笔者在阅读论文的过程中,发现论文中经常会涉及到一些经典的神经网络结构,尽管这些结构可能出现的时间,但是生生不息,经历住了时间的考验。在这个系列文章中,我将对那些经典的网络分别做一个简单介绍。
作为这个系列文章的第一篇文章,本文首先要介绍的是 Group convolution这个结构。
Group Convolution简介
Group Convolution,即分组卷积(也被译为群卷积),是由Alexnet首先提出来的。当时的设备硬件资源有限,研究人员为了解决现存不够的问题,把网络在两个GPU上进行训练,然后将训练得到的结果进行融合即得到最终的结果。
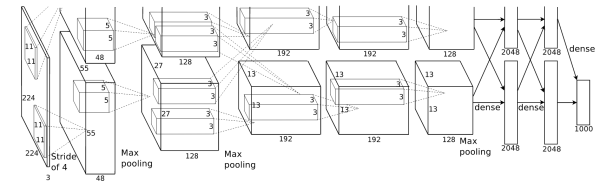
除了可以解决显存不足的问题之外,文章的作者Alex还认为用这种方法还可以增加卷积核之间的对角相关性,而且能够减少训练过程的冗余参数,不容易过拟合,这类似于正则的效果。
Group Convolution与传统卷积的对比
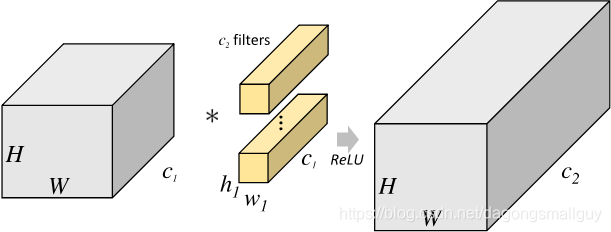
从下图中我们可以发现,对于输入的数据,传统卷积对所有的数据统一进行计算。在下图中的输入数据大小为 ,卷积核大小为 ,共有 ,则在经过卷积之后,我们得到的特征图大小为 。这个过程可以很好的完成图像特征的提取任务,但是所有的数据同时完成,对显存的要求比较高。
在Group Convolution中,我们并不是一次性对输入数据进行处理,而是将其分成了g类。如果上一层的输出feature map有C1个,即通道数channel=C1时,经过Group Convolution后每g个通道被合成为一个group,一共分成C1/g个channel,这些channel之间独立连接,等个股group都卷积完成之后再把输出concatenate在一起,生成这个层的最终输出结果(channel)
如下图是一个群卷积的CNN结构。filters被分成了两个group。每一个group都只有原来一半的feature map。

Group convolution的作用
总结来看,Group convolution一方面可以减小显存的工作压力,另一方面可以减少冗余参数,防止模型过拟合。
单纯增加卷积核输入可以在一定程度上提高效果,但是卷积核数目过多时,冗余参数过多会导致过拟合,运用Group convolution之后,每组的卷积核提取的特征相似度比较低,大大减轻冗余现象。当然,
当然,Group convolution本身就极大地减少了参数。比如当输入通道为256,输出通道也为256,kernel size为3×3,不做Group convolution参数为256×3×3×256。实施分组卷积时,若group为8,每个group的input channel和output channel均为32,参数为8×32×3×3×32,是原来的八分之一。而Group convolution最后每一组输出的feature maps应该是以concatenate的方式组合。