文章目录
今天使用Python爬取网络上的歌词,将其解析后下载下来,最后制作GUI实现交互。
一.准备工作
1.1Python开发环境
笔者用的是Python3.8,至于开发环境如何配置,本文不进行赘述,可以参考这篇博文。
1.2Python开发工具
笔者用的是PyCharm2018.2.2,年代有些久远。PyCharm的安装可以参考这篇博文。
二.思路
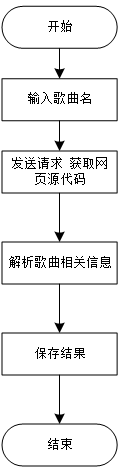
1.爬虫整体思路
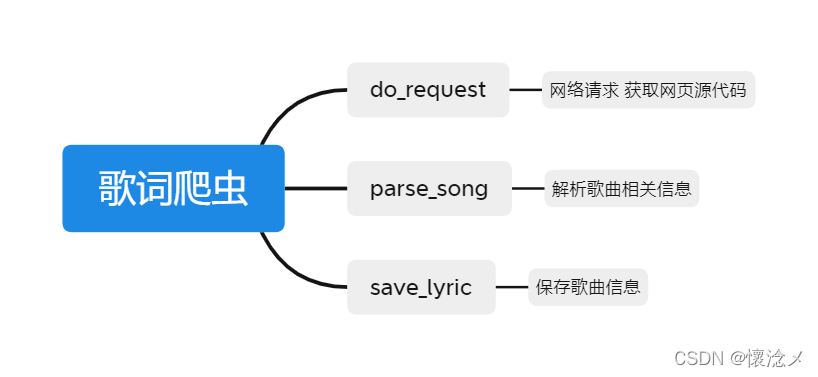
2.爬虫代码思路
三.网页分析
3.1数据确定
在网络上输入歌曲名+“歌词”,会出现此歌曲对应的相关信息。
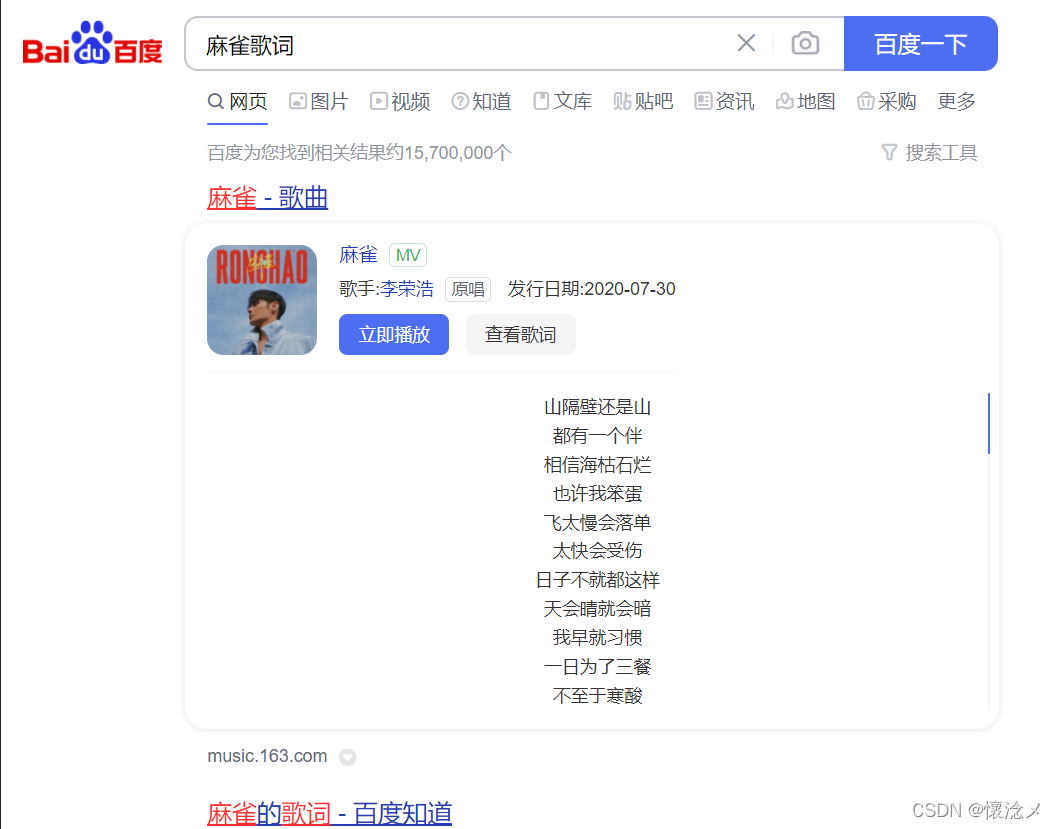
中间的一部分:歌名、歌手、发行日期、歌词是我们需要的。
3.2网页数据加载方式分析
此步骤用于确定网页的数据加载方式。
复制一句歌词放在网页源代码中进行检索,发现有多个内容重合,其中包括带时间的歌词以及不带时间的分词。
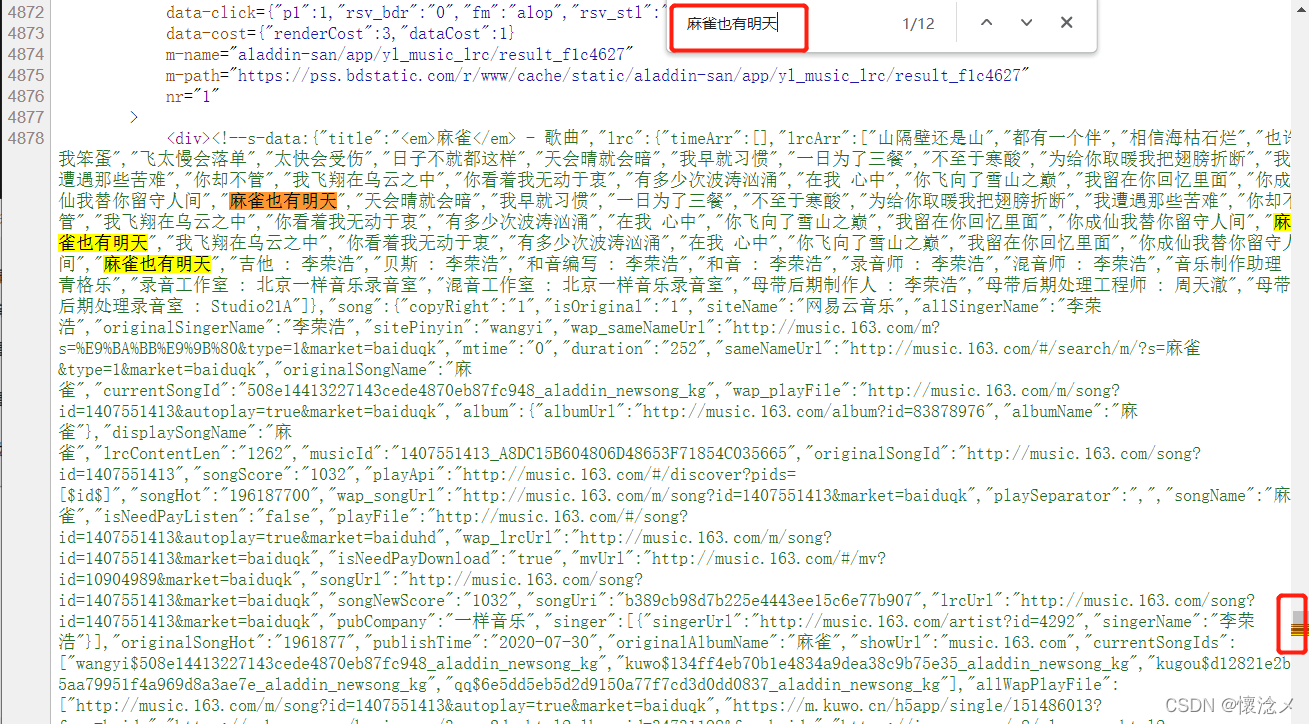
可以基本确定此网页为静态网页,并且只要能得到网页源代码即可解析出歌曲相关信息。
3.3确定数据所在位置
F12打开开发者工具,ctrl+shift+c选取歌名所在元素
3.3.1歌名
发现歌名在class="re-box_3gPX1"的div标签下的class="song-name_fpAiu"的p标签下a标签的文本中。

所以xpath可以这样写:
//div[@class="re-box_3gPX1"]//p[@class="song-name_fpAiu"]/a/text()
3.3.2歌手
歌手名在class="right-row_1kMnT"的div标签下的span标签下的a标签的文本中

所以xpath可以这样写:
//div[@class="right-row_1kMnT"]/span/a/text()
3.3.3发行时间
发行时间在class="re-box_3gPX1"的div标签下class="c-gap-left"的span标签下的文本中,提取出来的文本需要进行字符串切割,使用英文的冒号:切割即可

所以xpath可以这样写:
//div[@class="re-box_3gPX1"]//span[@class="c-gap-left"]/text()
3.3.4歌词
歌词在class="lrc-scroll_3lNbR"的div标签下的p标签的文本中

所以xpath可以这样写:
//div[@class="lrc-scroll_3lNbR"]/p/text()
四.源代码
1.lyric_spider.py
# coing:utf-8
import os
import requests
from lxml import etree
'''
'''
class LyricSpider(object):
def __init__(self, key_word):
self.keyword = key_word
self.base_url = "https://www.baidu.com/s?ie=UTF-8&wd={}"
def do_request(self, url):
"""
发送网络请求,获取网页源代码
:param url:
:return:
"""
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'sec-ch-ua': '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
r.encoding = "utf-8"
html = r.text
return html
else:
return False
except:
return False
def parse_song(self, html):
"""
解析网页源码,得到歌曲名称、歌手、发布时间、歌词,放入字典中
:param html:
:return:
"""
item = {
}
res = etree.HTML(html)
