神经网络直接决定类与类之间的separating hyperplanes(分离超平面),而超平层分隔开两个类的特征向量,落在在层的一边的特征向量属于class 1,落在另一边则属于class 2。基于单层神经网络的分类器需要 linearly separable classes(线性可分的类),在许多应用中不够高效。基于多层神经网络的分类器则无此限制,只要隐藏层包含足够多的处理单元即可。

神经网络
神经网络每一层的处理单元计算特征向量的线性组合或者来自前一层的结果。


参数说明:

计算结果通过非线性函数( nonlinear activation function)传递:
![]()
在halcon中该函数为双曲线正切函数( hyperbolic tangent function):

当使用MLP分类时,halcon使用函数将输出结果转换到(0~1)的值域,结果的和为1。函数被称为 softmax activation function:

要使用MLP去分类,必须调整网络权重(network weights),通过使用使用已知类别的图像去训练MLP网络形成处理单元 (hidden units),数据插入输入层经过hidden units处理,输出与期望的结果比对,不匹配则调整网络权重。halcon的网络权重计算结果比由经典反向传播算法得到的结果好.
MLP在Halcon的用途:classification of general features,特征分类image segmentation, 图像分割and OCR字符识别 least squares fitting (regression)最小二乘法拟合 classification problems with multiple independent logical attributes在Halcon中MLP只有一个 hidden layer隐藏层,有多个隐藏层的MLP被归为deep learning。
MLP分类的参数调整。 我们建议首先调整参数,使分类结果令人满意。 最重要的参数必须进行调整才能使MLP分类器最佳地工作。
如果分类通常有效,您可以开始调整速度。 提高速度的最重要的参数是Preprocessing / NumComponents (create_class_mlp)和MaxIterations(train_class_mlp)。
参数对于这些设置,不是立即显而易见的,或者对于它们来说并不是很明显影响分类。 这些主要是创建和培训所需的参数分类。
create_class_mlp
用create_class_mlp创建MLP分类器。对于分类器定义分类器的属性是重要的。返回句柄修改如下面几个步骤。下面参数调整如下:
输入参数NumInput:
输入参数NumInput指定特征向量的维度,500个特征依然都可以。
输入参数NumHidden:
输入参数NumHidden定义多层神经元的隐藏层的单元数,隐藏层影响分类的结果,因此应该要非常仔细地调整。导致NumInput和NumOutput变动很小的范围。较小的值导致不太复杂的分离超平面,但在许多情况下可能导致效果很好。如果NumHidden具有非常大的值,则存在过度拟合的风险(参见下图)。分类器使用噪声这样的不重要的细节来构建类边界,训练数据非常有效,但对于未知特征向量测试失败。换句话说,过度拟合意味着分类器失去其泛化能力。要调整NumHidden,建议使用独立测试数据进行测试,例如使用验证在第115页的8.1节中介绍。请注意示例hdevelop \ Classification \Neural-Nets \ class_overlap.hdev提供了有关不同值的影响的进一步提示NumHidden。

NumHidden取值曲线图
参数NumOutput:
输入参数NumOutput指定分类的数量。
参数OutputFunction:
输入参数OutputFunction描述了神经网络输出单元使用的函数。可选择“softmax”,“logistic”和“linear”。 在几乎所有分类应用中,OutputFunction应设置为'softmax'。 值'logistic'可用于分类多个独立逻辑属性作为输出的问题,但这种分类问题在实践中是非常罕见的。 值'linear'用于最小二乘拟合(回归)而不是非线性分类。 因此,你可以在这里忽略它。
参数预处理/ NumComponents
输入参数Preprocessing定义应用于特征向量的预处理类型训练以及以后的分类或评估。预处理特征向量可以
用于加速训练和分类。有时,甚至识别率都可以提高。
可选择“none”,“normalization”,“principal_components”和“canonical_variates”。在大多数情况下,预处理应设置为“标准化”与不使用预处理相比,它可以提高速度而不会丢失相关信息('没有')。通过减去训练向量的平均值来对特征向量进行归一化将结果除以训练向量的各个分量的标准偏差。因此,变换后的特征向量的均值为0,标准差为1.归一化不改变特征向量的长度。如果速度很重要且预计数据高度相关,则可以减小尺寸使用主成分分析('principal_components')的特征向量。那里,对特征向量进行归一化并另外进行变换,使得协方差矩阵变为a对角矩阵。因此,可以减少数据量而不会丢失大量信息。
如果您知道类可以线性分离,那么您也可以使用规范变量(” canonical_variates’)。这种方法也称为线性判别分析。那里,归一化特征向量的变换使训练向量平均地解除所有类。同时,转换最大限度地分离了个体的平均值
类。该方法结合了主成分分析和优化的优点数据减少后类的可分离性。但请注意参数'canonical_variates'
建议仅用于线性可分类。对于MLP,'canonical_variates'只能是如果OutputFunction设置为'softmax',则使用此选项。

