1、前言
前面学习了很多机器学习的算法,大都是优化问题,最小化损失函数,其中一个重要的方法就是梯度下降,不断的更新参数,不断的降低损失值。
神经网络也不例外,同样是最小化损失函数,同样是使用梯度下降的方法。但是区别就在于得到梯度的方式不同。一种说法是神经网络能够有效的降低求梯度的计算量,从而减少迭代时间。
2、举例说明
以下图这个的全连接神经网络为例子,一步一步的来理解整个流程:
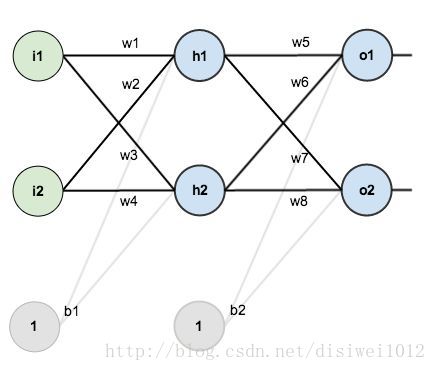
第一层是输入层,也就是我们的样本;第二层是隐藏层;第三层是输出层,获得估计值
下面给出这个例子的损失函数,我们的目标就是不断更新w,使 不断减小。(本例子中暂不考虑正则化惩罚项、使用sigmoid为激励函数)
具有初始值的变量包括:i1、i2、w1、w2、w3、w4、w5、w6、w7、w8、b1、b2
前向传播
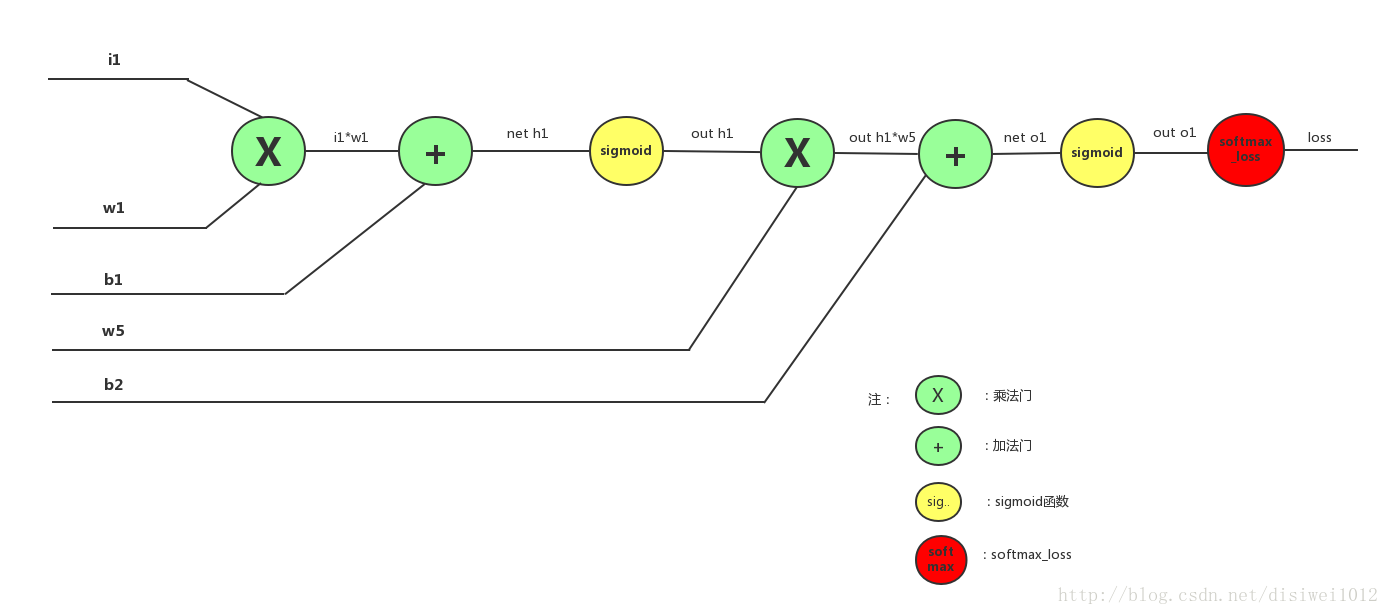
上图以单个样本i1为例(其他样本相似)详细表达了具体前向传播的流程:
1、首先i1与w1通过乘法得到i1*w1,然后i1*w1与b1通过加法门得到net h1,即
2、net h1通过sigmoid函数变换,得到out h1,即
3、out h1与w5通过乘法门,然后与b2通过加法门得到net h2,即
4、net o1通过sigmoid函数变换,得到out 01,即
6、out o1通过softmax_loss函数变换,得到具体损失值loss,即
前向传播就是一个求中间变量和损失值的过程,所求得的损失值就是为了反向传播,更新w、b参数
注:
①sigmoid函数只是激励函数的一种,类似的还有relu、tanh函数等;
②softmax_loss函数只是计算损失值的一种,类似的还有SVM等;
反向传播(BP算法)
首先要明白一点,反向传播的目的是什么?
