各类算法 预测糖尿病:
见我原文:KNeighbors 糖尿病预测
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 加载数据
data = pd.read_csv(r'C:\Users\Qiuyi\Desktop\scikit-learn code\code\datasets\pima-indians-diabetes\diabetes.csv')
print('dataset shape {}'.format(data.shape))
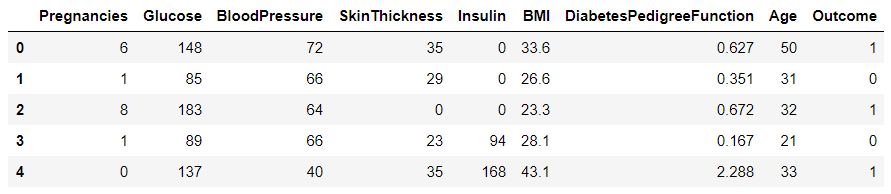
data.head()
dataset shape (768, 9)
将特征和标签(列)分离:
X = data.iloc[:, 0:8]
Y = data.iloc[:, 8]
print('shape of X {}; shape of Y {}'.format(X.shape, Y.shape))
shape of X (768, 8); shape of Y (768,)
将数据及分成训练集和测试集:
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
逻辑回归算法:
sklearn.linear_model.LinearRegression
支持向量机:
决策树:
sklearn.tree.DecisionTreeClassifier
AdaBoost(自适应增强):
扫描二维码关注公众号,回复:
4615689 查看本文章

sklearn.ensemble.AdaBoostClassifier
朴素贝叶斯:
sklearn.naive_bayes.GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.naive_bayes import MultinomialNB
models = []
models.append(("KNN", KNeighborsClassifier(n_neighbors=2)))
models.append(("LR",LinearRegression()))
models.append(("SVC",SVC()))
models.append(("DTC",DecisionTreeClassifier()))
models.append(("AdaBoost",AdaBoostClassifier()))
models.append(("GNB",MultinomialNB()))
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print("name: {}; cross val score: {}".format(
results[i][0],results[i][1].mean()))
name: KNN; cross val score: 0.7147641831852358
name: LR; cross val score: 0.2580299922161077
name: SVC; cross val score: 0.6510252904989747
name: DTC; cross val score: 0.6951982228298018
name: AdaBoost; cross val score: 0.7539473684210527
name: GNB; cross val score: 0.5909603554340397
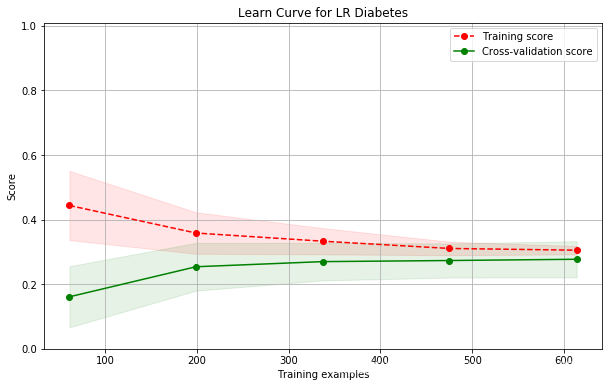
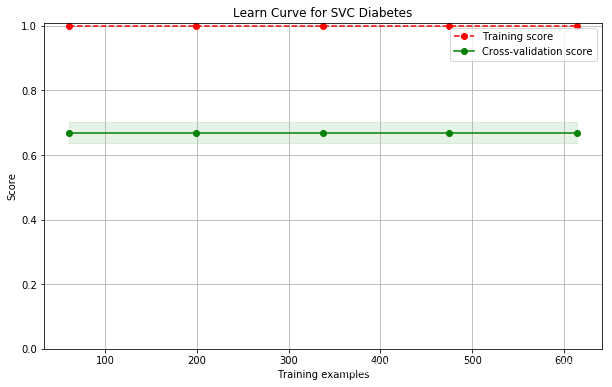
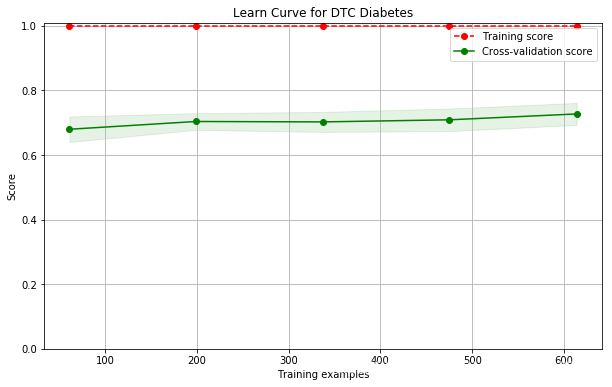
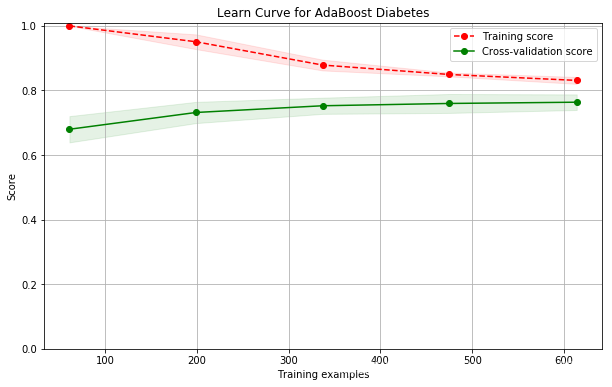
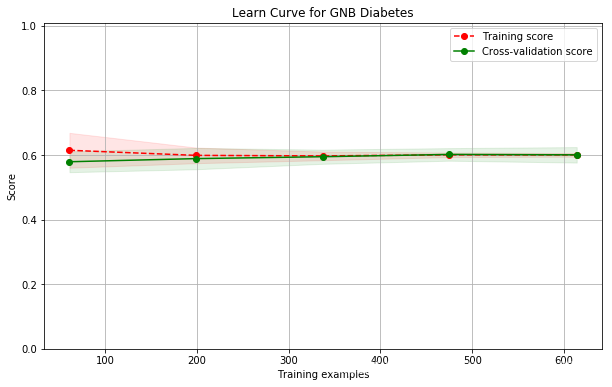
现在还不会调,以后再改进。