分类
TP:正例预测正确的个数
FP:负例预测错误的个数
TN:负例预测正确的个数
FN:正例预测错误的个数
准确率(accuracy)
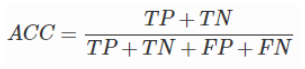
精确率(precision) 描述的是在所有预测出来的正例中有多少是真的正例
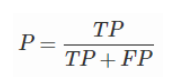
准确率与精确率的区别:
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc 也有 99% 以上,没有意义。
召回率(recall) ,描述的是所有正例我能发现多少
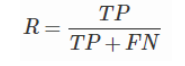
F1值——精确率和召回率的调和均值
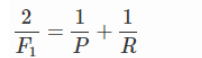
只有当精确率和召回率都很高时,F1值才会高
ROC曲线与AUC值
参考:http://www.cnblogs.com/maybe2030/p/5375175.html#_label3
TPR = TP / (TP + FN) 描述的是所有正例我能发现多少,即召回率
FPR = FP / (FP + TN) 描述的是所有负例中我预测错误的比例
ROC曲线由两个变量FPR和TPR所得。
如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。
这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。

左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病。上图中一个阈值,得到一个点。ROC越往上,分类器效果越好。我们用一个标量值AUC来量化它。
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器。0.5 < AUC < 1,优于随机猜测。AUC = 0.5,跟随机猜测一样。AUC < 0.5,比随机猜测还差。
AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
回归
训练误差和测试误差
损失函数