刚写完京东爬虫,趁着记忆还深刻,写点总结吧。
一、前提
默认已用scrapy爬取过网站,有爬虫基础,有爬虫环境
二、以爬取电子烟为例
1、任务一:爬取商品信息
在搜索框里面直接搜索电子烟,搜出来的界面,你会发现它是动态加载的。即一开始源代码里面只能看到30条商品的信息,随着你的下拉,另外30条才会加载出来。因此爬取起来比较麻烦。后来发现,从京东左边的商品分类中找到电子烟这一分类
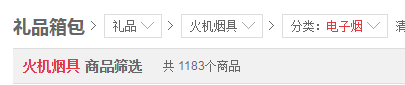
此时的搜索到的电子烟分类的展示网页是一开始就已加载了全部60条商品信息的。商品信息准备从这一页入手。
有爬虫基础的很快就能知道下一步要怎么做了,首先我们需要获得每个商品的信息和链接,称搜索出来的展示页面为搜索页面,进入到商品的详情页面为详情页面。
(1)我们先从搜索页的处理开始

通过抽取<li class="gl-item"> 标签,很快能得到商品的信息。
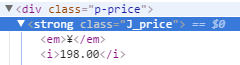
从搜索页面能抓取到商品的ID,详情页链接,商品名字,店铺名字这些信息。而价钱是动态加载的,注意千万不要被检查(就是chrome通过右键点击检查看到的代码)误解。爬虫爬到的是源代码,检查看到的代码和源代码的代码是不一样的。以源代码为主。
这是检查看到的代码
这是源代码看到的代码
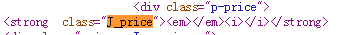
不信可以用爬虫爬取网页试试。所以确定价钱通过网页爬取不到,需要另想办法,先放下。
商品的评论数,你会发现你在搜索页看到的评论数和进入商品详情页看到的评论数不一样,详情页的评论数多一些。因此准备以商品详情页为主,先放下。
搜索页暂时只能爬取到这些信息了。下面进入详情页。
这部分代码如下:
def parse(self, response): # 解析搜索页
sel = Selector(response) # Xpath选择器
goods = sel.xpath('//li[@class="gl-item"]')
# print 'goods'
# print len(goods) # 总共60条商品信息
for good in goods:
item1 = goodsItem()
item1['ID'] = good.xpath('./div/@data-sku').extract()
item1['name'] = good.xpath('./div/div[@class="p-name"]/a/em/text()').extract()
item1['shop_name'] = good.xpath('./div/div[@class="p-shop"]/@data-shop_name').extract()
item1['link'] = good.xpath('./div/div[@class="p-img"]/a/@href').extract()
url = "http:" + item1['link'][0] + "#comments-list"
# print detail
yield scrapy.Request(url, meta={'item': item1}, callback=self.parse_detail)(2)第二步解析详情页
想想我们还需要什么信息,商品信息的话就还有价钱和评论数没有取到了,通过查看详情页的源代码很遗憾地发现,评论数和价钱都是动态加载的。没办法直接抓取详情页抓取到。既然是动态加载的,那么我们就看看都加载了哪些文件,然后从那些文件中去找。
这里默认用的是谷歌浏览器
在详情页点击右键->检查->network->刷新详情页
