降维
实际工作中我们的特征数比较大时,那么模型训练的时候比较耗资源和时间,一般都需要考虑降低维度
通常一般的做法是,
1 根据特征的方差,如果特征的方差比较小或者几乎为0时,那么可以考虑将该特征删掉
2 根据特征之间的相关性,如果某个特征和另一个特征几乎成正相关或者负相关的话,那么可以将其中某一个特征删除,这样,其实删除后的信息
并不会丢失,因为根据其中保留的特征可以推出另一个删除的特征
其实降低维度,是尽量让降低维度后,信息不会丢失很多,第1种情况其实根本不会丢失信息,因为方差几乎等于0的情况,相当于该特征的值相当于是个常数,那么这列常数值需要的时候再写出来即可
还有一种方法是PCA,它和上面不同的是它可能不是单单删除其中的某个特征,它是将原有的n个维度,降到k个维度(注意,这k个维度的每个维度可能在原来n个维度中有,也可能没有,不一定,最后你就知道答案)同时,降到k个维度后,又能使得损失的信息最小
在说到PCA之前,我们先来说另外一个最基本的概念,
向量或者点在不同坐标系下的表示
对于二维坐标系下点(3,2)
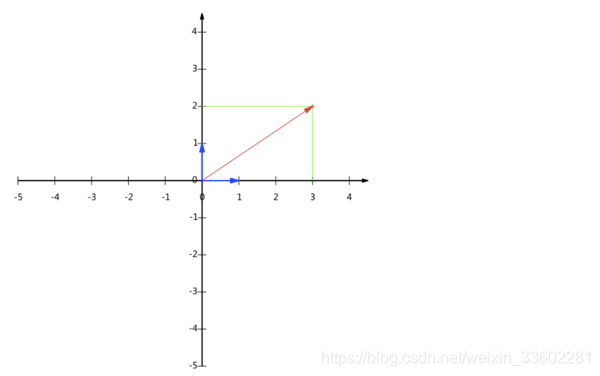

