在上一博客中,我们已经学会了如何使用Python3爬虫抓取文字,那么在本问中,将通过实例来教大家如何使用Python3爬虫批量抓取图片。
(1)实战背景
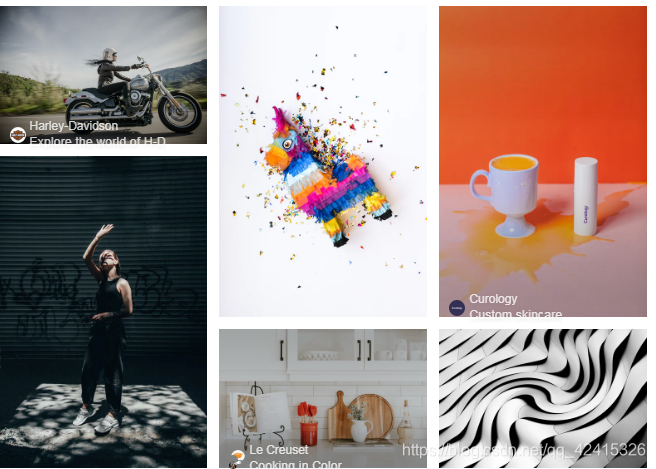
上图的网站的名字叫做Unsplash,免费高清壁纸分享网是一个坚持每天分享高清的摄影图片的站点,每天更新一张高质量的图片素材,全是生活中的景象作品,清新的生活气息图片可以作为桌面壁纸也可以应用于各种需要的环境。
看到这么优美的图片,是不是很想下载做壁纸呢。每张图片我都很喜欢,批量下载吧,不多爬,就下载50张好了。
2)实战进阶
<a>标签存放超链接,图片存放在<img>标签中!既然这样,我们截取就Unsplash网站中的一个<img>标签,分析一下:
