每周汇报,实属不易。近期学习了关于动态卷积的相关内容,写成一个小节,帮助理解什么为动态卷积。内容较为宽泛,若想学习细节知识,可以参考论文。和知乎链接:https://zhuanlan.zhihu.com/p/141868898?from_voters_page=true
首先看到的是这篇ICLR2022年的文章:omni dimensional dynamic convolution
但为了理解这一篇文章,需要了解关于动态卷积的相关工作。因此,阅读了改文章引用的两片最重要的参考文献,因此在这里一起分享学习。
第一篇是:CondConv: Conditionally Parameterized Convolutions for Efficient Inference。发表于2019 NIPS。第二篇是:Dynamic Convolution: Attention over Convolution Kernels。 发表于2020 CVPR。读完这两篇文章,再看Omni dimensional dynamic convolution,理解起来会简单一些。
第一篇算是动态卷积的基础工作。解释了什么是动态卷积,与第二篇基本思路是相同的。这一篇文章中,作者解释了以往的卷积神经网络的特点:静态网络基本的前提是同一个卷积核,会应用到所有的数据集上。此外,之前的卷积神经网络的另一个特点是,通过扩展宽度、深度、分辨率来提升网络模型的表现。作者还提到:在以往的注意力模型中,注意力主要是应用到特征图上。比如在特征图不同的通道上进行加权(SE Net),在特征图不同的空间位置加权(Spatial attention)。但在本文中,作者提出了对卷积核进行加权。也就是说,对于不同的输入,我们使用不同的卷积核。之后对这些不同的卷积核,进行注意力加权。

这里的ROUTE FN是指Routing Function,可以理解为一个注意力机制吧。相当于GAP+FC+Sigmoid。看图1b中,不同的W,相当于不同的权重,不同的卷积核。每一条路径就是一个专家(expert)。然后通过Combine加权操作。但是这样计算量太大了。因此作者提出了图1a的方法。并使用公式证明了两种方法是等效的。如下面公式所示:
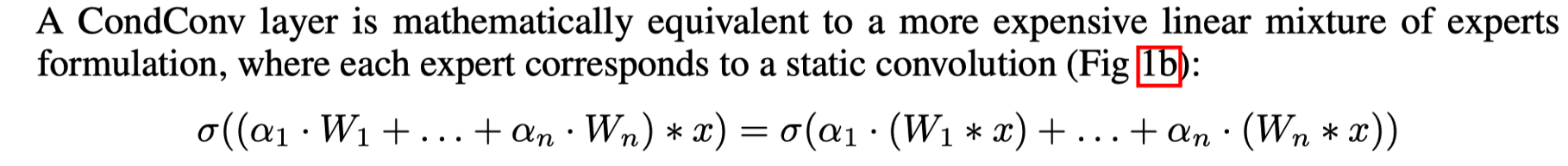
左边就是图1a的公式表达,右边是图1b的公式表达。两种表达是等效的。但可以极大减小计算量。之后就是使用了一系列的实验,来验证文章所提到的观点了。先了解细节必须要看论文。实在没空看的话,看上面那个知乎。
之后我就去阅读了第二篇文章:Dynamic Convolution: Attention over Convolution Kernels。这篇文章引用了上一篇文章,并做出了改进。

首先它通过实验证明了,动态卷积层中这个attention模块是非常重要的。在上一篇中就是指那个ROUTE FN模块。这一篇中就是指图3的attention模块。如果没有这个attention,动态卷积层没有作用,并给出了实验数据作为支持。
之后,针对参数约束上,提出了改进观点。他认为:约束注意力输出可以促进注意力模型 π k(x) 的学习。因此设置了 π k(x) 的和为1的约束条件。可以参考图4. 图4使用了三个卷积核构成了三维空间,是为了方便可视化。也可以使用2个构成二维平面。三个参数和为1的话,就构成了 π1+ π2+ π3 = 1的平面。这样缩小了核空间。
此外,注意力机制方面,他提出了改进观点。上一篇中是GAP+FC+Sigmoid,在这一篇中,他提出使用GAP+FC+ReLU+FC+Sofmax的方法。也就是squeeze-and-excitation(SE Net)的方法,只不过SE Net通道注意力分配给了输出的特征图,而这篇文章中提取的注意力分配给不同的卷积核上。在此观点上,作者继续研究了Softmax函数的参数,如何影响训练误差曲线的收敛速度的问题。
这两个改进是该方法与使用 sigmoid 计算内核注意力的 CondConv 之间的主要区别。
现在可以探讨最后一篇文章:Omni dimensional dynamic convolution了。作者总结了前人的关于动态卷积的工作,引入了两篇重要的参考文献,也就是刚才所提到的这两篇。作者认为:最近对动态卷积的研究表明,学习 n 个卷积核的线性组合及其输入相关注意力可以显着提高轻量级 CNN 的准确性,同时保持有效的推理。然而,现有的工作通过内核空间的一维(关于卷积核数)赋予卷积核动态属性,但其他三个维度(关于空间大小、输入通道数和输出通道数) 每个卷积核)都被忽略了。 受此启发,作者提出了全维动态卷积(ODConv)。
也就是说,之前两篇讲到的都只是通过在卷积核个数上进行加权,而 ODConv 利用一种新颖的多维注意力机制和并行策略,在任何卷积层沿内核空间的四个维度学习卷积内核的注意力。 作为常规卷积的替代品,ODConv 可以插入到许多 CNN 架构中。也就是说是的即插即用的模块。下图表示了ODConv与之前两篇文章的区别。

这四个不同的注意力就是:卷积核的输入通道数,卷积核自身的感受野,卷积核的输出通道数,和卷积核的个数。下图可以表示ODConv四种注意力机制的作用。

然后文章的后面就是实验和分析部分了,这里就不讲了。因为实验和分析都是为了证明所提出的理论的,作者通过大量实验,验证了他所提出的卷积不同层面上注意力的有效性。