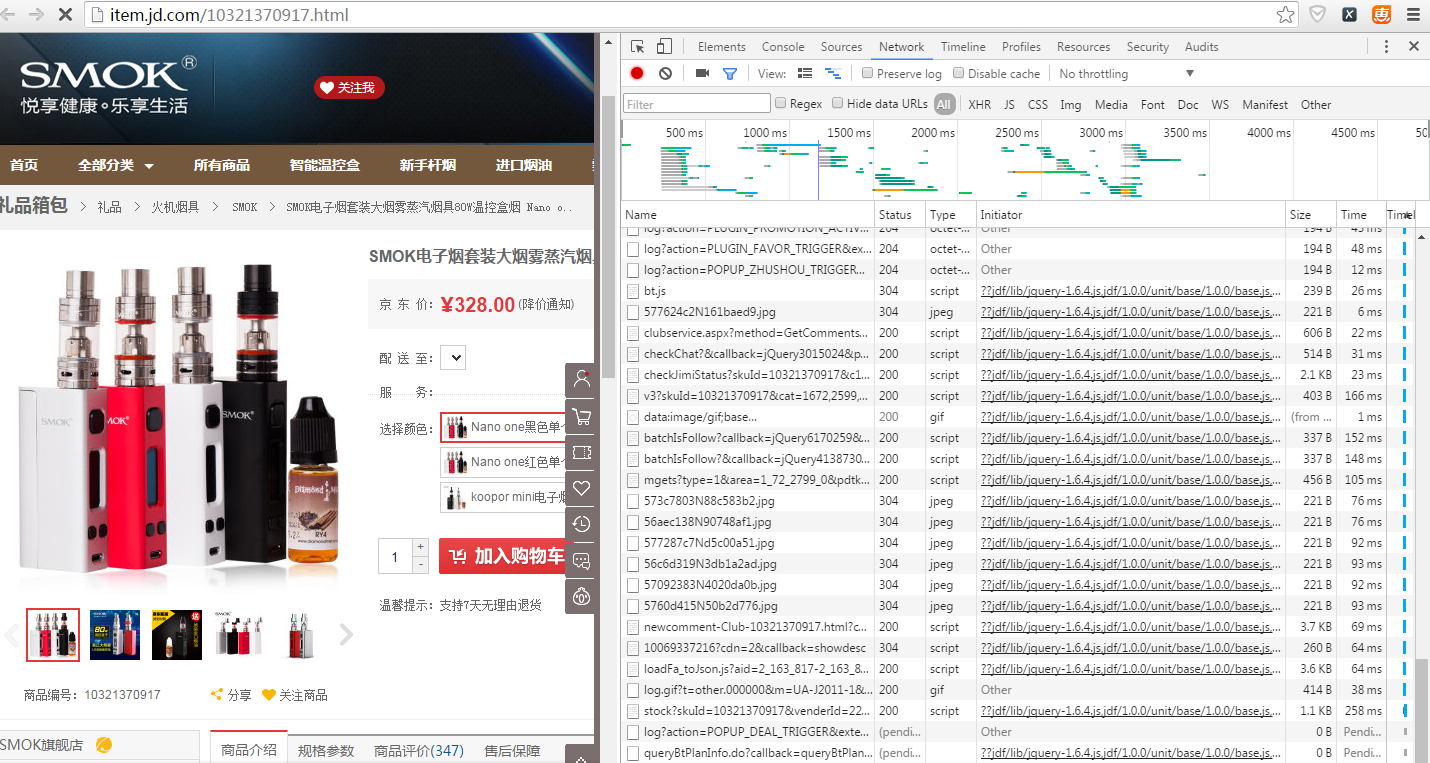
发现加载了好多东西,没关系,不要怕,慢慢看。点击Type进行排序,主要看script文件就好。
咦。。发现一个script文件里面有GetCommentsCount这个方法,这不就是得到评论数的文件么。点开来看

里面的内容是json格式的,放入在线json解析网站解析一下
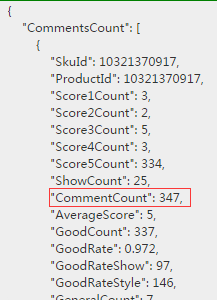
正好有我们想要的。对比一下详情页,该条商品确实是 347条,另外该json里面还有其他信息。Score1Count 应该是指该商品一颗星的评论数,Score2Count指的是二颗星的评论数,而详情页中只有好评,中评,差评。随便算算就知道好评指的是:五颗星+四颗星的,中评是三颗星+两颗星的,差评是一颗星的。对比一下,bingo,数是对的。
好了,信息找到了,下面该看看这个文件的地址了,
原始地址是:http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds=10321370917&callback=jQuery8556269&_=1467795361109
有很多数,很快就能发现referenceIds=10321370917 就是商品的ID,在爬取搜索页的时候不是存了商品的ID吗,这个数字的来源解决。
尝试着删了最后的 &callback=jQuery8556269&_=1467795361109 发现网页不变。哈哈。正好,那就删掉这部分。问题解决。
只需要爬取网页:http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds= 这里加上要抓取的商品ID即可。
这部分代码如下:
def parse_detail(self, response):
item1 = response.meta['item']
sel = Selector(response)
# item1['comment_num'] = sel.xpath('//div[@id="summary"]//a[@href="#comment"]/text()').extract()
temp = response.body.split('commentVersion:')
pattern = re.compile("[\'](\d+)[\']")
if len(temp) < 2:
item1['commentVersion'] = -1
else:
match = pattern.match(temp[1][:10])
item1['commentVersion'] = match.group()
url = "http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds=" + str(item1['ID'][0])
yield scrapy.Request(url, meta={'item': item1}, callback=self.parse_getCommentnum)这里为什么要存储commentVersion这个变量,后面再说,在爬取评论的时候会用到这个参数。
接下来就是解析json串的事了。
这部分代码如下:
def parse_getCommentnum(self, response):
item1 = response.meta['item']
# response.body是一个json格式的
js = json.loads(str(response.body))
