrix:\n', confusion
print 'accuracy score:', score
print 'precision:', precision
print 'recall:', recall
print 'f1_scores:', f1_scores
decision_scores = log_reg.decision_function(X_test)
#print 'decision_scores:', decision_scores
y_predict_2 = np.array(decision_scores >= 5, dtype='int')
confusion = confusion_matrix(y_test, y_predict_2)
print 'confusion matrix (decision_scores >= 5):\n', confusion
precisions = []
recalls = []
thresholds = np.linspace(min(decision_scores), max(decision_scores), 100)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold, dtype='int')
precisions.append(precision_score(y_test, y_predict))
recalls.append(recall_score(y_test, y_predict))
#PR-Threshold
# plt.plot(thresholds, precisions, label='Precision')
# plt.plot(thresholds, recalls, label='Recall')
# plt.legend()
# plt.show()
# PR
# plt.plot(precisions, recalls)
# plt.show()运行结果:
confusion matrix:
[[403 2]
[ 9 36]]
accuracy score: 0.9755555555555555
precision: 0.9473684210526315
recall: 0.8
f1_scores: 0.8674698795180723
confusion matrix (decision_scores >= 5):
[[404 1]
[ 21 24]]
可以看到,随着decision_scores的变化,混淆矩阵也发生了变化。