为了克服单层神经网络的局限性,神经网络逐渐演变为多层结构。但是,对于多层神经网络的训练,我上一篇所讲过的delta规则【神经网络浅析(单层)】是无效的,因为这个学习规则并没有规定隐含层的误差如何计算。一直到几十年后有人提出了反向传播算法,它是多层神经网络具有代表性的学习规则,因此本文主要围绕BP算法进行讲解。(文中涉及的编程不给出代码,大家可尝试自行编程,如果实在不会,可以看我发布的资源MATLAB代码)
1. 反向传播算法
在反向传播算法中,输出误差从输出层逐层后移,直至达到与输入层相邻的隐含层,因此它规定了隐含层的误差计算规则。为了便于理解,举一个简单例子说明这个算法。
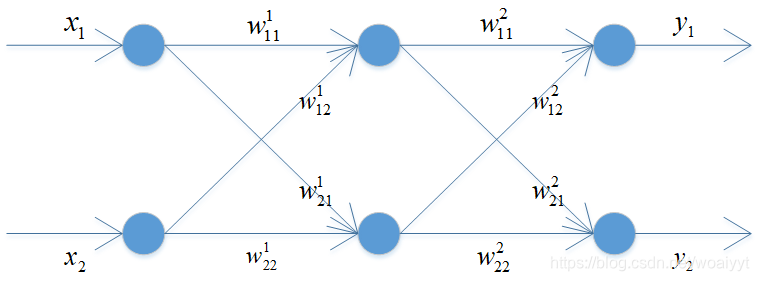
从输入数据到输出节点输出值的计算过程可以参看我所编写的单层神经网络【神经网络浅析(单层)】。在得到神经网络输出之后,接下来就是反向传播算法的核心--------误差计算。对于输出节点的误差,仍然采用广义delta规则进行计算,那么隐含层的输出误差怎么计算呢?其实也是广义delta规则计算,唯一需要理解的是反向传播进行计算,而且在这儿还有一个数学上的对称性,就是反向传播误差计算矩阵其实就是正向传播中权重矩阵的转置,为了对反向传播计算误差有个更好地理解,这里写一个等式
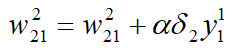
等式右边第一项是其中一个权重值,注意上下标的理解,等式右边第二项采用的是第二个输出节点的误差与第一个隐含层节点的输出,为什么采用这两个与权重的箭头指向有关,一定注意与上下标的关系,这个等式就相当于通过输出层的误差逐层向前推进计算每一个隐含层的误差,不管有多少个隐含层,都是类似的思想。下面总结一下训练过程:
- 用合适的值初始化权重
- 从训练数据获得输入与标准输出,获得神经网络输出后与标准输出比对计算误差以及输出节点的 δ \delta δ值
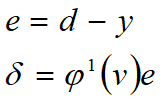
- 反向传播输出节点的 δ \delta δ值,计算紧邻层节点的 δ \delta δ值

- 重复步骤3,直到与输入层紧邻的隐含层
- 调整权重
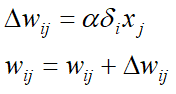
- 对每个训练数据点重复步骤2-5
- 重复步骤2-6,直到神经网络得到合理的训练
2. 实现反向传播算法
考虑四个数据点,每个数据点由四个数据组成,分别是
[0 0 1 0]
[0 1 1 1]
[1 0 1 1]
[1 1 1 0]
每一个数据点的最后一个数据是标准输出,前三个数据时输入。考虑一个这样的神经网络,它由三个输入组成的输入层,四个节点组成的隐含层,一个输出组成的输出层组成,使用Sigmoid函数作为激活函数,采用SGD方法实现,这个问题其实就是XOR逻辑运算。编写好算法后进行测试,训练神经网络10000次,最后结果为