song_name = res.xpath('//div[@class="re-box_3gPX1"]//p[@class="song-name_fpAiu"]/a/text()')
if song_name:
item["song_name"] = song_name[0]
song_singer = res.xpath('//div[@class="right-row_1kMnT"]/span/a/text()')
if song_singer:
item['song_singer'] = ",".join(song_singer)
song_pubtime = res.xpath('//div[@class="re-box_3gPX1"]//span[@class="c-gap-left"]/text()')
if song_pubtime:
item['song_pubtime'] = song_pubtime[0].split(":")[-1]
song_lyric = res.xpath('//div[@class="lrc-scroll_3lNbR"]/p/text()')
if song_lyric:
item['song_lyric'] = '\n'.join(song_lyric)
return item
def save_lyric(self, item):
"""
将歌词保存到本地
:param item:
:return:
"""
song_full_name = item['song_name'] + "-" + item['song_singer']
song_lyric = item['song_lyric']
os.makedirs("./lyric", exist_ok=True)
with open("./lyric/" + song_full_name + ".lrc", 'w', encoding="utf-8")as f:
f.write(song_lyric)
def main(self):
full_url = self.base_url.format(self.keyword + "歌词")
html = self.do_request(full_url)
if html:
song_item = self.parse_song(html)
if song_item:
print(song_item)
self.save_lyric(song_item)
else:
print("歌词解析失败!")
else:
print("网页访问失败!")
if __name__ == '__main__':
keyword = "麻雀"
spider = LyricSpider(keyword)
spider.main()
2.Lyric_show_GUI.py
import os
from tkinter import ttk, Tk, StringVar, END
from tkinter import messagebox
import threading
import pyperclip
from tkinter import scrolledtext
from lyric_spider import LyricSpider
"""
复制,
导出txt未实现
"""
class App:
def __init__(self):
self.root=Tk()
self.root.title('歌词快速查询-v1.0')
self.root.resizable(0,0)
width=410
height=410
left=(self.root.winfo_screenwidth()-width)/2
top=(self.root.winfo_screenheight()-height)/2
self.root.geometry('%dx%d+%d+%d'%(width,height,left,top))
self.create_widet()
self.set_widget()
self.place_widget()
self.root.mainloop()
def create_widet(self):
