CVPR-2016
文章目录
1 Background and Motivation
motivation
- 目标检测的 ConvNet training procedure still includes many heuristics and hyperparameters that are costly to tune
- detection datasets contain an overwhelming number of easy examples and a small number of hard examples. Automatic 选择那些 hard examples 训练会 more effective and efficient.
1.1 Imbalance
Object detectors are often trained through a reduction that converts object detection into an image classification problem.
这样会带来新的问题,正负样本不均衡,RCNN 和 SS 虽然缓解了这个问题,但是正负样本 ratio still high(70:1)
This challenge opens space for learning techniques that cope with imbalance imbalance and yield faster training, higher accuracy, or both.
1.2 Booststraping
但这不时一个新的挑战,标准的解决方法 originally called bootstrapping (and now often called hard negative mining)
那么
首先介绍Bootstraping,它是一种有放回的抽样方法(可能抽到重复的样本),是用小样本来估计大样本的统计方法。举个栗子来说明好了:
你要统计你们小区里男女比例,可是你全部知道整个小区的人分别是男还是女很麻烦对吧。于是你搬了个板凳坐在小区门口,花了十五分钟去数,准备了200张小纸条,有一个男的走过去,你就拿出一个小纸条写上“M”,有一个女的过去你就写一个“S”。最后你回家以后把200张纸条放在茶几上,随机拿出其中的100张,看看几个M,几个S,你一定觉得这并不能代表整个小区对不对。
然后你把这些放回到200张纸条里,再随即抽100张,再做一次统计。
…………
如此反复10次或者更多次,大约就能代表你们整个小区的男女比例了。
你还是觉得不准?没办法,就是因为不能知道准确的样本,所以拿Bootstrap来做模拟而已。
应用过来就是
model→hard examples(eg: false positive )→bootstrapping from hard examples→model 迭代下去
- for some period of time a fixed model is used to find new examples to add to the active training set
- then, for some period of time the model is trained on the fixed active training set
1.3 Related works
- Hard example mining
- optimizing SVM
- non-SVM,shallow neural network and boosted decision tree(GBDT)
- ConvNet-based object detection
- overfeat
- RCNN 系列
- SPP-Net
- MR-CNN
- Hard example selection in deep learning
2 Innovation
propose a novel bootstrapping technique called online hard example mining,选择 hard examples RoI 进行训练,more effective and efficient
##3 Advantages
相比于baseline training algorithm
-
不需要 heuristics and hyper-parameters
-
mAP 提升
- 78.9% on PASCAL VOC 2007
- 76.3% on PASCAL VOC 2012
-
数据集越大提升越明显
- Its effectiveness increases as datasets become larger and more difficult,比如从 PASCAL VOC to COCO
4 Overview Fast RCNN
4.1 why choosing Fast RCNN(FRCN)
- broadly application
- 可以 end-to-end 的训练,不像SPP-Net那样
- 没用SVM
4.2 Traing
each mini-batch N images,每张 images B/N 个 RoIs,N=2,B=128
- Foreground RoIs
- IoU at least 0.5 (FRCN)
- Background RoIs
- [0.1,0.5)(FRCN)
- remove the 0.1 threshold(作者) ,因为作者觉得 it ignores some infrequent, but important, difficult background regions.
- Balancing fg-bg RoIs
- 正负样本 1:3,保证 25% 正样本,removing the ratio or increasing it,drop ~3 point mAP(FRCN)
- removing the ratio with no ill effect(作者)
5 Methods
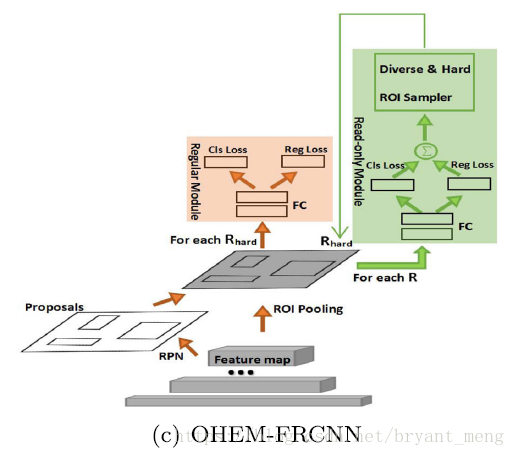
5.1 Online hard example mining
1)流程
- all RoI,instead of a sampled mini-batch,to do forward pass(区别于1:3)
- sort by loss
- choose B/N worst eaxmples(loss 越大越差)for backpropagation
2)面临问题,overlapping RoIs(overlapping 较大时) can project onto the same region in the conv feature map, because of resolution disparity(感觉 RoI align 应该可以缓解这种问题)。这样会导致 loss double counting.
