词---------------->向量
将之前稀疏表示的词转为向量表示,使用1层隐藏层。这个比图像识别抽象太多了,看了好久,理论就不介绍了,太多。训练了100万次之后,skip-gram模式的128维向量拍扁,效果还是不错的,相关性高的单词基本都聚在一起了。
本篇代码:https://github.com/joliph/tensorflow/blob/master/Word2Vec.py
tensortflow学习系列代码仓库:https://github.com/joliph/tensorflow
import collections
import math
import os
import random
import zipfile
import urllib
import numpy as np
import tensorflow as tf
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
url = 'http://mattmahoney.net/dc/'
data_index = 0
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window,valid_size,replace=False)
num_sampled = 64
num_steps = 1000001
'''
下载的回调函数,用以显示下载进度
'''
def how_many_download(a, b, c):
per = 100.0 * a * b / c
if per > 100:
per = 100
print("%.2f%%" % per)
'''
下载数据包函数
'''
def maybe_download(filename, expected_bytes):
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename, how_many_download)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print("Found and verified", filename)
else:
print(statinfo.st_size)
raise Exception('Failed to verify' + filename + '. Can you get to it with a browser?')
return filename
'''
将数据包解压并将其中的单词添加进list中返回
'''
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
'''
返回 data count dictionary reversed_dictionary
data:将原文中的单词全部转换为序号,unkown统一为0
count:频率前5000的单词和他们的出现次数列表
dictionary:频率前5000的单词和他们的序号字典
reversed_dictionary:key和value反转的dictionary
'''
def build_dataset(words, vocabulary_size):
count = [['Unknow', 0]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, num in count:
dictionary[word] = len(dictionary)
data = list()
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
count[0][1] += 1
data.append(index)
reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reversed_dictionary
'''
batch: 目标单词组成的列表,列表有batch_size个目标单词
labels:目标单词的预测词列表
'''
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer=collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index+1)%len(data)
for i in range(batch_size // num_skips):
target = skip_window
targets_to_avoid = [skip_window]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0,span-1)
targets_to_avoid.append(target)
batch[i*num_skips+j] = buffer[skip_window]
labels[i*num_skips+j,0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index+1)%len(data)
return batch,labels
'''
画图
'''
def plot_with_labels(low_dim_embs,labels,filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels),"More labels than embeddings"
plt.figure(figsize=(18,18))
for i,label in enumerate(labels):
x,y=low_dim_embs[i,:]
plt.scatter(x,y)
plt.annotate(label,xy=(x,y),xytext=(5,2),textcoords='offset points',ha='right',va='bottom')
plt.savefig(filename)
plt.show()
'''
主函数
'''
if __name__ == "__main__":
filename = maybe_download('text8.zip', 31344016)
words = read_data(filename)
vocabulary_size = 50000
data, count, dictionary, reversed_dictionary = build_dataset(words, vocabulary_size)
print("Intialized dictionary")
del words
batch,labels = generate_batch(batch_size = 8,num_skips = 2,skip_window = 1)
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32,shape=[batch_size])
train_labels = tf.placeholder(tf.int32,shape=[batch_size,1])
valid_dataset = tf.constant(valid_examples,dtype=tf.int32)
with tf.device('/gpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size,embedding_size],-1.0,1.0))
embed=tf.nn.embedding_lookup(embeddings,train_inputs)
nce_weights=tf.Variable(tf.truncated_normal([vocabulary_size,embedding_size],stddev=1.0/math.sqrt(embedding_size)))
nce_biases=tf.Variable(tf.zeros([vocabulary_size]))
loss=tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
optimizer=tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
