在上面博客中我们主要使用逻辑回归进行线性数据的分类,那么逻辑如何处理非线性数据分类呢?比如下面的数据:

1、利用逻辑回归如何处理非线性数据回归?
针对上面的数据,我们首先尝试回归一下,看看获取的结果是: 0.605, 这个评分不是很高,让后我们绘制一下决策边界:

很明显决策边界误差很大。
那么接下来我们加入多项式看看
def PolynomialFeaturesLogsticRegression(degree):
return Pipeline(
[("poly", PolynomialFeatures(degree)),
("std_scaler", StandardScaler()),
("log_reg", LogisticRegression())]
)
让degree=2,测试结果:
评分:0.96

绘制的决策边界图,比较符合情况。
当degree = 20时候,看到绘制的决策边界如何,这个说明是过拟合呢
扫描二维码关注公众号,回复:
4681962 查看本文章


3、如何处理逻辑回归中的过拟合?
对于过拟合,我们有两种处理办法.
1、进行网格搜索找到最佳的degree
2、使用模型的正则化
在sklearn中的逻辑回归中,默认是支持正则化的。但这与我们以前讲的稍微有一点区别:
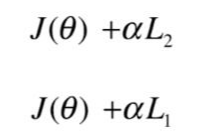 在 sklearn中是:
在 sklearn中是: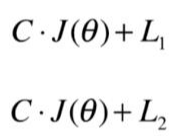
可以看到以前我们把超参数加载 L1和L2范数前面, 但是在Sklearn中把该参数加在损失函数前面。
有两个参数要注意:penalty : str, ‘l1’ or ‘l2’, default: ‘l2’ 表示惩罚函数是L1还是L2
C : float, default: 1.0, 表示正则惩罚的强度,必须是一个正的浮点数。
我们把这两个参数加上,尝试一下:
def PolynomialLogisticRegression(degree, C, penalty='l2'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
])poly_log_reg3 = PolynomialLogisticRegression(degree=20, C=0.1) 默认是L2

poly_log_reg4 = PolynomialLogisticRegression(degree=20, C=0.1, penalty='l1')

通过绘图可以看出,degree实际是2,让我们输入20时候,明显过拟合。 我们使用正则化时候对模型做了调整,可以看出快接近我们的原来数据形状了。
最后分享一下绘图的代码:
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)