1. 隐马尔可夫模型(HMM)
在说隐马尔可夫模型前还有一个概念叫做“马尔科夫链”,既是在给定当前知识或信息的情况下,观察对象过去的历史状态对于预测将来是无关的。也可以说在观察一个系统变化的时候,他的下一个状态如何的概率只需要观察和统计当前的状态即可正确得出。隐马尔可夫链和贝叶斯网络的模型思维有些接近,区别在于隐马尔可夫的模型更为简化。而且隐马尔可夫链是一个双重的随机过程,不仅状态转移之间是一个随机事件,状态和输出之间也是一个随机过程。
如下图:
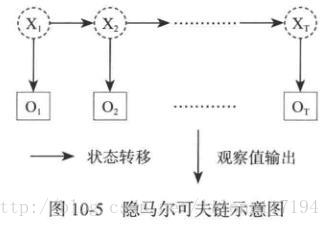
在一个完整的观察过程中有一些状态的转换,如X1X1这些输出值来进行模型建立和计算状态转移的概率。
知乎上一个很好的例子:
https://www.zhihu.com/question/20962240/answer/33438846
对于HMM来说,如果前提知道所有的隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,进行模拟是很容易的。但是往往会缺失一部分信息,如何应用算法去估计缺失的信息,就成为了一个重要的问题。
和HMM模型相关的算法分为3类,分别解决3种问题。
- 知道隐含状态数量、转换概率、根据可见状态链的结果想知道隐含状态链。这个问题在语音识别领域叫做解码问题,求解这个问题有两种方法。第一种是求最大最大似然状态路径(一串骰子序列,使其产生的观测结果的概率最大)。第二种解法是求每次掷出的骰子分别是某种骰子的概率。
- 知道隐含状态数量、转换概率、根据可见状态链的结果想知道产生结果的概率。这个问题的实际意义在于检测观察到的模型是否和已知的模型吻合。如果很多次结果都是对应了比较小的概率,那么就说明已知的模型很可能是错的。
- 知道隐含状态数量、不知道转换概率、根据可见状态链的结果想反推出转换概率。这个问题是最重要的,因为是最为常见的。很多时候只有可见结果,不知道HMM模型中的参数,需要从可见结果估计这些参数。
2. 维特比算法
当马尔科夫链很长时,根据古典概型的分布特点来计算概率时穷举的数量太大,就很难得到结果。这时就要用到维特比算法。维特比算法就是为了找出可能性最大的隐藏序列,即刚刚提到的第一个问题。这种算法是一种链的可能性问题,现在应用最广泛的是CDMA和打字提示功能。
维特比算法的整体思路是寻找上一段信息和它跟随的下一段信息的转换概率问题。
2.1 打字输入提示应用

这是常用的搜狗输入法的示例。在本例中只是考虑最简单的因素,下面是模拟输入法的猜测方法给出一个算法示例,先给出各级转换矩阵。如下:
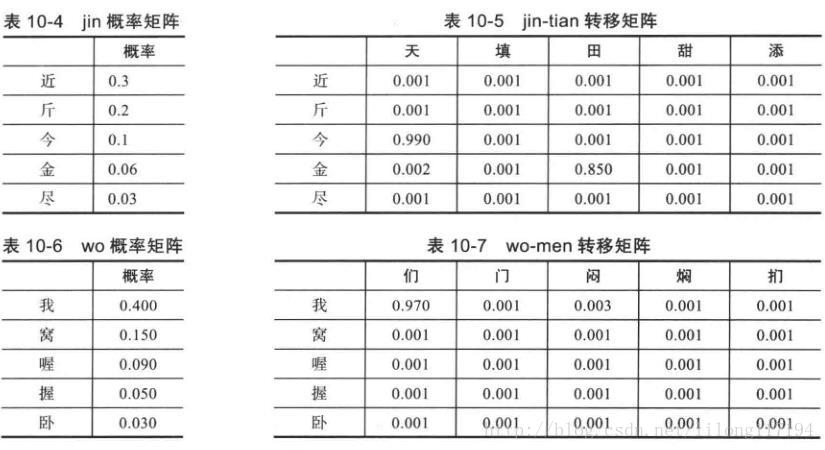
其实这些概率矩阵都是由统计产生,而且每个双字词、三字词等的输入矩阵都由这种统计产生。在输入双字词汉子拼音时会根据转移概率表进行计算。多个词相连就是多个转移矩阵的概率相乘计算,从而得到概率最大的输入可能项。
2.2 代码:
# coding=utf-8
import numpy as np
jin = ['近', '斤', '今', '金', '尽']
jin_per = [0.3, 0.2, 0.1, 0.06, 0.03] # 单字词概率矩阵
jintian = ['天', '填', '田', '甜', '添']
jintian_per = [
[0.001, 0.001, 0.001, 0.001, 0.001], # 转移矩阵
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.990, 0.001, 0.001, 0.001, 0.001],
[0.002, 0.001, 0.850, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
wo = ['我', '窝', '喔', '握', '卧']
wo_per = [0.400, 0.150, 0.090, 0.050, 0.030]
women = ['们', '门', '闷', '焖', '扪']
women_per = [
[0.970, 0.001, 0.003, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
qing = ['请', '晴', '清', '轻', '情']
qing_per = [0.2, 0.12, 0.09, 0.05, 0.02]
qinghua = ['话', '画', '化', '花', '华']