# js = json.loads(str)
# print js['CommentsCount'][0]['Score1Count']
item1['score1count'] = js['CommentsCount'][0]['Score1Count']
item1['score2count'] = js['CommentsCount'][0]['Score2Count']
item1['score3count'] = js['CommentsCount'][0]['Score3Count']
item1['score4count'] = js['CommentsCount'][0]['Score4Count']
item1['score5count'] = js['CommentsCount'][0]['Score5Count']
item1['comment_num'] = js['CommentsCount'][0]['CommentCount']
num = item1['ID'] # 获得商品ID
s1 = str(num)
url = "http://pm.3.cn/prices/pcpmgets?callback=jQuery&skuids=" + s1[3:-2] + "&origin=2"
yield scrapy.Request(url, meta={'item': item1}, callback=self.parse_price)然后就只剩下价钱了,同样的方法,刷新页面看加载的文件。看price在哪个文件中。

这个文件的名字好像看不到里面包含了价钱信息,我也是找了很久才发现。

有的有pcp和p值还不一样,在首页上找到相应的数字就会发现,pcp出现的时候是商品在电脑端购买和手机客户端购买的价钱不一样时,pcp是电脑端的价钱。所以在抽取的时候如果有pcp值就抽取pcp,没有pcp,就用p的值。
信息找到了,现在看看网址:
http://pm.3.cn/prices/pcpmgets?callback=jQuery8132619&skuids=10321370917&origin=2&source=1&area=1_72_2799_0&_=1467796414912
老套路,删些不知道是什么数字试试网页会不会变。尝试后发现可以把链接缩成:
http://pm.3.cn/prices/pcpmgets?callback=jQuery&skuids=10321370917&origin=2
其中skuids后面接的是商品ID, origin=2 固定就好
这部分代码如下:
def parse_price(self, response):
item1 = response.meta['item']
temp1 = response.body.split('jQuery([')
s = temp1[1][:-4] # 获取到需要的json内容
# str = str.decode("gbk").encode("utf-8")
# js = json.loads(unicode(str, "utf-8"))
js = json.loads(str(s)) # js是一个list
if js.has_key('pcp'):
item1['price'] = js['pcp']
else:
item1['price'] = js['p']
return item1到此,商品信息已经抓取完毕
数据库如下图所示:
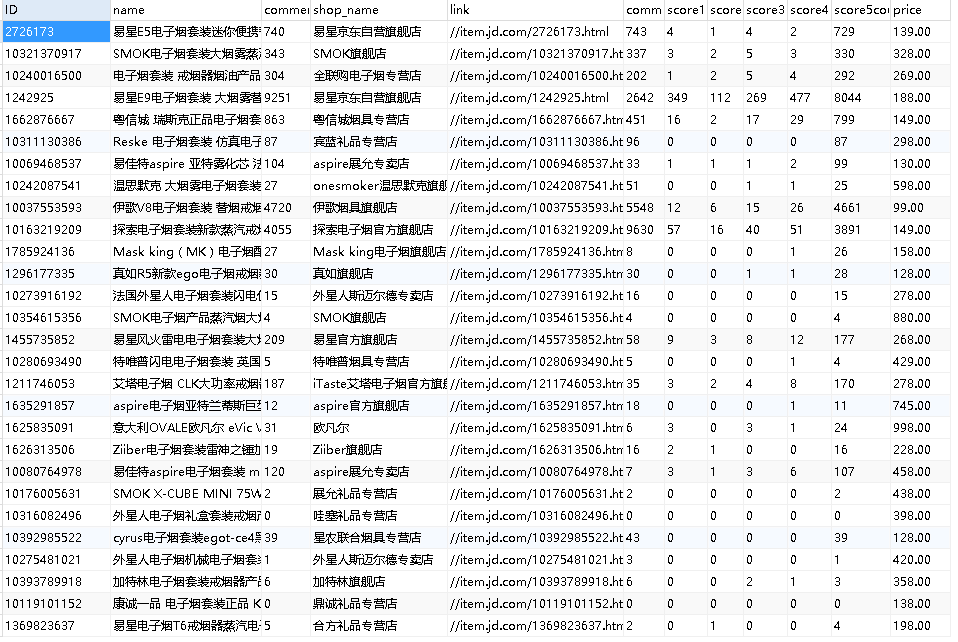
全部代码已上传github:
https://github.com/xiaoquantou/jd_spider