一直以为自己理解这些概念,但是其实只是听说过而已。这些概念的释义来自于周志华教授的《机器学习》,都属于对机器学习算法的性能度量。
一、错误率与精度
还是使用书上的定义写的明确,test set中所有样本预测对和预测错所占的比例就是这两个指标,求和为1。但是其实这里表述并不是很好,这里的“精度”更好的表示是“准确度”(Accuracy),这两个指标只是在“对”与“错”层面进行分析,并未涉及出错原因。

二、查准率&查全率&PR曲线&F1
首先要介绍混淆矩阵,注意这个仅仅适用于二分类问题,碰到其他问题可以进行拓展。这个的确比较“混淆”人,符号标记很乱,中文翻译也很拗口。首字母表示了预测的结果这件事的正确与否:是True还是False。后面字母表示了预测的结果。这四个位置的数值加起来等于样本的总数。

接下来定义Precision和Recall,P的分母是分类器给出的正例集合;R的分母是数据集中所有的正例集合。两个率分别反应模型查的准不准,和,查的全不全。um这个感觉也有点难记,可以这样记召回率:因为有FN全负面信息,所以要“召回”。
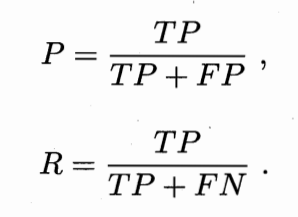
实际模型对每个样本的预测结果都是0-1之间连续的,因此调整这个阈值就可以获得每个样本变动后对应的混淆矩阵(可以视为考察阈值对模型分辨结果的影响)。此时对应的多个P-R点可以进行绘制成为PR曲线,类似下图这样。曲线下部所围成的面积越大代表模型性能越好。也可以使用平衡点来度量学习器的好坏,在平和点处P=R。

F1参数本质是对两个率进行调和平均运算,更加关注较小值对最终结果的影响。

三、受试者工作特性 ROC
这个名字是真的拗口:Receiver Operating Characteristic,是从军事和医学中引申过来的。思想和P-R曲线很类似,使用阈值对连续预测结果进行分类,以此获取模型性能曲线。ROC曲线的纵轴和横轴比较奇葩,需要特殊记忆。

纵轴 TPR本质上就是召回率Recall,分类器将dataset中所有正例检测出来了多少,越高越好;横轴FPR在考察dataset中所有负例检测错了多少,约小越好。所以一个优质的模型的ROC特性应当向左上方突出。AUC是Area Under ROC Curve的缩写,是ROC曲线围成的面积,越大越好。

