- CVPR 2017-oral
背景
-
图像语义分割是计算机视觉领域的核心研究问题之一。一般来讲,训练高性能的语义分割模型需要依赖于大量的像素级的人工标注(即标注每个像素点的语义信息)。然而,标注这类的训练样本非常困难,往往需要大量的金钱和时间。为了降低获取训练样本的难度,研究人员提出采用一些相对容易获取的标注作为监督信息(我们称之为弱监督),并用于训练图像语义分割模型。目前这些弱监督信息主要包括了bounding boxes,scribbles,points和labels,如图1。

-
在这些弱监督信息中,图像的labels标注最容易获取,我们着重研究如何利用图像的labels作为监督信息,训练出用于语义分割的模型。而这一问题的成功的关键在于如何构建图像标签同像素点之间的关联,从而自动生成图像像素级的标注,进而利用FCN训练语义分割模型。

- 目前我们注意到研究人员们提出了一些自上而下的attention方法。这类方法可以利用训练好的分类CNN模型自动获得同图像标签最相关的区域。如图2所示,我们给出了通过CAM方法获取的attention map。可以看出对于一个图像分类模型,往往物体的某个区域或某个instance对分类结果的贡献较大。因此这类attention方法只能找到同标签对应的某个物体最具判别力的区域而不是物体的整个局域。如何利用分类网络定位物体的整个区域,对语义分割任务具有重要意义。
动机

- 图3给出了我们的motivation。我们将第一张图片以及它对应的标签“person”输入到网络中进行训练。继而,网络会尝试从图中发现一些证据来证明图中包含了“person”。一般来讲,人的head是最具判别力的部位,可以使此图被正确地判别为“person”。若将head从图片中移除(如第二张图中的橙色区域),网络会继续寻找其它证据来使得图像可以被正确分类,进而找到人的body区域。重复此操作,人的foot区域也可以被发现。由于训练本身是为了从图片中发现对应标签的证据而擦除操作则是为了掩盖证据,因此我们称这种训练-擦除-再训练-再擦除的方式为对抗擦除(adversarial erasing)。
贡献
- 我们提出了一种新的AE方法,有效地使图像分类网络适应不断挖掘和扩展目标对象区域,并最终生成可用于训练分割模型的连续对象分割掩模。
- 我们提出了一种在线PSL方法,利用图像级别分类置信度来减少监督掩码内的噪声,并实现与AE协作的分段网络的更好训练。
- Our work achieves the mIoU 55.0% and 55.7% on val and test of the PASCAL VOC segmentation benchmark respectively, which are the new state-of-the-arts
方法
1. AE算法
-
AE核心思想: AE方法可以被视为建立一系列竞争者,试图挑战分类网络以发现特定类别的一些证据,直到没有可支持的证据。
-
基于上述的motivation,我们采用了对抗擦除的机制挖掘物体的相关区域。如图4所示,我们首先利用原始图像训练一个分类网络,并利用自上而下的attention方法(CAM)来定位图像中最具判别力的物体区域。进而,我们将挖掘出的区域从原始图片中擦除,并将擦除后的图像训练另一个分类网络来定位其它的物体区域。我们重复此过程,直到网络在被擦除的训练图像上不能很好地收敛。最后将被擦除的区域合并起来作为挖掘出的物体区域。

-
AE算法

- mask思路,

- mask图示
2. PSL
- 结构

- 提出的PSL构建了一个框架,其中包括两个分支,一个用于分类,另一个用于语义分割。
框架
-
图5为对抗擦除方法的细节。我们基于VGG16训练图像的分类网络,将最后两个全连接层替换为卷积层,CAM被用来定位标签相关区域。在生成的location map(H)中,属于前20%最大值的像素点被擦除。我们具体的擦除方式是将对应的像素点的值设置为所有训练集图片的像素的平均值。

-
我们发现在实施第四次擦除后,网络训练收敛后的loss值会有较大提升(图6右)。主要原因在于大部分图片中的物体的区域已经被擦除,这种情况下大量的背景区域也有可能被引入。因此我们只合并了前三次擦除的区域作为图片中的物体区域。图6左给出部分训练图像在不同训练阶段挖掘出的物体区域,以及最后将擦除区域合并后的输出。
对抗擦除在弱监督语义分割中的应用
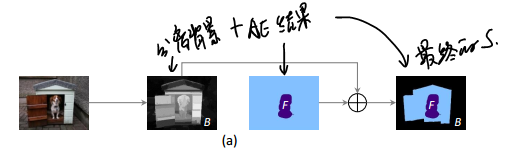
- 我们利用显著性检测技术生成的显著图生获取图像的背景信息,并同通过对抗擦除获得物体区域结合生成用于训练语义分割网络的segmentation mask(其中蓝色区域表示未指派语义标签的像素,这些像素点不参与训练)。由于在生成的segmentation mask中包含了一些噪声区域和未被标注的区域,为了更加有效地训练,我们提出了一种PSL(Prohibitive Segmentation Learning)方法训练语义分割网络,如图7。该方法引入了一个多标签分类的分支用于在线预测图像包含各个类别的概率值,这些概率被用来调整语义分割分支中每个像素属于各个类别的概率,并在线生成额外的segmentation mask作为监督信息。由于图像级的多标签分类往往具有较高的准确性,PSL方法可以利用分类信息来抑制分割图中的true negative区域。随着训练的进行,网络的语义分割能力也会越来越强,继而在线生成的segmentation mask的质量也会提升,从而提供更加准确的监督信息。
颜水成和冯佳时团队一作详解CVPR录用论文:基于对抗擦除的物体区域挖掘
实验结果
- 本文提出的对抗擦除和PSL方法,在Pascal VOC 2012数据集上获得了目前最好的分割结果。部分测试图片上也达到了令人满意的分割结果。


在这里插入图片描述