qinghua_per = [
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.950],
[0.001, 0.001, 0.850, 0.001, 0.001],
[0.003, 0.001, 0.001, 0.002, 0.001]]
da = ['大', '打', '达', '搭', '哒']
da_per = [0.300, 0.130, 0.120, 0.110, 0.090]
daxue = ['学', '雪', '血', '薛', '穴']
daxue_per = [
[0.800, 0.140, 0.023, 0.004, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001],
[0.001, 0.001, 0.001, 0.001, 0.001]]
N = 5
# 一个字的预测
def found_from_oneword(oneword_per):
index = []
values = []
a = np.array(oneword_per)
print 'a:',a
print 'argsort(a):',np.argsort(a)[::-1][:N]
for v in np.argsort(a)[::-1][:N]: # 遍历降序前5的概率索引,
index.append(v)
values.append(oneword_per[v])
return index, values
# 一个词的预测
def found_from_twoword(oneword_per, twoword_per):
last = 0
for i in range(len(oneword_per)):
#print oneword_per[i],'\n', twoword_per[i]
current = np.multiply(oneword_per[i], twoword_per[i]) # 字概率乘以转移概率
if i == 0:
last = current
else:
last = np.concatenate((last, current), axis=0) # 字符串拼接
#print 'last:',last # 单个字概率矩阵乘以转移概率矩阵
index = []
values = []
#print np.argsort(last)[::-1][:N]
for v in np.argsort(last)[::-1][:N]: # 概率从大到低的排列(前5个)
index.append([v / 5, v % 5]) # 由数组的索引值得到其在矩阵中的坐标值
values.append(last[v])
print 'index:',index,'\n','values:',values
return index, values
# 字词的预测
def predict(word):
if word == 'jin':
for i in found_from_oneword(jin_per)[0]: # 遍历概率索引值
print jin[i] # 输出排序后的索引对应的值
print '.......................................'
elif word == 'jintian':
for i in found_from_twoword(jin_per, jintian_per)[0]: # 传入的是概率矩阵和转移矩阵
print 'i:',i
# jin[i[0]]:词组在矩阵中的第一个字的下标;jintian[i[1]]:在矩阵中的列表示后一个字的下标
print jin[i[0]] + jintian[i[1]]
print '.......................................'
elif word == 'wo':
for i in found_from_oneword(wo_per)[0]:
print wo[i]
print '.......................................'
elif word == 'women':
for i in found_from_twoword(wo_per, women_per)[0]:
print wo[i[0]] + women[i[1]]
print '.......................................'
