K-Means算法原理

K-means的优缺点
优点:
1.算法快速、简单;
2.对大数据集有较高的效率并且是可伸缩性的;
3.时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(n×k×t) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目
缺点:
1、在k-measn算法中K是事先给定的,但是K值的选定是非常难以估计的。
2、在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
3、当数据量很大时,算法的开销是非常大的。
sklearn中的k-means
算法的目的是选择出质心,使得各个聚类内部的inertia值最小化,inertial的计算方式如下:
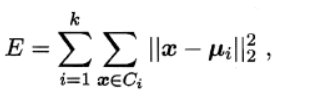
其中ui描述了每个簇的中心(即均值向量)。inertial可以被认为是类内聚合度的一种度量方式。E越小,则簇内样本相似度越高。
K-means++
从上面的分析可以看出,k-means是随机的分配k个初始聚类中心。而聚类的结果高度依赖质心的初始化。如果初始聚类中心选的不好,k-means算法最终会收敛到一个局部最优值,而不是全局最优值。为了解决这个问题,引入了k-means++算法,它的基本思想就是:==初始的聚类中心之间的相互距离要尽可能的远。==而且在计算过程中,我们通常采取的措施是进行不止一次的聚类,每次都初始化不同的中心,以inertial最小的聚类结果作为最终聚类结果。

sklearn.cluster.KMeans参数介绍
n_clusters:int型,生成的聚类数,默认为8
max_iter:int型,执行一次k-means算法所进行的最大迭代数。 默认值为300
n_init:int型,用不同的聚类中心初始化值运行算法的次数,最终解是在inertia意义下选出的最优结果。 默认值为10
init:有三个可选值:‘k-means++’、‘random’、或者传递一个ndarray向量。
1)‘k-means++’ 用一种特殊的方法选定初始质心从而能加速迭代过程的收敛
2)‘random’ 随机从训练数据中选取初始质心。
3)如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心。
默认值为‘k-means++’。
tol:float型,默认值= 1e-4 与inertia结合来确定收敛条件。
n_jobs:int型。指定计算所用的进程数。内部原理是同时进行n_init指定次数的计算。
(1)若值为 -1,则用所有的CPU进行运算。若值为1,则不进行并行运算,这样的话方便调试。
(2)若值小于-1,则用到的CPU数为(n_cpus + 1 + n_jobs)。因此如果 n_jobs值为-2,则用到的CPU数为总CPU数减1。
random_state:整形或 numpy.RandomState 类型,可选
用于初始化质心的生成器(generator)。如果值为一个整数,则确定一个seed。此参数默认值为numpy的随机数生成器。
主要属性
cluster_centers_:聚类中心
labels:每个样本所属的簇
inertial_:用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
K值的评估标准
不像监督学习的分类问题和回归问题,我们的无监督聚类没有样本输出,也就没有比较直接的聚类评估方法。但是我们可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。
1、Calinski-Harabaz Index:越大越好
在sklearn中, Calinski-Harabasz Index对应的方法是sklearn.metrics.calinski_harabaz_score。
CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
2、Silhouette Coefficient:轮廓系数(越大越好)
在sklearn中,Silhouette Coefficient对应的方法为sklearn.metrics.silhouette_score。
对于一个样本点(b - a)/max(a, b)
a平均类内距离,b样本点到与其最近的非此类的距离。
silihouette_score返回的是所有样本的该值,取值范围为[-1,1]。
KMeans算法实现
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.datasets.samples_generator import make_blobs
from sklearn import metrics
import matplotlib.pyplot as plt
x,y = make_blobs(n_samples=1000,n_features=4,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.4],random_state=10)
k_means = KMeans(n_clusters=3, random_state=10)
k_means.fit(x)
y_predict = k_means.predict(x)
plt.scatter(x[:,0],x[:,1],c=y_predict)
plt.show()
print(k_means.predict((x[:30,:])))
print(metrics.calinski_harabaz_score(x,y_predict))
print(k_means.cluster_centers_)
print(k_means.inertia_)
print(metrics.silhouette_score(x,y_predict))
[1 1 0 2 1 0 1 1 1 2 1 2 1 1 0 2 1 1 1 0 1 1 0 1 1 1 1 2 0 0]
2672.175134496046
[[-0.98579917 -1.04421422]
[ 1.4925044 1.49887711]
[-0.03211515 -0.01417351]]
415.81167375689665
0.5758167373145309