<img alt="Snow-capped mountain slopes under blue sky" src="https://images.unsplash.com/photo-1428509774491-cfac96e12253?dpr=1&可以看到,<img>标签有很多属性,有alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。
所以爬取过程为:
- 使用requeusts获取整个网页的HTML信息;
- 使用xpath解析HTML信息,找到所有<img>标签,提取src属性,获取图片存放地址;
- 根据图片存放地址,下载图片。
按这个思路爬取Unsplash试一试,编写代码如下:
import requests
if __name__ == '__main__':
url = 'https://unsplash.com/'
req = requests.get(url)
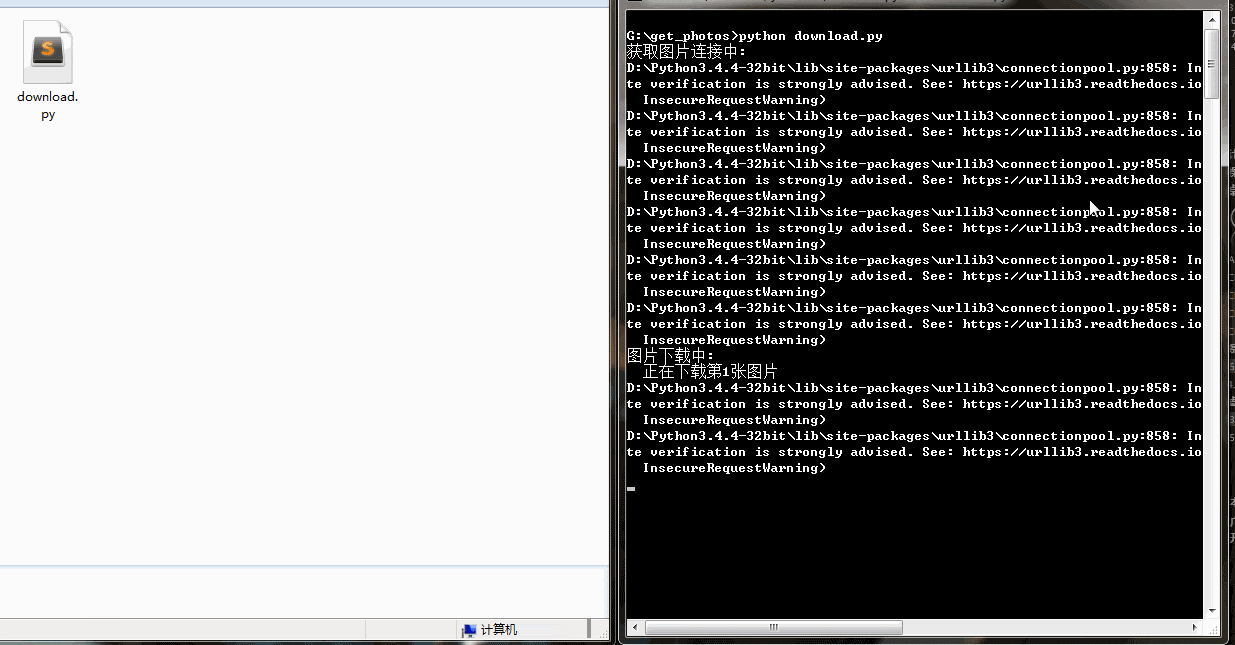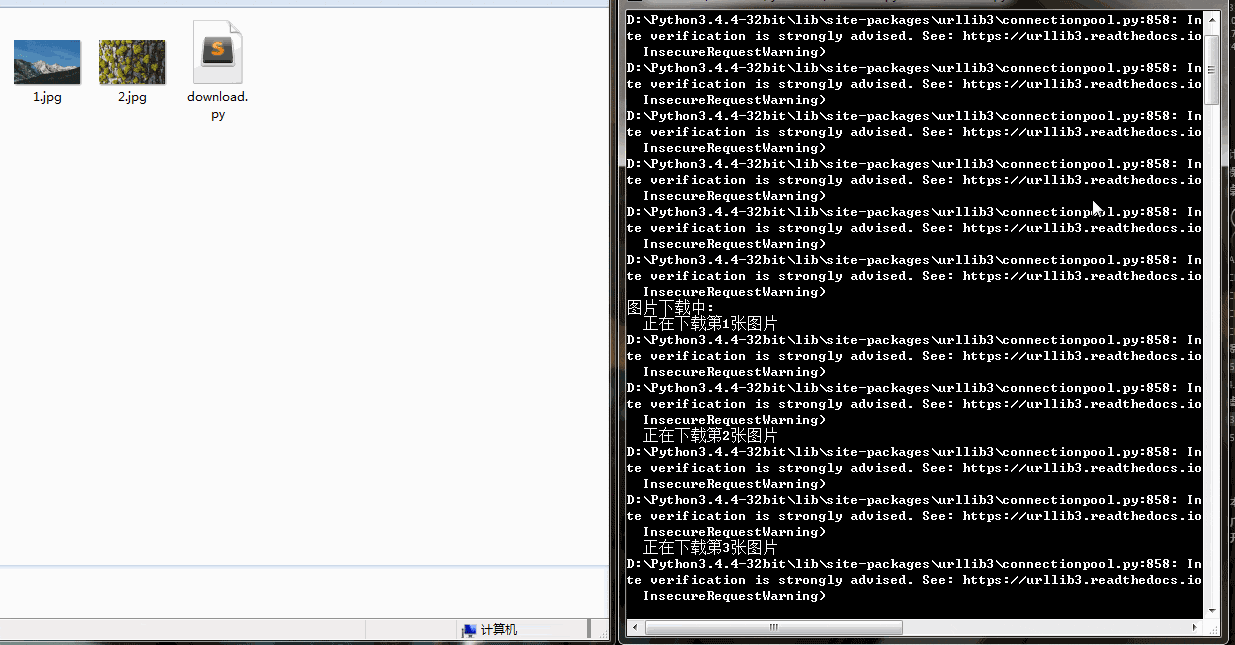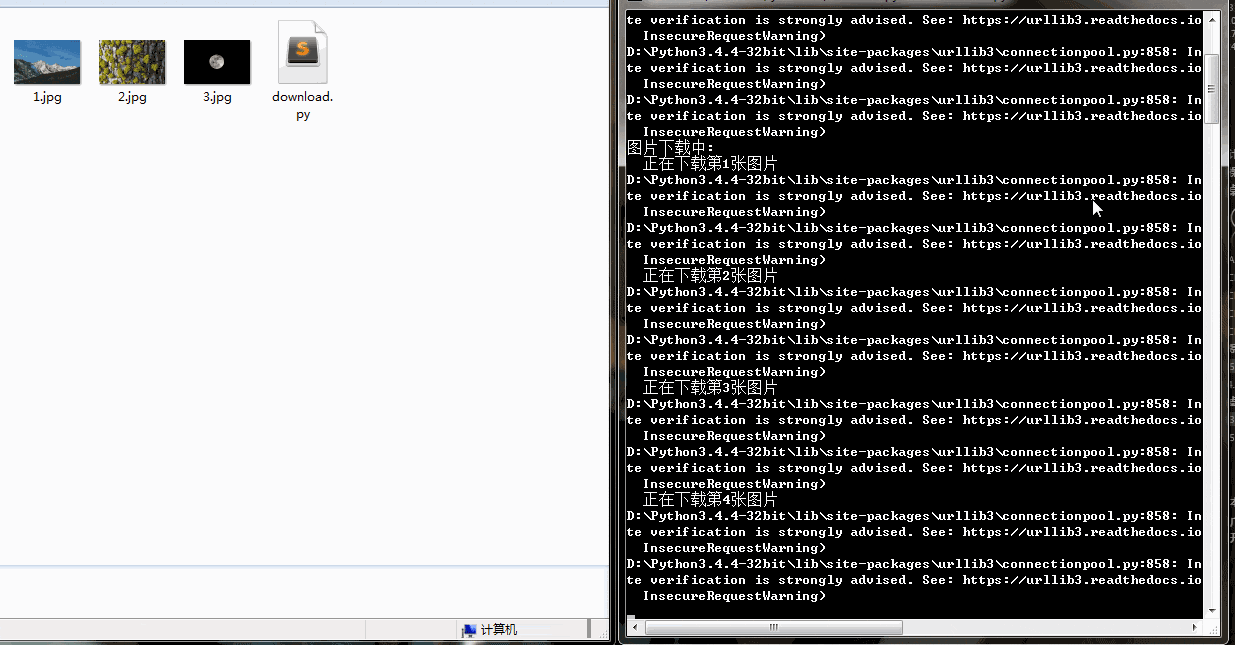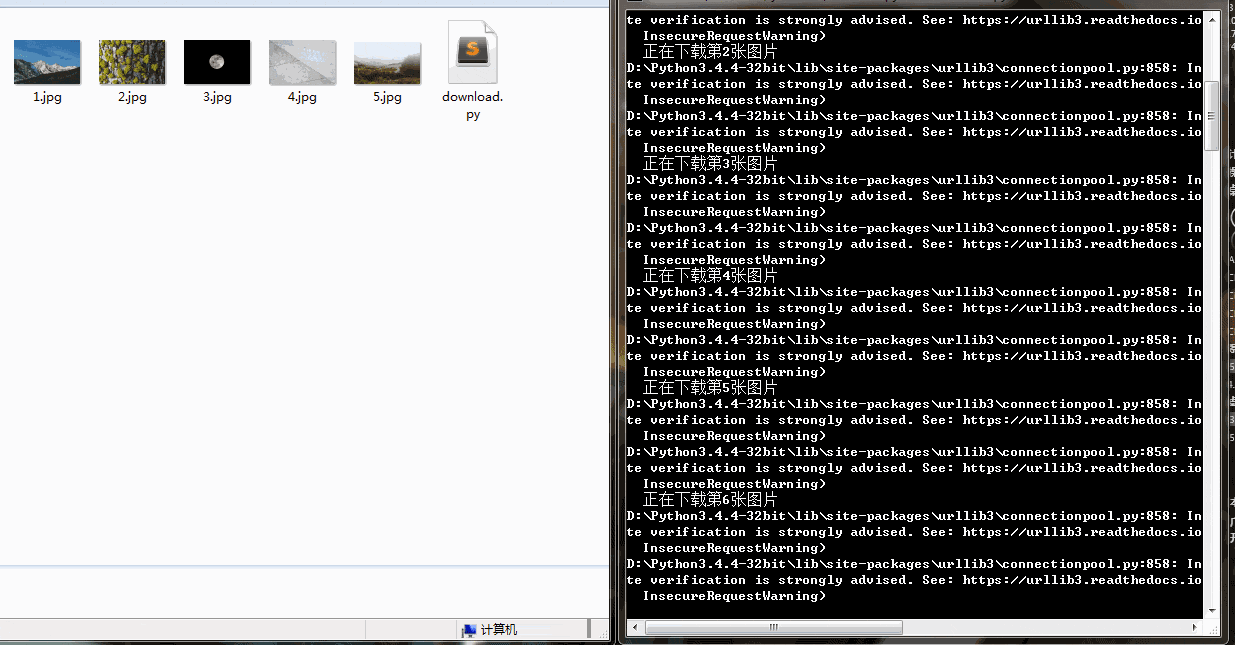
print(req.text)按照我们的设想,我们应该能找到很多<img>标签。但是我们发现,除了一些<script>标签和一些看不懂的代码之外,我们一无所获,一个<img>标签都没有!