通过主成分分析转换特征空间后,使用一个特征线性可分
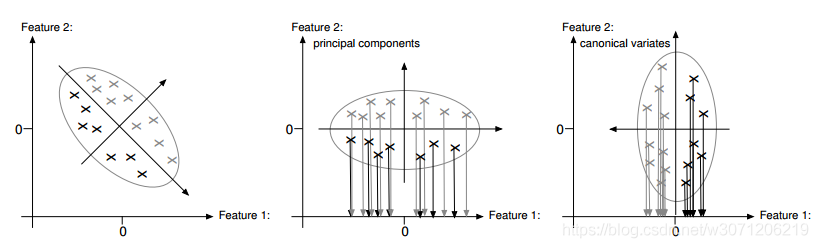
通过主成分分析变换特征空间之后,分离两个特征。 改造之后使用规范变量的特征空间可以通过单个特征分隔
输入参数NumComponents:
输入参数NumComponents定义特征向量所在的组件数如果选择预处理以减小特征向量的维数,则减少。 特别是,仅当预处理设置为'principal_components'或时,才需要调整NumComponents“canonical_variates”。
如果预处理设置为'principal_components'或'canonical_variates',则可以使用运算符get_prep_info_class_mlp检查转换后的特征向量的内容是否仍然存在重要数据。确定最佳数量组件。然后,首先创建一个测试分类器,例如,将NumComponents设置为NumInput,生成训练样本并将其添加到分类器,然后应用get_prep_info_class_mlp。该输出参数CumInformationCont是一个包含0到1之间数字的元组。这些数字
描述转换数据所涵盖的原始数据量。也就是说,如果你愿意的话如果转换后的数据至少包含90%的原始数据,则搜索第一个值大于0.9并使用元组CumInformationCont的相应索引号作为值对于新的NumComponents。然后,您销毁测试分类器并为final创建新的分类器训练(这次NumComponents设置为新值)。
请注意,在测试训练期间(write_samples_class_mlp)将样本存储到文件中是合适的,这样您就不必连续
再次添加训练样本,但只需使用read_samples_class_mlp读入示例文件。
参数RandSeed:
MLP的权重由随机数初始化。 该随机数的种子值存储在输入参数RandSeed中。
参数MLPHandle:
create_class_mlp的输出参数是MLPHandle,它是所有以下特定于分类的运算符所必需的。
add_sample_class_mlp
使用add_sample_class_mlp将单个样本添加到MLP分类器。对于训练,必须通过连续调用带有不同样本的add_sample_class_mlp来添加样本。
参数MLPHandle:
输入和输出参数MLPHandle是使用创建的分类器的句柄create_class_mlp,随后使用add_sample_class_mlp将样本添加到其中。在为所有可用样本应用add_sample_class_mlp之后,将为实际准备句柄训练分类器。
输入参数Features:
添加到分类器的样本的特征向量,使用add_sample_class_mlp。此特征向量是值的元组。每个值描述一个特定的数字功能。请注意,特征向量必须由实数组成。如果你有整数,你必须把它们变成实数。否则,将引发错误消息。
输入参数Targe:
输入参数Target描述目标向量,即,您将相应的类ID分配给特征向量。如果OutputFunction设置为'softmax',则目标向量是一个仅包含一个元素的元组值为1,多个元素值为0.向量的大小对应于数字在create_class_mlp中由NumOutput指定的可用类。元素的索引值1定义特征向量特征所属的类。或者,一个整数包含类号(从0开始)可以指定。对于设置为'logistic'的OutputFunction,目标向量由0或1的值组成图1示出了存在相应的特征。如果OutputFunction设置为'linear',则目标向量可以包含任意实数。就这样参数值用于最小二乘拟合(回归)而不用于分类,不对其进行解释
train_class_mlp
使用train_class_mlp应用MLP分类器的训练。 训练MLP意味着确定MLP权重的最佳值。 为此,足够多的
训练样本的数量是必要的。 通过复杂的非线性优化来执行训练最小化MLP输出,add_sample_class_mlp定义目标向量。 可以调整以下参数:
参数MLPHandle
输入和输出参数MLPHandle是使用create_class_mlp创建的分类器的句柄,并且通过add_sample_class_mlp添加它们来存储样本或通过read_samples_class_mlp读取它们。 使用train_class_mlp,句柄准备用于未知数据的实际分类。
参数Parameters MaxIterations / WeightTolerance / ErrorTolerance
输入参数MaxIterations,WeightTolerance和ErrorTolerance控制非线性优化算法。 MaxIterations指定优化算法的迭代次数。如果重量变化小于WeightTolerance,则终止优化。错误的变化小于ErrorTolerance,在任何情况下,优化都在之后终止。最多MaxIterations迭代,对于后者,大多数情况下100到200之间的值就足够了
案例。默认值为200.通过减小此值,可以提高训练速度。在多数情况下,对于参数WeightTolerance和ErrorTolerance不必更改默认值。
Error
输出参数Error以训练时的最佳权重返回MLP的错误样本。
ErrorLog
输出参数ErrorLog将错误值作为迭代次数的函数返回。这个函数可用于决定是否使用相同的训练样本进行第二次训练但是具有不同RandSeed,如果函数运行到局部最小值就是这种情况。
evaluate_class_mlp
运算符evaluate_class_mlp可用于评估特征向量属于每个类的概率。如果只有两个类,不需要评估属于哪个的概
,因为返回特征向量的最终分类概率。可以调整以下参数:
参数MLPHandle
输入参数MLPHandle是先前使用操作符train_class_mlp训练的分类器的句柄。
参数Features
输入参数Features包含要评估的特征向量。 特征向量必须包含与add_sample_class_mlp用于训练样本的特征向量相同的特征
参数结果Result
输出参数Result返回评估结果。 取决于使用create_class_mlp设置的OutputFunction。 如果设置'softmax',应该是大多数分类应用程序的情况,返回的元组包每个特征向量值括概率值。 如果设置为'logistic',则返回元组的元素,表示各个独立属性的存在。
classify_class_mlp
classify_class_mlp根据类边界对特征向量进行分类。只有在create_class_mlp里OutputFunction设置为'softmax'时才能调用它。
参数MLPHandle
输入参数MLPHandle描述了使用create_class_mlp创建的句柄,
使用add_sample_class_mlp添加样本,并使用train_class_mlp训练。
Features
输入参数Features包含要分类的对象的特征向量。该特征向量必须包含与用于训练样本的特征向量相同的特征
在add_sample_class_mlp中。
参数Num
输入参数Num指定要搜索的最佳类的数量。通常,Num已设定如果只搜索具有最佳概率的类,则为1;如果第二个最佳类也是,则为2兴趣,例如,因为类重叠。
参数类
输出参数Class返回使用训练的MLP对特征向量进行分类的结果分类器,即包含Num元素的元组。也就是说,如果将Num设置为1,则返回单个值对应于概率最高的类。如果Num设置为2,则第一个元素包含该类具有最高概率,第二个元素包含第二个最佳类。
参数置信度
输出参数Confidence输出分类的置信度。请注意比较对于GMM分类返回的概率,这里返回的值可以受到影响异常值,这是由计算MLP的特定方式引起的。例如,信心可能对于远离特定类的其他训练样本的特征向量,要高
显着位于分离超曲面的同一侧。另一方面,信心可以对于特定类别但接近的训练样本集群内的对象的低值分离超曲面作为两个类重叠在该群的这一部分(见图5.6)。