elif word == 'jintianwo':
index1, values1 = found_from_oneword(wo_per)
print 'index1, values1:', index1, '\n',values1 # 先得到'wo'的排序
index2, values2 = found_from_twoword(jin_per, jintian_per) # 再得到'jintian'排序
print 'index2, values2:', index2, '\n',values2
last = np.multiply(values1, values1) # 得到'jintian'和'wo'的最大概率乘积
for i in np.argsort(last)[::-1][:N]:
print jin[index2[i][0]], jintian[index2[i][1]], wo[i]
print '.......................................'
elif word == 'jintianwomen':
index1, values1 = found_from_twoword(jin_per, jintian_per) # 得到'jintian'的排序
index2, values2 = found_from_twoword(wo_per, women_per) # 得到'women'的排序
last = np.multiply(values1, values1) # 得到'jintian'和'women'相乘的排序
for i in np.argsort(last)[::-1][:N]:
print jin[index1[i][0]], jintian[index1[i][1]], wo[index2[i][0]], women[index2[i][1]]
print '.......................................'
else:
pass
if __name__ == '__main__':
predict('jin')
# 近
# 斤
# 今
# 金
# 尽
predict('jintian')
# 今天
# 金田
# 近天
# 近填
# 近田
predict('wo')
# 近
# 斤
# 今
# 金
# 尽
predict('women')
# 我们
# 我闷
# 我门
# 我焖
# 我扪
predict('jintianwo')
# 今 天 我
# 金 田 窝
# 近 天 喔
# 近 填 握
# 近 田 卧
predict('jintianwomen')
# 今 天 我 们
# 金 田 我 闷
# 近 田 我 扪
# 近 填 我 焖
# 近 天 我 门
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
运行结果:
a: [ 0.3 0.2 0.1 0.06 0.03]
argsort(a): [0 1 2 3 4]
近
斤
今
金
尽
.......................................
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
i: [2, 0]
今天
i: [3, 2]
金田
i: [0, 0]
近天
i: [0, 1]
近填
i: [0, 2]
近田
.......................................
a: [ 0.4 0.15 0.09 0.05 0.03]
argsort(a): [0 1 2 3 4]
我
窝
喔
握
卧
.......................................
index: [[0, 0], [0, 2], [0, 1], [0, 3], [0, 4]]
values: [0.38800000000000001, 0.0012000000000000001, 0.00040000000000000002, 0.00040000000000000002, 0.00040000000000000002]
我们
我闷
我门
我焖
我扪
.......................................
a: [ 0.4 0.15 0.09 0.05 0.03]
argsort(a): [0 1 2 3 4]
index1, values1: [0, 1, 2, 3, 4]
[0.4, 0.15, 0.09, 0.05, 0.03]
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
index2, values2: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
[0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
今 天 我
金 田 窝
近 天 喔
近 填 握
近 田 卧
.......................................
index: [[2, 0], [3, 2], [0, 0], [0, 1], [0, 2]]
values: [0.099000000000000005, 0.050999999999999997, 0.00029999999999999997, 0.00029999999999999997, 0.00029999999999999997]
index: [[0, 0], [0, 2], [0, 1], [0, 3], [0, 4]]
values: [0.38800000000000001, 0.0012000000000000001, 0.00040000000000000002, 0.00040000000000000002, 0.00040000000000000002]
今 天 我 们
金 田 我 闷
近 田 我 扪
近 填 我 焖
近 天 我 门
.......................................
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
从运行结果可以看出其实就是通过统计得到的概率矩阵和转移矩阵的乘积之后的排序计算。
3. 笔记
3.1 for v in np.argsort(a)[::-1][:N]的用法:
In [7]: a=array([1, 2, 3])
In [8]: a
Out[8]: array([1, 2, 3])
In [9]: a[::-1]
Out[9]: array([3, 2, 1])
In [10]: a[::-1][:3]
Out[10]: array([3, 2, 1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.2 last = np.concatenate((last, current), axis=0)的使用:
>>> import numpy as np
>>> a = np.array([[1, 2], [3, 4]])
>>> a
array([[1, 2],
[3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
参考:《白话大数据与机器学习》