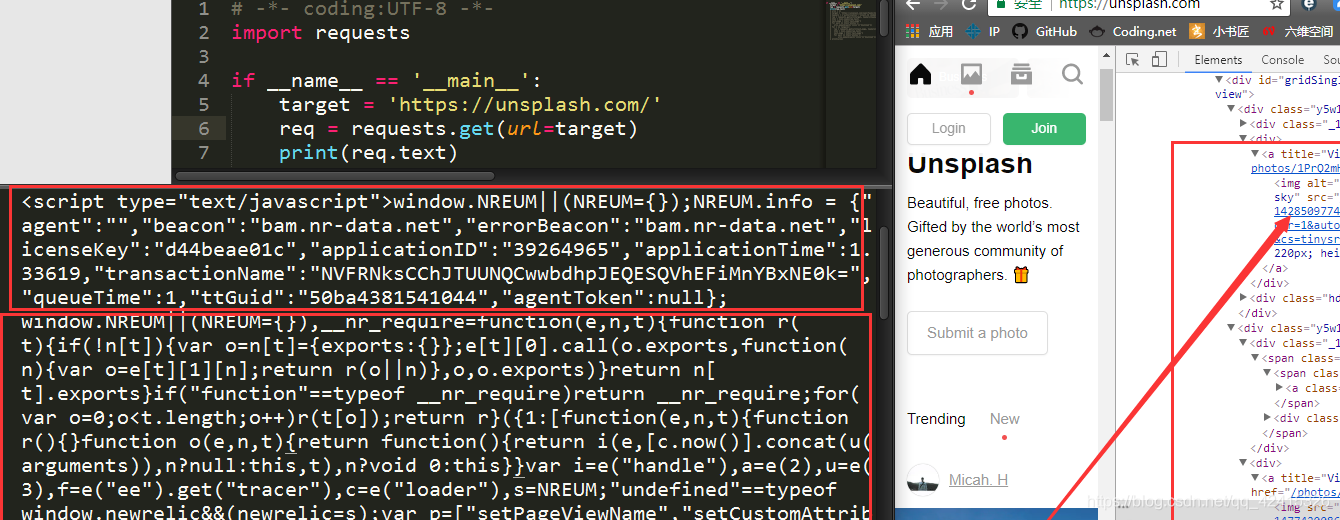
因为这个网站的所有图片都是动态加载的!网站有静态网站和动态网站之分,上一个实战爬取的网站是静态网站,而这个网站是动态网站,动态加载有一部分的目的就是为了反爬虫。
可以使用浏览器自带的Networks,它自然会帮我们分析JavaScript脚本执行的内容。
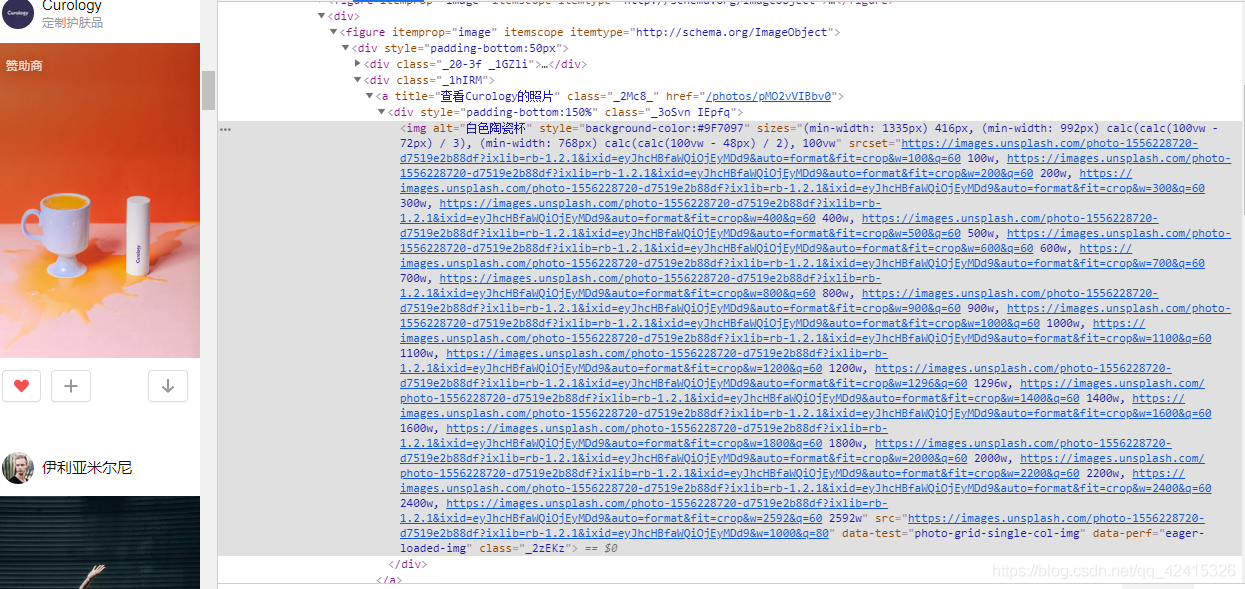
然而事实并没有这么简单,仔细看看,我们会发现,网页源码中只有为数不多的几个img标签,也就是说,我们只能获取到几张图片的路径,我们要的可是大量的图片,接下来将页面下滑,会发现img标签多了起来,很显然这是一个Ajax[1]动态加载的网站
3)完整代码如下:
'''
精美图片下载
'''
import requests
import json
import time
import random
from contextlib import closing
class Imgdownloader(object):
#初始化
def __init__(self):
self.headers= {
'Referer': 'https://unsplash.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36',
}
self.base_url = 'https://unsplash.com/napi/photos'
self.img_urls = []
self.page = 0
self.per_page =12
def get_img_urls(self):
'''获取图片链接地址
'''
for i in range(self.per_page):
self.page = self.page+i+1
params={
"page":self.page,
"per_page":self.per_page,
}
res =requests.get(self.base_url,params = params)
#json转换为字典
res_dict = json.loads(res.text)
for item in res_dict:
url = item['urls']['regular']
self.img_urls.append(url)
#每次获取一页链接,随机休眠
time.sleep(random.random())
print("图片urls获取成功")
def img_download(self,urls):
'''
下载图片到本地存储
'''
num = 0
for url in urls:
num = num + 1
res = requests.get(url,headers =self.headers)
img_path = str(num) +".jpg"
with closing(requests.get(url,headers =self.headers,stream = True)) as res:
with open(img_path,'wb') as f:
print("正在下载第{}张照片".format(num))
for chunk in res.iter_content(chunk_size = 1024):
f.write(chunk)
print("{}.jpg 下载成功".format(num))
if __name__ == '__main__':
#图片下载对象
imgdl = Imgdownloader()
print("获取图片链接中...")
#对象获取图片链接
imgdl.get_img_urls()
print("开始下载图片:")
#下载图片
imgdl.img_download(imgdl.img_urls)
print('所有图片下载完成')下载速度还行,有的图片下载慢是因为图片太大