2、任务二:爬取商品评论信息
如果不需要爬取用户的地域信息,那么用这个网址爬就好:
http://club.jd.com/review/10321370917-1-1-0.html
其中10321370917是商品的ID,评论的第一页就是 -1-1-0.html, 第二页就是-1-2-0.html。
之前商品不是存了评论总数吗,一页30个评论,除一下就可以知道多少页了,或者直接抓取下一页的链接也行。
但是这里的评论是没有用户地区信息的。下面放两个图对比一下
没地区信息的:
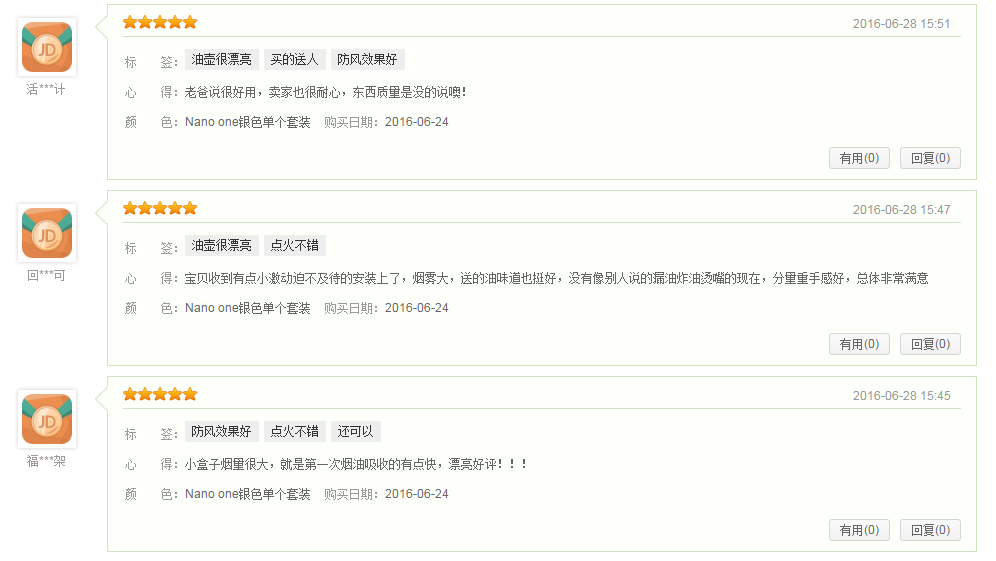
有地区信息的:
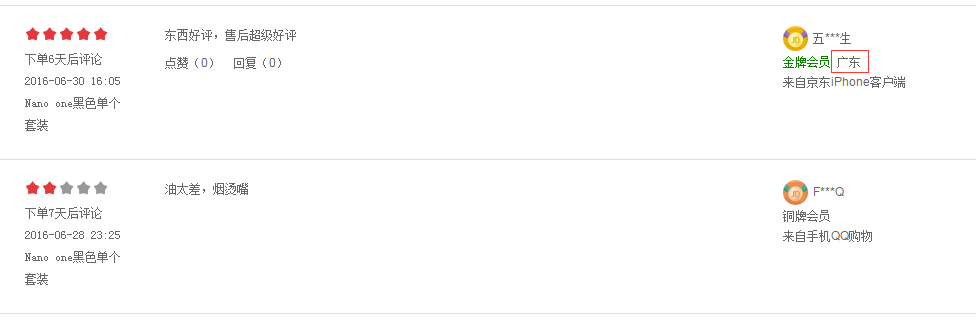
因此如果不需要地区信息,就按上面的方法抓取就好,很简单。但是如果要地区信息的话,就会复杂一些了。因为你会发现商品详情页中的评论也是动态加载的,不管你点第一页,网址都不变。
老套路,从评论第一页点到第二页看network,看都加载了什么文件,找出有评论信息的文件。
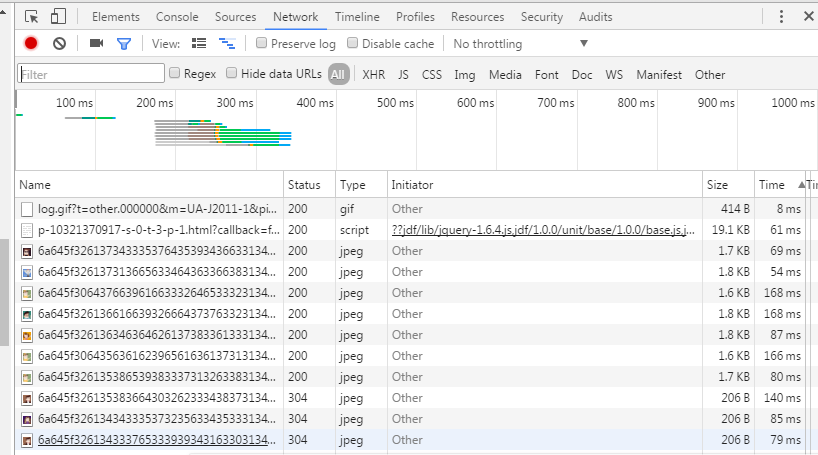
这个比起前面的就少太多东西了。而且只有一个script文件,不用找,就是它了,点开看看。
很多东西,用在线json解析网站解析一下,对比一下详情页的评论发现可以对应上。接下来看看网址:
http://sclub.jd.com/productpage/p-10321370917-s-0-t-3-p-1.html?callback=fetchJSON_comment98vv341
10321370917 是商品ID,第一页是s-0-t-3-p-1 第二页是s-0-t-3-p-2 第三页是s-0-t-3-p-3 这个规律试一试就知道了
fetchJSON_comment98vv341去不掉,而且修改341网页也会变。这时候我们需要去找找这个341在哪。
点开详情页的源代码,ctrl+F搜索一下341,发现有一个叫commentVersion的东西,所以在抓取详情页的时候需要存一下commentVersion后面的值,在这里会用到。
看到上一篇抓取商品信息博文的就知道,之前有个铺垫。
这部分代码:
def parse(self, response):
temp1 = response.body.split('productAttr')
# if len(temp1) < 2:
# item2 = commentItem()
# item2['content'] = response.url.encode('utf-8')
# return item2
#
str = '{"productAttr' + temp1[1][:-2]