normalized_embeddings=embeddings / norm
valid_embeddings=tf.nn.embedding_lookup(normalized_embeddings,valid_dataset)
similarity=tf.matmul(valid_embeddings,normalized_embeddings,transpose_b=True) #similarity [16,50000]
init=tf.global_variables_initializer()
with tf.Session(graph=graph) as session:
init.run()
print("Intialized variables")
average_loss=0
for step in range(num_steps):
batch_inputs,batch_labels=generate_batch(batch_size,num_skips,skip_window)
feed_dict={train_inputs:batch_inputs,train_labels:batch_labels}
_,loss_val=session.run([optimizer,loss],feed_dict=feed_dict)
average_loss+=loss_val
if step % 2000 == 0:
average_loss /= 2000
print("Average loss at step ",step,": ",average_loss)
average_loss = 0
if step % 100000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word=reversed_dictionary[valid_examples[i]]
top_k=8
nearest=(-sim[i,:]).argsort()[1:top_k+1]
log_str="Nearest to %s:" % valid_word
for k in range(top_k):
close_word=reversed_dictionary[nearest[k]]
log_str="%s %s,"%(log_str,close_word)
print(log_str)
final_embeddings=normalized_embeddings.eval()
tsne=TSNE(perplexity=30,n_components=2,init='pca',n_iter=5000)
plot_only=100
low_dim_embs=tsne.fit_transform(final_embeddings[:plot_only,:])
labels=[reversed_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs,labels)训练过程
Average loss at step 2000 : 113.33981186771393
Average loss at step 200000 : 4.373704571485519
Average loss at step 400000 : 4.315581535935402
Average loss at step 600000 : 4.2478054294586185
Average loss at step 800000 : 4.107968866527081
Average loss at step 1000000 : 3.9973099328875543最后一次输出:
Nearest to this: which, it, instead, rajonas, rajons, what, another, hyi,
Nearest to one: rajonas, hyi, landesverband, michelob, rajons, dicrostonyx, stadtbahn, two,
Nearest to five: four, seven, eight, six, three, nine, zero, rajonas,
Nearest to with: hyi, neutronic, involving, between, eml, landesverband, rajons, gora,
Nearest to his: her, their, your, my, its, our, whose, stadtbahn,
Nearest to when: if, before, although, where, while, after, though, until,
Nearest to states: kingdom, nations, state, provinces, us, countries, rajons, netbios,
Nearest to american: canadian, australian, british, english, austrian, russian, italian, dutch,
Nearest to zero: five, seven, eight, four, six, nine, agave, dicrostonyx,
Nearest to used: designed, intended, presented, referred, seen, applied, defined, found,
Nearest to may: might, can, could, must, should, will, would, cannot,
Nearest to who: actually, whom, which, often, she, never, already, he,
Nearest to three: four, five, six, eight, seven, two, rajonas, landesverband,
Nearest to also: still, actually, now, never, often, which, below, typically,
Nearest to has: had, have, is, requires, was, having, contains, spawned,
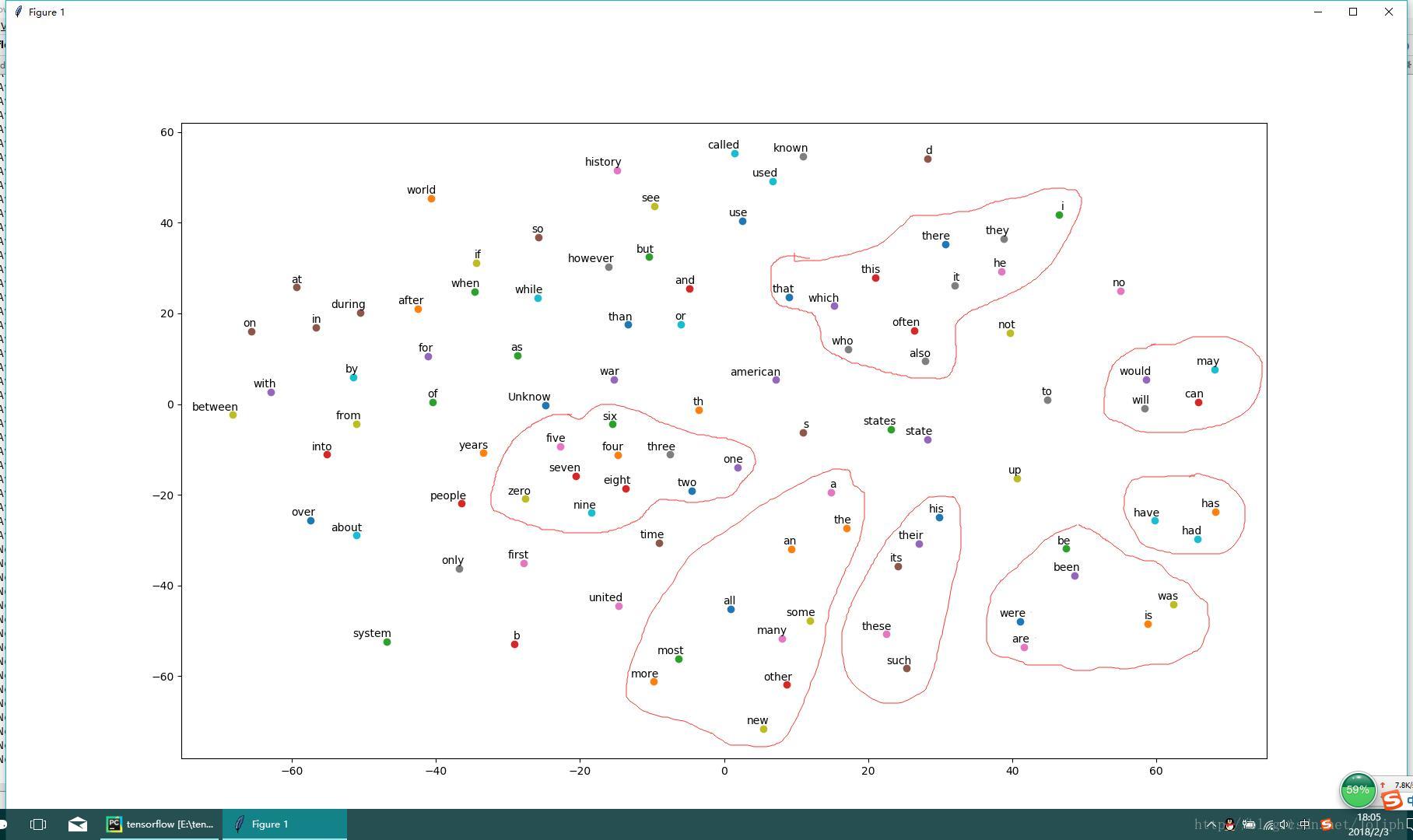
Nearest to more: less, most, very, quite, fairly, rather, extremely, greater,从图中看到基本一类的信息在空间上聚在了一起….不太清楚和聚类的关系不过从结构上看是用一层隐藏层实现的,难啊
完善
原本的
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
normalized_embeddings=embeddings / norm
valid_embeddings=tf.nn.embedding_lookup(normalized_embeddings,valid_dataset)
similarity=tf.matmul(valid_embeddings,normalized_embeddings,transpose_b=True)修改为
norm=tf.sqrt(tf.reduce_sum(tf.square(embeddings),1,keep_dims=True))
transpose_normalized_embeddings=normalized_embeddings=embeddings / norm
valid_embeddings=tf.nn.embedding_lookup(normalized_embeddings,valid_dataset)
similarity=tf.matmul(valid_embeddings,tf.transpose(transpose_normalized_embeddings))这个地方的矩阵形式一直搞得我搞不太懂源码,原来是transpose_b=True让权值矩阵自动转置了,所以这个地方的matmul目的就是从稠密的词向量还原为onehot编码的原本的向量,方式是乘词向量的转置矩阵。