一、什么是词向量
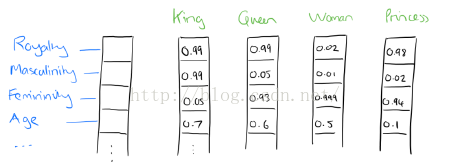
词向量最初是用one-hot represention表征的,也就是向量中每一个元素都关联着词库中的一个单词,指定词的向量表示为:其在向量中对应的元素设置为1,其他的元素设置为0。采用这种表示无法对词向量做比较,后来就出现了分布式表征。
在word2vec中就是采用分布式表征,在向量维数比较大的情况下,每一个词都可以用元素的分布式权重来表示,因此,向量的每一维都表示一个特征向量,作用于所有的单词,而不是简单的元素和值之间的一一映射。这种方式抽象的表示了一个词的“意义”。
二、词向量推理
实际上,被学习的词向量表示是用一种非常简单的方式捕捉有意义的语法和语义规律。具体来说,对于一个特定关系的词组,语法规律可以看作固定的向量偏移。
三、学习词向量
word2vec的两种形式:CBOW和Skip-gram模型
(1)CBOW
CBOW去除了上下文各词的词序信息,使用上下文各词的平均值。
例如一段散文“The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precises syntatic and semantic word relationships.”,想象这段文字上有一个滑动窗口,包括当前的词和前后的四个词。具体如下图:

上下文词组成了输入层,每一个词都用one-hot形式来表示,如果词汇量是V,则每个词就表示成V维向量,相应的词对应元素被设置成1,其余的为0。下图表示一个单隐层和一个输出层。
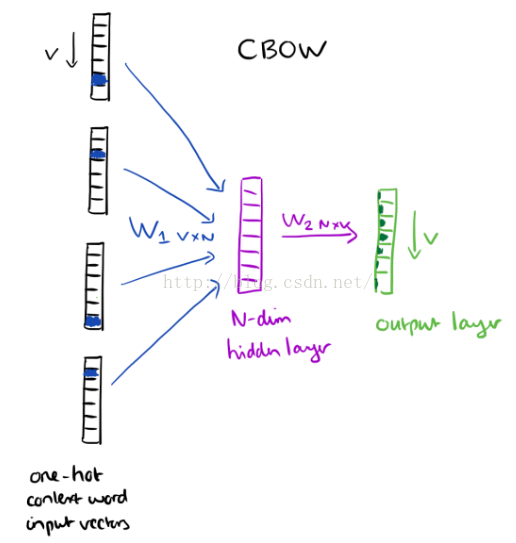
训练的目标是最大限度的观察实际输出词(焦点词)在给定输入上下文且考虑权重的条件概率,在我们的例子中,给出了输入(“一个”,“有效”,“方法”,“为”,“高”,“质量”,“分布式”,“向量”),我们要最大限度的获得“学习”作为输出的概率。
由于我们的输入向量是用one-hot来表示的,与权重矩阵W1相乘就相当于简单的选择W1中的一行。
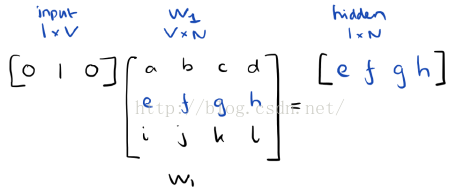
如果输入了C个词向量,隐层的激活函数其实就是用来统计矩阵中的热点行,然后除以C来取平均值。这意味着,隐含层单元的激活函数就是简单的线性运算(直接将权重和作为下一层的输入)。
从 隐层到输出层,我们用一个权重矩阵W2来为每一个词计算词汇表中的得分,然后使用softmax来计算词的后验分布。
(2)skip-gram
skip-gram和CBOW正好相反,它使用单一的焦点词作为输入,经过训练然后输出它的目标上下文,如下图所示:
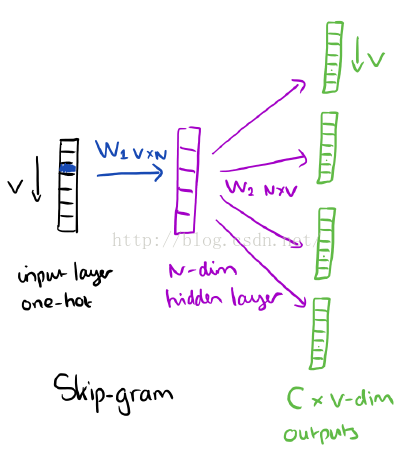
正如之前提到的,隐层的激活函数只是权重矩阵W1对应行的简单统计。在输出层,我们输出C个词向量。训练的最终目标就是减少输出层所有上下文词的预测错误率。例如,如果输入“learn”,我们可能在输出层得到“an”,“efficient”,“method”,“for”,“high”,“quality”,“distributed”,“vector”。
四、优化
在一个训练实例中,为每一个词输出词向量代价是非常大的,所以我们提供了两种优雅的方法,一个是基于层级的softmax函数,另一个是负采样。
(1)层级softmax函数
层级softmax函数是用一个二叉树来表示词汇表中的所有单词,树中的每个叶子节点表示一个单词,对于每一个叶子,都存在唯一的从根到叶节点的路径,这条路径是用来估计被叶节点所表示的单词的概率,这个概率定义为从根节点随机游走到该叶节点的概率。
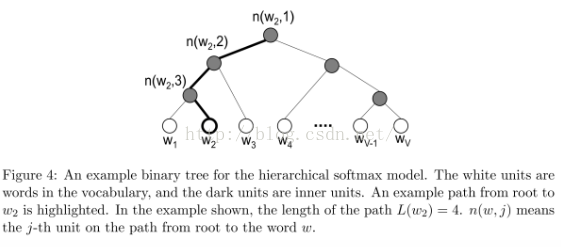
这样的好处是不用对V个节点一一评估来获得神经网络中的概率分布,而是只用评估log2(V)个节点。在这里,我们使用二叉哈夫曼树,因为它给高频词汇赋予更短的编码,这样训练过程就变快了。