3)解决方法。NMS,thresold 设置为0.7
而且用 OHEM 不用设置 mini-batch 的 fg 与 bg 的ratio,因为,If any class were neglected, its loss would increase until it has a high probability of being sampled.
如果忽略了某类,该类score会很低,前向传播 loss很高,被sampled的概率会大
4)OHEM:
- 如果 fg 比较简单(canonical view of car),mini-batch 大多是 bg
- 如果 bg 比较简单 (sky,grass),mini-batch 大多是 fg
5.2 Implementation details
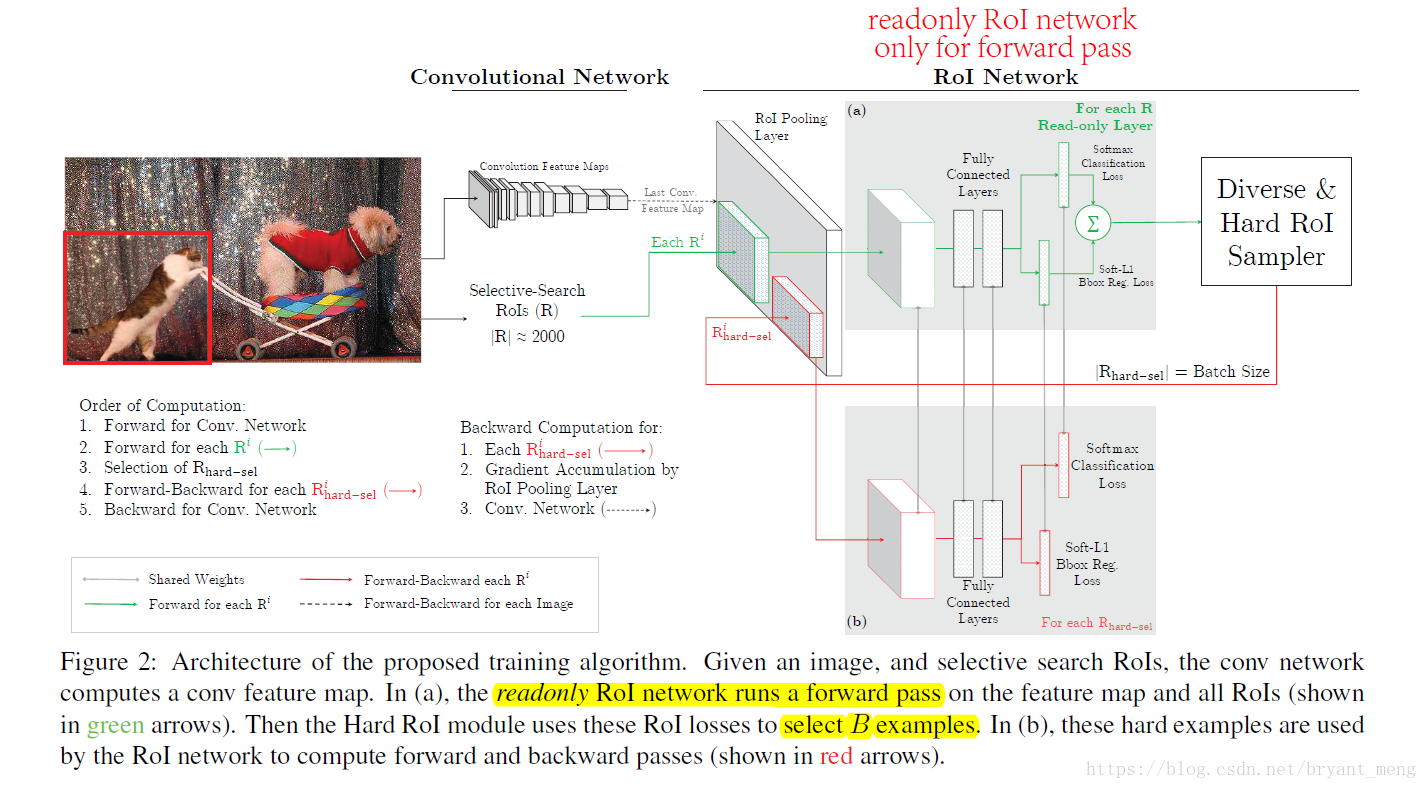
实际训练的时候,每个mini-batch包含N个图像,共|R|个ROI,也就是每张图像包含|R|/N个ROI。经过hard ROI sampler筛选后得到B个hard example。作者在文中采用N=2,|R|≈4000,B=128。
另外关于正负样本的选择:当一个ROI和一个ground truth的IOU大于0.5,则为正样本;当一个ROI和所有ground truth的IOU的最大值小于0.5时为负样本1。
6 Analyzing online hard example mining
- model
- VGG_CNN_M_1024
- VGG_16
- data
- PASCAL VOC 2007
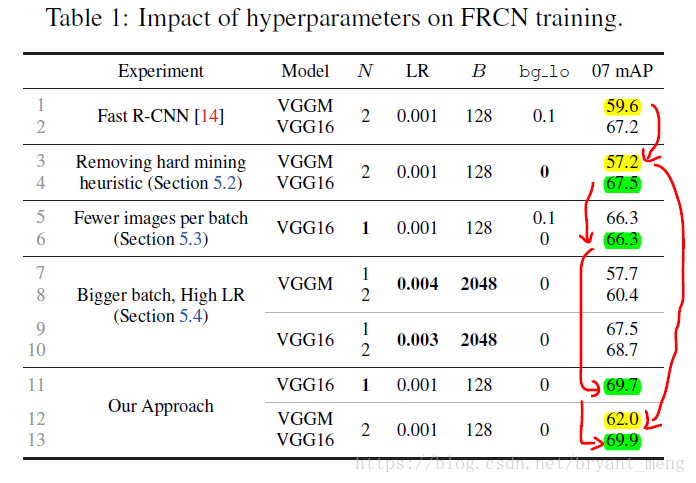
每个mini-batch包含N个图像,共|R|个ROI,也就是每张图像包含|R|/N个ROI。经过hard ROI sampler筛选后得到B个hard example。作者在文中采用N=2,|R|≈4000,B=128。
1)Experimental setup(baseline)
- line 1-2:baseline
2)OHEM vs. heuristic sampling(negative threslod 0 vs 0.1)
- line 1,3,12 可以看出,bg_lo 设置改为0 ,sub-optimality of these heuristics(FRCN) and the effectiveness of our hard mining approach
3)Robust gradient estimates(减小N)
-
N = 2 会有一个问题,it may cause unstable gradients and slow convergence because RoIs from an image may be highly correlated(如果同一个mini-batch中特征比较相似,是很不利于网络的学习的),OHEM这种机制 more highly correlated,作者用 N=1 对比了一下
-
line 4,6,11,FRCN,N=2 比N=1,好,但是OHEM + N=1 很好。This shows that OHEM is robust in case one needs fewer images per batch in order to reduce GPU memory usage.