对于异常值,针对MLP分类计算的置信度可能是意外的。 那是,远离其类中心的特征向量可以高置信度分类,或者靠近类中心但在两个之间的重叠区域内的特征向量课程可以低信心分类。
clear_class_mlp
参数MLPHandle
要销毁分类器,运算符clear_class_mlp仅应用于输入参数MLPHandle。

read_image (Image, 'plastic_mesh/plastic_mesh_01')
get_image_size (Image, Width, Height)
get_system ('example_dir', HalconExamples)
gen_rectangle1 (Rectangle, 10, 10, Height / 2 - 11, Width / 2 - 11)

* 创建多层感知器,5维特征向量维度,6层神经元的隐藏层,输出2类,softmax分类器(多项式分布),预处理设置为'principal_components',使用主成分分析,特征向量所在的组件数3,随机数初始化种子是42
create_class_mlp (5, 6, 2, 'softmax', 'principal_components', 3, 42, MLPHandle)
* The training is based on five images that contain no errors.
*生成空区域
gen_empty_region (EmptyRegion)
*把矩形区域放入空区域中
concat_obj (Rectangle, EmptyRegion, ObjectsConcat)
*抽取5张图片的特征
for J := 1 to 5 by 1
read_image (Image, 'plastic_mesh/plastic_mesh_' + J$'02')
* The images are zoomed down because the resolution of the mesh is very
* high. This saves a large amount of processing time.
*缩小图片,减少运行时间
zoom_image_factor (Image, ImageZoomed, 0.5, 0.5, 'constant')

dev_display (ImageZoomed)
disp_message (WindowHandle, 'Adding training samples...', 'window', 10, 10, 'black', 'true')
* Generate the texture image.
*抽取纹理特征,见网格缺陷检测(GMM)博客
gen_texture_image (ImageZoomed, ImageTexture)