(2)负采样
负采样就是每一次迭代,我们只更新输出词的一个样本。目标输出词应该被留在样本中且被更新,我们还要加入一些(非目标)词作为负样本,Milokov等人也用一个简单的二次采样方法来抑制训练集中稀疏词和高频词之间的不平衡性(例如,“in”,“the”,“a”比稀疏词提供更少的信息),具体而言,如果词wi 在语料中的出现频率f(wi) 大于阈值t,则有P(wi) 的概率在训练时跳过这个词。训练集中每一个词都有一个丢弃概率P(wi).
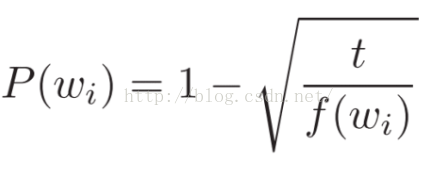
f(wi)是词wi的频率,t是一个选择的阈值,一般值在10**-5附近。
详细内容请参考:The amazing power of word vectors
python中gensim库word2vec的使用:
pip install gensim安装好库后,即可导入使用:
1、训练模型定义
- from gensim.models import word2vec
- sentences=word2vec.Text8Corpus('data.txt')
- model = word2vec.Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4)
或者:
model = gensim.models.Word2Vec() # an empty model, no training model.build_vocab(some_sentences) # can be a non-repeatable, 1-pass generator model.train(other_sentences) # can be a non-repeatable, 1-pass generator
参数解释:
1.sg=1是skip-gram算法,对低频词敏感;默认sg=0为CBOW算法。
2.size是输出词向量的维数,值太小会导致词映射因为冲突而影响结果,值太大则会耗内存并使算法计算变慢,一般值取为100到200之间。
3.window是句子中当前词与目标词之间的最大距离,3表示在目标词前看3-b个词,后面看b个词(b在0-3之间随机)。
4.min_count是对词进行过滤,频率小于min-count的单词则会被忽视,默认值为5。
5.negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值为1e-3。
6.hs=1表示层级softmax将会被使用,默认hs=0且negative不为0,则负采样将会被选择使用。
7.workers控制训练的并行,此参数只有在安装了Cpython后才有效,否则只能使用单核。
详细参数说明可查看word2vec源代码。
2、训练后的模型保存与加载
- model.save(fname)
- model = Word2Vec.load(fname)
3、模型使用(词语相似度计算等)
- model.most_similar(positive=['woman', 'king'], negative=['man'])
- #输出[('queen', 0.50882536), ...]
- model.doesnt_match("breakfast cereal dinner lunch".split())
- #输出'cereal'
- model.similarity('woman', 'man')
- #输出0.73723527
- model['computer'] # raw numpy vector of a word
- #输出array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
其它内容不再赘述,详细请参考gensim的word2vec的官方说明,里面讲的很详细。