4)Why just hard examples, when you can use all?(增大B,相应的 LR会提高,learning rate)
- line 7-10,(The easy examples will have low loss, and won’t contribute much to the gradient; training will automatically focus on the hard examples.)因为 RoI 很大,则需要更大的 learning rate,虽然效果比 baseline 高了一个点,但是相比于作者的方法,还是作者的方法效果好,而且作者的方法快一些(Moreover, because we compute gradients with a smaller mini-batch size training is faster)
5)Better optimization(看table1 的 loss)
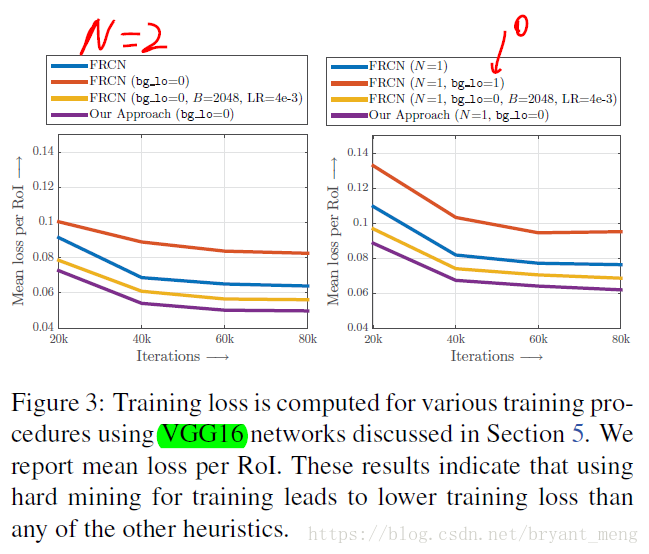
右图红线处感觉写错了,应该 bg_io = 0
原版 FRCN (bg_io = 0.1) 比 bg_io = 0 损失小,B = 2048(选择的hard example 的数量) 比 B = 128 损失小,B = 128 + OHEM 损失最小
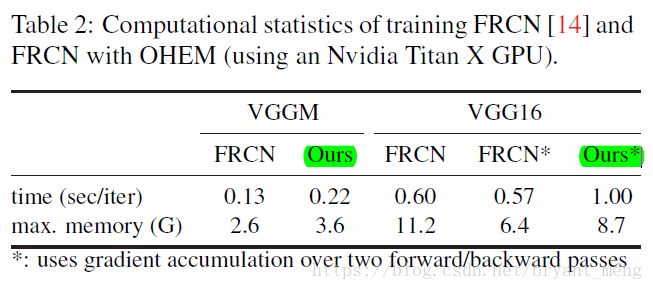
6)Computational cost