self.l1=ttk.Label(self.root)
self.e1=ttk.Entry(self.root)
self.b1=ttk.Button(self.root)
self.lf=ttk.LabelFrame(self.root)
self.l2=ttk.Label(self.lf)
self.e2=ttk.Entry(self.lf)
self.l3=ttk.Label(self.lf)
self.e3=ttk.Entry(self.lf)
self.l4=ttk.Label(self.lf)
self.e4=ttk.Entry(self.lf)
self.l5=ttk.Label(self.lf)
self.l6=ttk.Label(self.lf)
self.l7=ttk.Label(self.lf)
self.b2=ttk.Button(self.lf)
self.b3=ttk.Button(self.lf)
self.text=scrolledtext.ScrolledText(self.lf,)
def set_widget(self):
self.e2_var=StringVar()
self.e3_var=StringVar()
self.e4_var=StringVar()
self.l1.config(text='请输入歌曲名:')
self.b1.config(text='查询')
self.b2.config(text='复制歌词')
self.b3.config(text='导出歌词')
self.lf.config(text='查询结果')
self.l2.config(text='歌名:')
self.l3.config(text='歌手:')
self.l4.config(text='发行时间:')
#将字符串变量绑定Entry组件
self.e1.config(justify='center')
self.e2.config(textvariable=self.e2_var,justify='center')
self.e3.config(textvariable=self.e3_var,justify='center')
self.e4.config(textvariable=self.e4_var,justify='center')
self.root.bind('<Escape>',self.escape)
self.root.bind('<Return>',self.do_search)
self.b1.config(command=lambda:self.thread_it(self.search_infos))
self.b2.config(command=self.do_copy_lyric)
self.b3.config(command=self.do_save_lyric)
self.text.tag_configure("centered", justify="center")
def place_widget(self):
self.l1.place(x=50,y=20)
self.e1.place(x=140,y=20)
self.b1.place(x=295,y=20,width=80,height=25)
self.lf.place(x=30,y=50,width=350,height=350)
self.l2.place(x=20,y=10)
self.e2.place(x=110,y=10)
self.l3.place(x=20,y=50)
self.e3.place(x=110,y=50)
self.l4.place(x=20,y=90)
self.e4.place(x=110,y=90)
self.l5.place(x=60,y=130)
self.l6.place(x=60,y=170)
self.l7.place(x=60,y=210)
self.b2.place(x=260,y=50,width=80,height=25)
self.b3.place(x=260,y=90,width=80,height=25)
self.text.place(x=20,y=130,width=320,height=185)