str = str.decode("gbk").encode("utf-8")
js = json.loads(unicode(str, "utf-8"))
comments = js['comments'] # 该页所有评论
items = []
for comment in comments:
item1 = commentItem()
item1['user_name'] = comment['nickname']
item1['user_ID'] = comment['id']
item1['userProvince'] = comment['userProvince']
item1['content'] = comment['content']
item1['good_ID'] = comment['referenceId']
item1['good_name'] = comment['referenceName']
item1['date'] = comment['referenceTime']
item1['replyCount'] = comment['replyCount']
item1['score'] = comment['score']
item1['status'] = comment['status']
title = ""
if comment.has_key('title'):
item1['title'] = comment['title']
item1['title'] = title
item1['userRegisterTime'] = comment['userRegisterTime']
item1['productColor'] = comment['productColor']
item1['productSize'] = comment['productSize']
item1['userLevelName'] = comment['userLevelName']
item1['isMobile'] = comment['isMobile']
item1['days'] = comment['days']
tags = ""
if comment.has_key('commentTags'):
for i in comment['commentTags']:
tags = tags + i['name'] + " "
item1['commentTags'] = tags
items.append(item1)
return items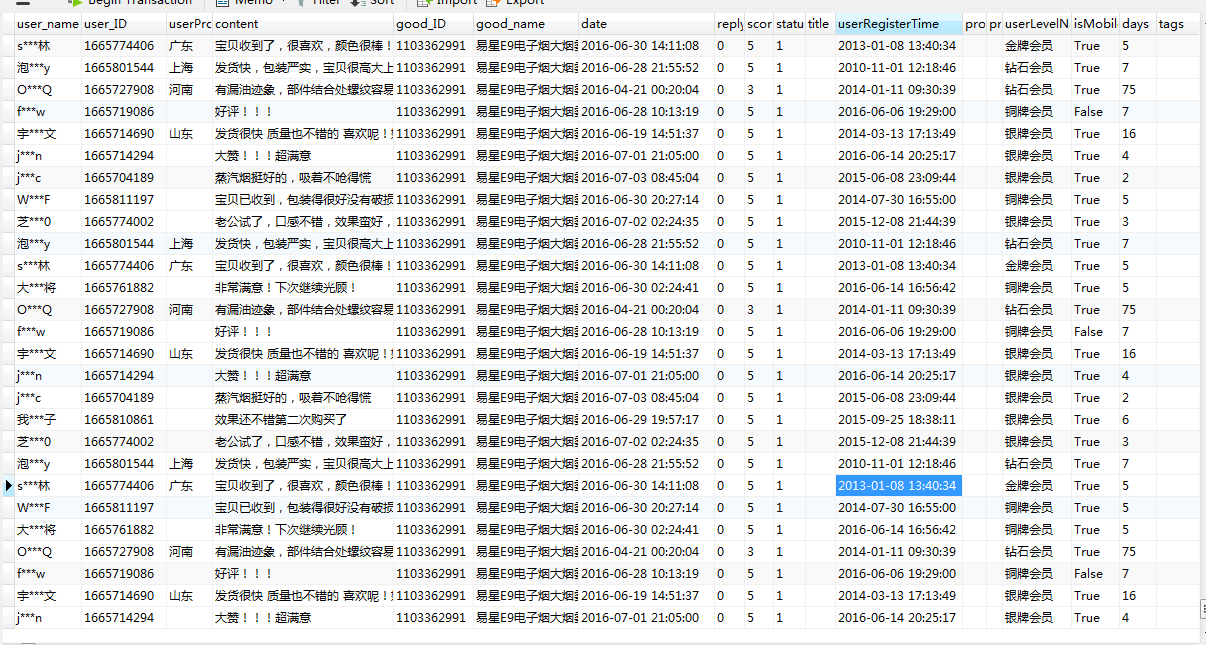
全部代码已上传github:
https://github.com/xiaoquantou/jd_spider