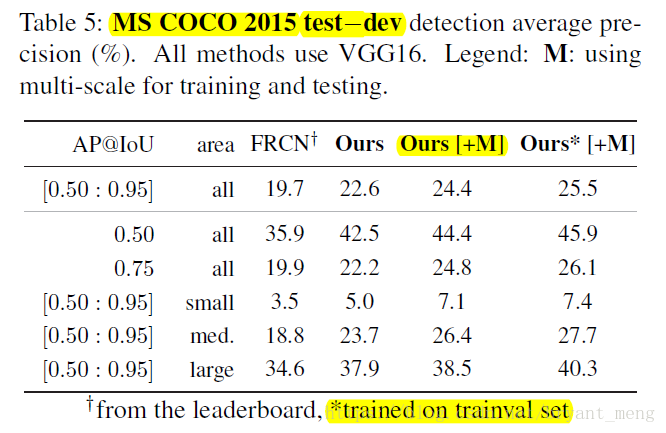
7 PASCAL VOC and MS COCO results
7.1 PASCAL VOC
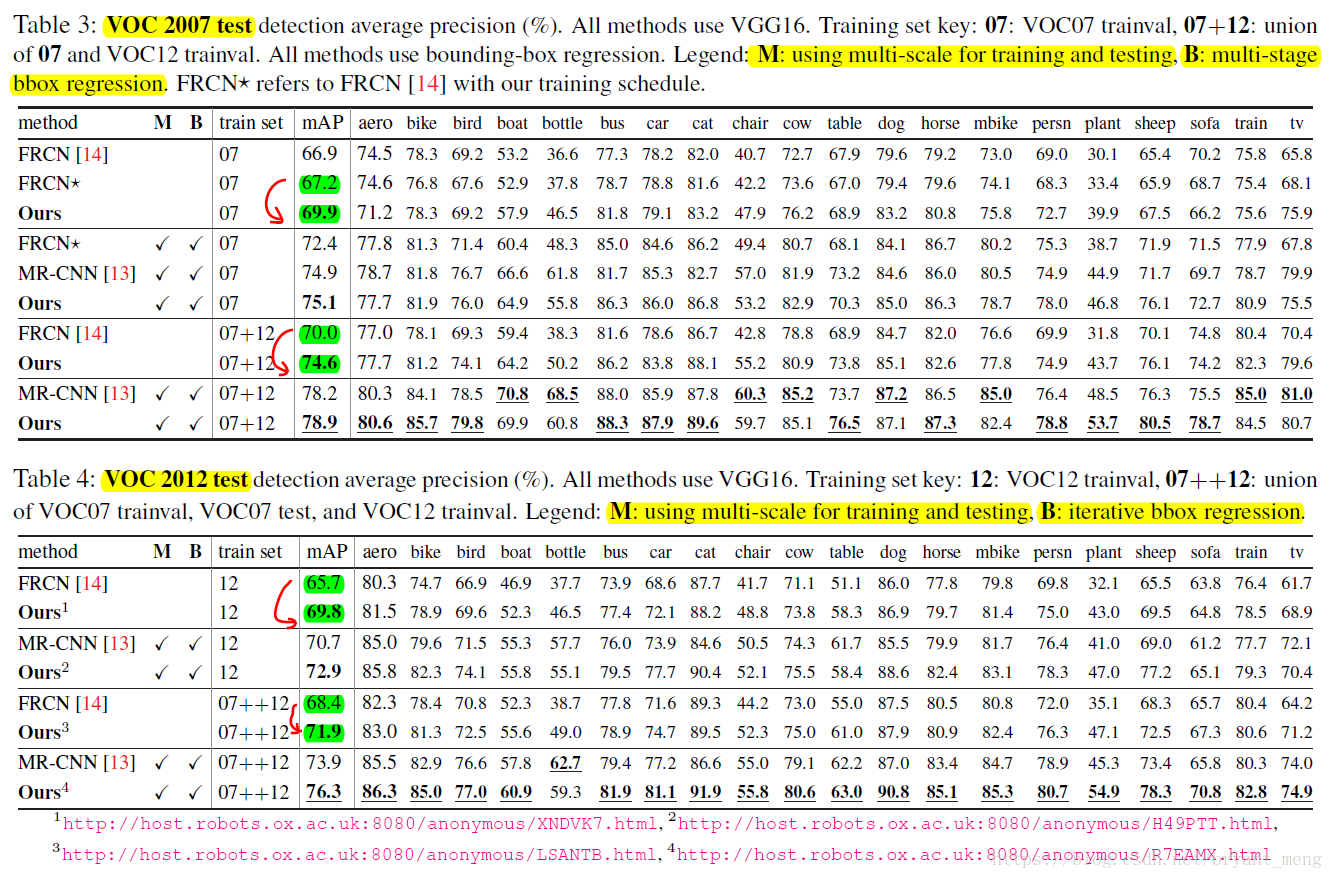
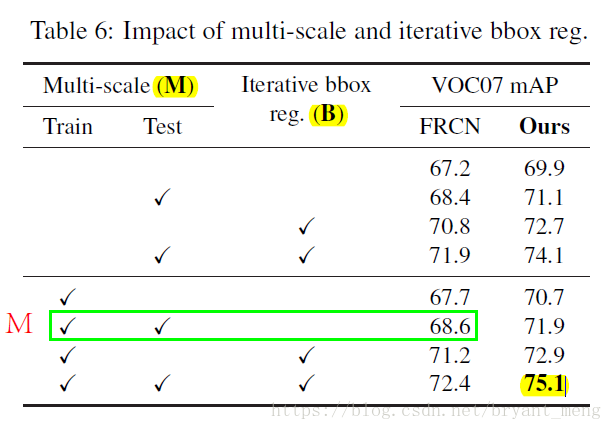
- Multi-scale (M):
train
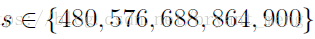
test
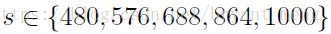
- Iterative bounding-box regression (B)
可以参考3

- 使用CNN来训练regressor(在RCNN中是使用简单的函数来训练regressor的),具体来说跟Fast RCNN比较像啦,输出是4xC个值,其中C是类别个数,不过这里直接用L2 loss拟合完事。
- 迭代优化,跟DeepFace比较像,也就是,利用分类器打一个分,然后筛掉低分的,对于剩下的高分的proposal重新回归位置,之后根据这个重新回归的位置再利用分类器打个分,然后再回归一次位置。
- 投票机制,上述两步会在每个object附近都产生不少bbox,这里利用上附近的bbox进行投票打分,具体来说,取一个最高分的bbox,然后还有它附近跟他overlap超过0.5的bbox,然后最后的bbox位置是他们的加权平均(权值为overlap)。