def search_infos(self):
keyword=self.e1.get()
#判断输入类型,必须为11位数字
if keyword!="":
self.text.delete(0.0, END)
self.engine = LyricSpider(keyword)
full_url=self.engine.base_url.format(keyword+"歌词")
html = self.engine.do_request(full_url)
if html:
song_item = self.engine.parse_song(html)
if song_item:
song_name=song_item.get("song_name")
song_singer=song_item.get("song_singer")
song_pubtime=song_item.get("song_pubtime")
song_lyric=song_item.get("song_lyric")
self.e2_var.set(song_name)
self.e3_var.set(song_singer)
self.e4_var.set(song_pubtime)
self.text.insert(END,song_lyric,("centered",))
# self.engine.save_lyric(song_item)
else:
messagebox.showerror('错误', '歌词解析失败!')
else:
messagebox.showerror('错误', '网页访问失败!')
else:
messagebox.showwarning('警告','输入有误,请检查!')
#使用线程防止UI界面卡死
def thread_it(self,func,*args):
t=threading.Thread(target=func,args=args)
t.setDaemon(True)
t.start()
def escape(self,event):
self.root.destroy()
def do_search(self,event):
self.thread_it(self.search_infos())
def do_copy_lyric(self):
"""
复制歌词
:return:
"""
try:
song_lyric=self.text.get(0.0,END)
pyperclip.copy(song_lyric)
messagebox.showinfo('提示', '复制成功!')
except:
messagebox.showwarning('警告', '歌词为空!')
def do_save_lyric(self):
"""
导出歌词到本地
:return:
"""
song_name=self.e2_var.get()
song_singer=self.e3_var.get()
song_lyric = self.text.get(0.0, END)
try:
os.makedirs("./lyric",exist_ok=True)
file_name=song_name+"-"+song_singer+".lrc"
with open("./lyric/"+file_name,'w',encoding="utf-8")as f:
f.write(song_lyric)
messagebox.showinfo('提示', '导出成功!')
except:
messagebox.showwarning('警告', '导出失败!')
if __name__ == '__main__':
a=App()
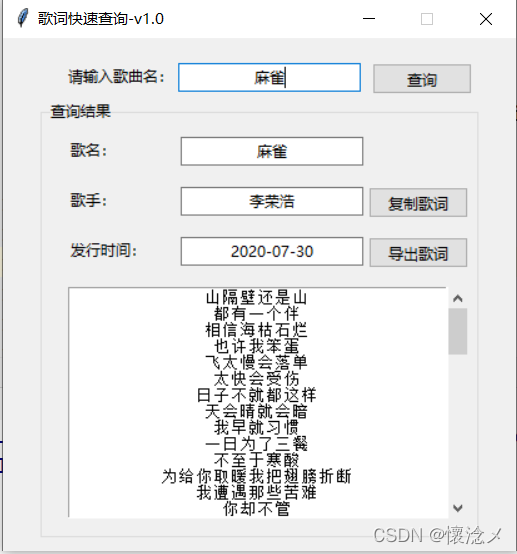
五.结果
无论是爬虫代码还是GUI程序都能准确的获取歌曲信息

六.总结
本次使用Python撰写了一个歌曲爬虫,主要进行歌词的爬取,并且使用Tkinter开发GUI图形界面,更加方便用户操作,程序打包好放在了蓝奏云。欢迎大家提出自己的看法,思路、代码方面有什么不足欢迎各位大佬指正、批评!