在上面我们求得了损失值,损失值越大说明我们预测(分类)的越不准确,我们知道最终的预测值是和权重参数w、b相关的,所以我们就需要调整参数的大小,那么怎么调整呢?每个参数应该调整多大合适呢?
对于损失值,每个参数的所起到的作用是不一样的,可以通过链式求(即求梯度的过程)导获得每一个参数对最后损失值所起作用的大小,然后更新参数,进而降低损失值。
下面先求w1对损失值的梯度 ,从后往前,一步一步来:
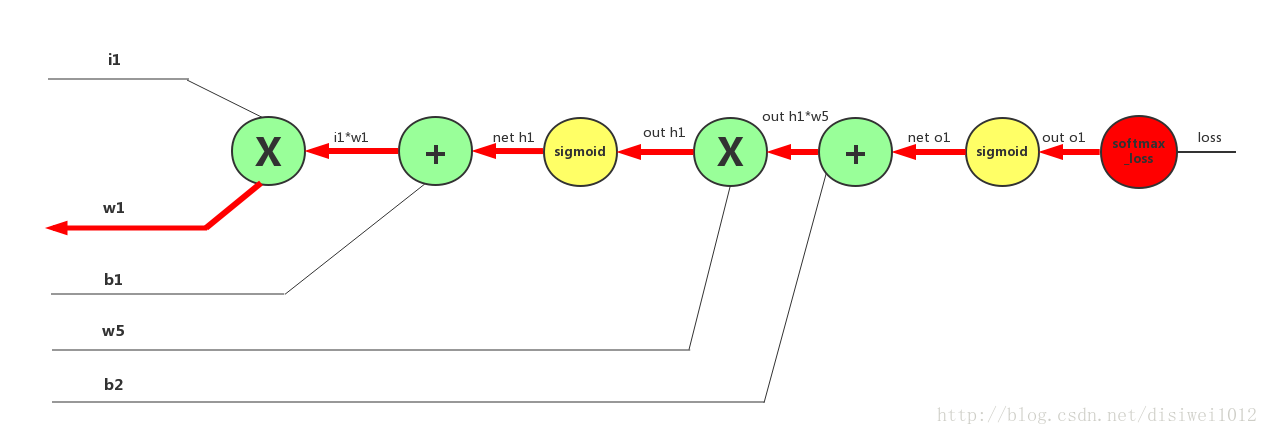
对于图片中的每一个门单元(每个圆圈)求导然后相乘就是我们想要的 (本图还是以一个样本i1为例子)
对于乘法门和加法门求导的规则这里不详细赘述,加法门可以忽略,乘法门交换律
(softmax 交叉熵损失求导)
softmax 交叉熵损失求导参考:http://blog.csdn.net/qian99/article/details/78046329
sigmoid函数求导参考:http://blog.csdn.net/vincent2610/article/details/53811323
最终得到,其他参数同理可得:
更新权重参数
得到w1的梯度之后,就可以更新w1了,下面的式子中r表示学习率:
3、代码实现(激活函数tanh)
import numpy as np
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 手动生成一个随机的平面点分布,并画出来
np.random.seed(0)
X, y = make_moons(200, noise=0.20)# 咱们先顶一个一个函数来画决策边界
def plot_decision_boundary(pred_func):
# 设定最大最小值,附加一点点边缘填充
# 第一列最小值、最大值
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
# 第二列最小值、最大值
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 用预测函数预测一下
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 然后画出图
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)num_examples = len(X) # 样本数