[0.0060 0.9888 0.9891 0.0134]'
可见它与标准输出几乎一致,因此它完美解决了单层神经网络的局限性。
3. 代价函数与学习规则
代价函数是与优化理论相关的一个数学概念,这个非常容易理解。神经网络的监督学习是调整权重以减少训练误差的一个过程,其中神经网络误差的度量就是代价函数,神经网络误差越大,代价函数值就越高,是一个正相关关系。在神经网络监督学习中,代价函数的形式主要有两种:
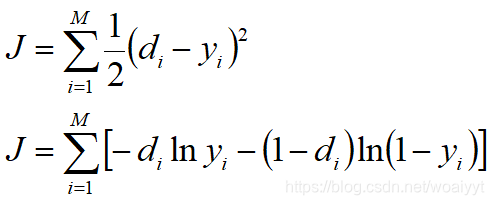
其中 d i d_i di是标准输出, y i y_i yi是输出节点输出, M M M是输出节点数量。第一个代价函数形式容易理解,也就是误差的平方和的一半,关于y轴对称,两个值之间差异越大,代价函数值越大。大多数早期研究神经网络采用这种代价函数,以派生学习规则。现在看第二种形式的代价函数,将中括号以内的公式称为交叉熵函数,它与误差也是正相关的,但是它与第一种形式最大的区别就是其呈几何式增长,也就是它对误差更敏感,因此现在很多人都采用交叉熵函数导出的学习规则。接下来详细介绍采用交叉熵驱动的反向传播算法的步骤:
-
用合适的值初始化权重
-
从训练数据获得输入与标准输出,获得神经网络输出后与标准输出比对计算误差以及输出节点的 δ \delta δ值
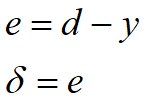
-
反向传播输出节点的 δ \delta δ值,计算紧邻层节点的 δ \delta δ值
-
重复步骤3,直到与输入层紧邻的隐含层
-
调整权重
-
对每个训练数据点重复步骤2-5
-
重复步骤2-6,直到神经网络得到合理的训练
它与第一节介绍的步骤差异只有输出节点的 δ \delta δ值的计算,虽然从表面上看这种差异微不足道,但是其中包含了基于优化理论的代价函数这一重大问题,深度学习的大多数神经网络训练方法都是采用交叉熵驱动的学习规则,其中的关键点是,输出层和隐含层采用不同的delta计算公式。
4. 实现交叉熵函数
本节考虑的模型和第二节一模一样,编程方式也与第二节几乎相同,唯一不同的只是输出节点的delta计算公式,训练神经网络10000次,最后结果为
[0.00003 0.9999 0.9998 0.00036]'
与标准输出一致。
5. 二者比较
因为第二节所示的其实是采用第一种代价函数形式也就是误差平方和驱动的学习规则,因此二者的比较其实就是误差平方和驱动与交叉熵驱动的学习规则的比较,效果见图
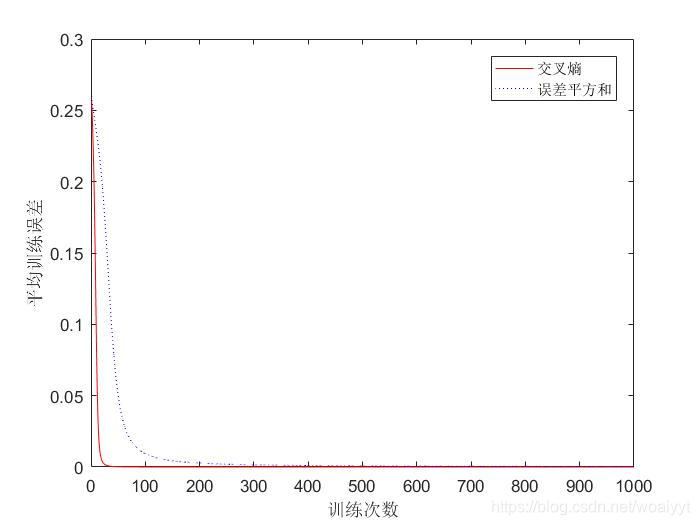
由此可见,交叉熵驱动的学习规则能以更快的速度降低误差,效率更高,学习效果更好。