* Add the samples to the classifier.
*把特征和空区域添加到训练句柄中
add_samples_image_class_mlp (ImageTexture, ObjectsConcat, MLPHandle)
endfor
******************************************************************************************************************************
set_rejection_params_class_mlp设置拒绝参数。
'rejection_class_index':默认设置最后一个类为拒绝类。如果应该使用另一个类,则必须将GenParamName设置为'rejection_class_index'并将GenParamValue设置为类索引。
'sampling_strategy':GenParamName设置为'sampling_strategy',GenParamValue设置为'hyperbox_around_all_classes','hyperbox_around_each_class'或'hyperbox_ring_around_each_class'。
'hyperbox_around_all_classes'采用到目前为止提供的所有训练样本的边界框。
'hyperbox_around_each_class'类似'hyperbox_around_all_classes',唯一的区别是每个类周围的边界框被视为生成拒绝样本的区域。
'hyperbox_ring_around_each_class'仅在每个类的边界框周围的放大区域中生成样本,从而在原始样本周围生成超盒环。请注意,随着维数的增加,采样策略'hyperbox_around_each_class'和'hyperbox_ring_around_each_class'提供相同的结果。如果不应使用拒绝类采样策略(默认值),则必须将GenParamValue设置为“no_rejection_class”。
'hyperbox_tolerance':
因子'hyperbox_tolerance'描述了应该在所有维度上放大边界框的量。然后,在该框内,从均匀分布中随机生成样本。默认值为0.2。
'rejection_sample_factor':
拒绝样本的数量是提供的样本的数量乘以'rejection_sample_factor'。如果没有生成足够的样本,则拒绝等级可能无法正确分类。如果拒绝类包含太多样本,则将正常类分类为拒绝类。默认值为1.0。请注意,训练时间将增加一倍,其中是“rejection_sample_factor”的值。
'RANDOM_SEED':
可以使用'random_seed'设置随机种子。默认值为42。
******************************************************************************************************************************
*设置拒绝采样策略'hyperbox_ring_around_each_class'
set_rejection_params_class_mlp (MLPHandle, 'sampling_strategy', 'hyperbox_ring_around_each_class')
*设置拒绝采样策略因子3
set_rejection_params_class_mlp (MLPHandle, 'rejection_sample_factor', .3)
*开始训练,MaxIterations优化算法的最大迭代次数200, WeightTolerance最优算法在两次迭代的不同权重的阈值是1,两次迭代的平均错误的差值阈值0.01,Error训练数据的平均错误, ErrorLog作为一个优化算法的迭代次数函数在训练数据上的平均错误
train_class_mlp (MLPHandle, 200, 1, 0.01, Error, ErrorLog)
for J := 1 to 14 by 1
read_image (Image, 'plastic_mesh/plastic_mesh_' + J$'02')

*缩小图片
zoom_image_factor (Image, ImageZoomed, 0.5, 0.5, 'constant')
*抽取特征图
gen_texture_image (ImageZoomed, ImageTexture)

*裁剪特征图得到需要分类的区域
reduce_domain (ImageTexture, Rectangle, ImageTextureReduced)

*分类
classify_image_class_mlp (ImageTextureReduced, ClassRegions, MLPHandle, 0.5)
*分成两类区域,正确区域和错误的区域

正确区域

错误区域
select_obj (ClassRegions, Correct, 1)
select_obj (ClassRegions, Errors, 2)
* 错误区域开运算和闭运算,去除细小的区域
opening_circle (Errors, ErrorsOpening, 4.5)
closing_circle (ErrorsOpening, ErrorsClosing, 10.5)
connection (ErrorsClosing, ErrorsConnected)
*筛选面积大于100的区域
select_shape (ErrorsConnected, FinalErrors, 'area', 'and', 100, 1000000)
count_obj (FinalErrors, NumErrors)
dev_set_color ('red')
dev_set_draw ('margin')
dev_set_line_width (5)
dev_display (FinalErrors)
if (NumErrors > 0)
disp_message (WindowHandle, 'Mesh not OK', 'window', 10, 10, 'black', 'true')
else
disp_message (WindowHandle, 'Mesh OK', 'window', 10, 10, 'black', 'true')
endif
if (J < 14)
disp_continue_message (WindowHandle, 'black', 'true')
endif
stop ()
endfor
clear_class_mlp (MLPHandle)