nn_input_dim = 2 # 输入的维度
nn_output_dim = 2 # 输出的类别个数
# 梯度下降参数
epsilon = 0.01 # 学习率
reg_lambda = 0.01 # 正则化参数
# 定义损失函数(才能用梯度下降啊...)
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 向前推进,前向运算
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 计算损失
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# 也得加一下正则化项
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss# 完整的训练建模函数定义
def build_model(nn_hdim, num_passes=20000, print_loss=False):
'''
参数:
1) nn_hdim: 隐层节点个数 3
2)num_passes: 梯度下降迭代次数
3)print_loss: 设定为True的话,每1000次迭代输出一次loss的当前值
nn_output_dim 类别
nn_input_dim 样本维度
'''
# 随机初始化一下权重呗
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# 这是咱们最后学到的模型
model = {}
# 开始梯度下降...
for i in xrange(0, num_passes):
# 前向运算计算loss
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 反向传播
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# 加上正则化项
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# 梯度下降更新参数
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# 得到的模型实际上就是这些权重
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# 如果设定print_loss了,那我们汇报一下中间状况
if print_loss and i % 1000 == 0:
print "Loss after iteration %i: %f" %(i, calculate_loss(model))
return model# 判定结果的函数
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 前向运算
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
# 计算概率输出最大概率对应的类别
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)# 建立隐层有3个节点(神经元)的神经网络
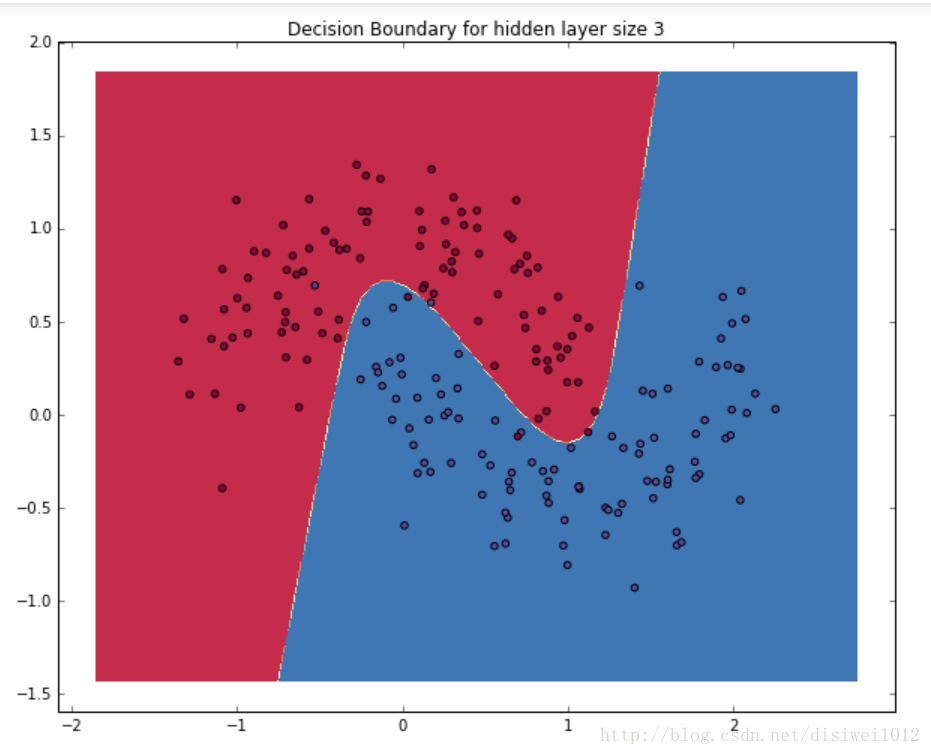
model = build_model(3, print_loss=True)
# 然后再把决策/判定边界画出来
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
plt.show()