其实所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基
(3,2)这是在由(1,0),(0,1)构成的一组基中的表示,但其实任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。
那么假如在其它两个向量构成的基中,点(3,2)对应的坐标是多少呢?
例如下面:
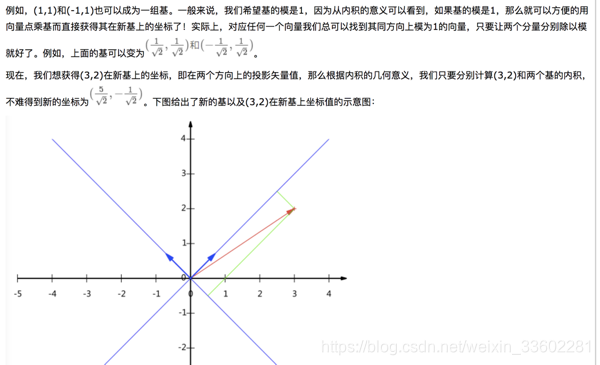
另外这里要注意的是,我们列举的例子中基是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
那么点(3,2)对应(1,1)和(-1,1)组成的一组基中的坐标怎么来的呢,其实很简单
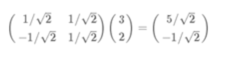
其实就是把基组成的行矩阵 乘以 点对应的列矩阵,相乘得到
注意:
1 上面的每个基都是单位化的,我们通常说的基都是单位向量
2 上面的基要写成行向量形式,点要写成列的形式 (PCA降维就是这样,m,n转过来乘)
3 上面的每一行基向量,对应二维中的一个维的单位向量,也对应二维中的一个维度或者一个轴(就好比原来的基(1,0)对应二维中x轴),假如上面只是一个行的基向量乘以右边点的列向量,比如假如上面只是
(1/sqrt(2),1/sqrt(2))* (3,2)T,那么你乘下就知道,它的结果就是一个数,那么这个数是什么意思呢,它表示的其实就是(3,2)这个点在1/sqrt(2),1/sqrt(2)这个单位向量对应维度或者对应轴上的投影值,这个投影值也就是(3,2)这个点在这个维度或轴的值,就好比如果是原来(1,0)(0,1)为基,如果只是(1,0)乘以(3,2)T的话,那么结果就是3,表示(3,2)这个点在(1,0)这个单位向量对应的轴或者维度上的值是3,关于这个的证明可以看博客
由第三点可以得出:
如果用一个行基向量乘,得到的是一个数,它是一维,
而上面是用两个行基向量乘,得到的是一个点,它是二维,
那么不是相当于我用一个行向量乘不就是降维了吗,原来是二维,现在降到了一维,那么PCA里面也是这个原理,假如现在有个样本点(x1,x2,……xn),它是n个特征,在原来的n维空间这个点这样表示,它的一组正交基就是(1,0,0……,0),(0,1,0……,0)….,假如我先在还是在n维空间,我换了一组正交基假如就是s1,s2……sn,那么在新的一组基下,原来点的表示就是s1,s2……sn组成的行向量 乘以(x1,x2,……xn)T,和上面(3,2)那个例子其实一样的,然后我把它降到k维其实就是在s1,s2……sn选择k个行向量乘以(x1,x2,……xn)T了,最终(x1,x2,……xn)变成的维度只会有k个了,这就是它的降维,它的本质是这样,实际还有一些其它的处理
降维的本质
上面我们可以知道,假如我有k个基,我用某个点比如(3,2)去乘以其中的一个基,那么得到的是一个数值,表示的是该点在该基对应的轴的值或者投影,就比如(1,0),(0,1)作为基,(1,0) * (3,2)T = 3,就是x的值,
那么假如我有k个基,我选择其中m个基去乘以p(p最开始是k维),那么最终得到了m个基上的投影或者值,也就是降到了m维
降维之后干什么?
由上面我们知道,对于一个k维的点p(x1,x2,…xk),给他乘以一个m个正交基,那么可以给它降到m维p1(x1,x2,xm)
p(x1,x2,…xk) ->p1(x1,x2,xm),我希望维度降到m维后,它能够损失的信息尽可能的小,也就是用降维后的p1几乎能代替p,那么该怎么做呢?
因此引入了方差

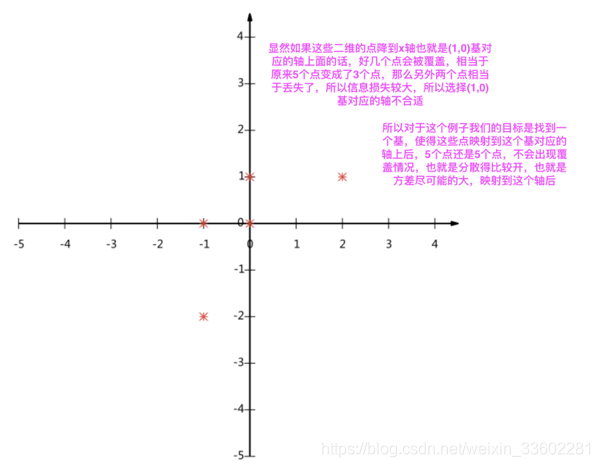
现在问题来了:如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
以上图为例,可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠。所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述这个问题。

注意:上面的每行元素都被减去了均值,所以它一行加起来为0,所以均值为0,这样方便后面计算
我们的目标不仅仅是降到K维后,这k个维度的方差尽可能的大,而且也要保证这k个维度之间没有相关性,或者相关性尽可能的小,所以又引入了它们之间的协方差

对于原来的样本X,我们既能表示方差,也能表示协方差的矩阵引入:

所以这个矩阵就能表示我们的目的,方差和协方差,我们希望的是它们相关性尽可能的小,也就是每个协方差都为0,所以他是个对角矩阵,方差尽可能的大,就是第一个最大,第二个次大。。。。
C = 1/m X X T 针对的是原来样本X而言,即没有降维的X而言,它希望表达的矩阵
现在我们就要来降维了,降维的本质是什么对于X,
Y = P * X
P和上面例子一样,是M个正交基的行向量组成的矩阵,,X就是原始样本点,维度为n
那么和上面一样P * X就表示X这个样本点在新的由M个正交基构成的坐标系中的表示,这个还不是降维,为什么,因为M可能等于n,这个只是将X转换为在M个正交基构成的空间中的显示,那么降维表示什么,比如降到k维,它表示从M个正交基中抽取k个正交基构成的行向量乘以 X 如下
Y1 = P1 * X,P1为k个正交基构成的行向量,那么此时X就由n维降到了k维,并且这k维是由这k个正交基构成的空间里面的维度,Y1就是这k个正交基构成的空间对于X的表示
所以这里的降维分为两部,先将X转换到另一组正交基构成的空间去显示,然后从另一个空间抽取它的k个维度来表示
而对于PCA,我们抽取的k个维度,方差尽可能的大,k个维度之间的相关性尽可能的小
所以先将X转换到另一个空间去表示,
Y = P * X
我们希望表示转换后各个维度的方差,以及维度之间的协方差,所以有1/m Y Y T


这个式子其实就是一个矩阵对角化,D是对角矩阵,并且对角线上的元素都是C的特征值,P是C的特征向量,因为C是一个对称矩阵,所以P一定是正交的,其实P就是我们要找的空间中的那组正交基,然后从P中抽取k个方差最大的正交基,其实也就是特征值从大到小前面的k个特征值对应的特征向量,因为是正交的,所以对应我们要找的k个正交基


所以到了这里,求P其实就是求我们矩阵C的特征值和特征向量,因为C是对称的,所以它的特征向量肯定是正交的,又因为它的特征向量又是单位化的,所以它的特征向量P相当于一组正交基,然后我们将特征值从大到小(其实对应的就是方差从大到小的维度)排列,抽取前K个特征值对应的k个特征向量(k个正交基,对应方差前k大的k个维度)P1,P1就是我们要找的矩阵或者说是要找的空间中的k个正交基构成的矩阵,然后P1 * X就表示原来样本X在新的k个正交基构成的空间的表示,也就是降维后的表示,所以真正降维就是P1 * X,将原来X的n维降到了k维,同时这k个维度的方差又是前k大的,所以降到k维后它的信息丢失很少,并且这k个维度之间的相关性也为0
注意:
这k维和原来的n维没有什么关系,或者不一定有什么关系,我们的k个正交基是从P矩阵中拿的,P矩阵中有n个正交基,最终的P矩阵的正交基都是按照特征值从大到小排列的,而这里特征值又对应方差,所以这m个正交基对应的方差是从大到小排列的,前k个正交基对应前k个方差,那么第一个正交基对应方差最大的那个维度或者轴,第二个正交基代表方差次大的那个轴,。。。
而在我们的原始样本X对应的坐标系中,,方差最大那个不一定是x轴或者y轴或者原始坐标系的任何一个轴,意思就是原始坐标系的一组基和新得到的k个正交基中它们不一定有重合的,比如k个之中方差最大的那个基不一定在原始坐标系的一组基中找得到
这也就是降的k维和原始的n个维度没有必然的关系
所以我用一句话总结对样本X降维本质就是:
Y = P1 * X
P1 是能将X映射到空间中方差前k大的k个维度,对应的正交基构成的矩阵(每个正交基对应一个行向量),这里面的X是一个列向量
相当于将X转换到(或者映射到)由这k个正交基构成的空间中去显示
P矩阵中正交基的个数等于原来的样本的维数n,P1只不过是从中选取k个方差最大的(特征值最大)的正交基,构成P1矩阵


