KNN算法原理
K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴。其实K近邻并没有显式的学习过程,它的学习过程就是测试过程。
k近邻算法思想:先给你一个训练数据集D,包括每个训练样本对应的标签。然后给你一个新的测试样本T,问你测试样本的标签预测是什么,K近邻的方法就是找到T到D中每一个样本的相似度,然后根据相似度大小对D中样本排序,取前K个最相似的样本的标签的众数作为测试样本T的标签(即前K个样本投票决定)。具体相似度怎么度量,是根据测试样本到D中每个训练样本的距离度量,一般用的最多的是欧氏距离,也可以更广泛的p范数(欧氏距离是2范数)。 譬如曼哈顿距离。
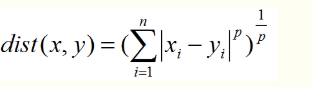
当p=1时为曼哈顿距离,p=2时为最常用的欧氏距离。
基于sklearn包的KNN算法实现
import numpy as np
from sklearn import datasets #包含很多数据集的模块
from sklearn.model_selection import train_test_spilt #将训练集和测试集分开的模块
from sklearn.neighbors import KNeighborsClassifier # K-近邻算法模块
import matplotlib.pyplot as plt
data = datasets.load_digits() #导入数字数据集
data_x = data.data #特征,size为(1797*64),即1797个样本,每个样本有64个特征
data_y = data.target #标签
#将数据集和训练集按7:3的比例分开
train_x,test_x,train_y,test_y = train_test_split(data_x,data_y,test_size=0.3)
knn = KNeighborsClassifier(n_neighbors=5) #构建k值为5的knn算法模型
knn.fit(train_x,train_y) #训练
probability = knn.predict_proba(test_x[:10,:]) #计算各测试样本基于概率的预测
print(knn.score(test_x,test_y)) #对训练结果进行评估,计算出准确率
print(probability)
print(knn.predict(test_x[:10,:]))
0.9851851851851852
[[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0.8 0. 0. 0. 0. 0. 0.2]
[0. 0.2 0. 0. 0. 0. 0. 0. 0.8 0. ]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ]]
[6 7 1 0 3 8 7 6 7 1]
KNeighborsClassifier类的参数说明
n_neighbours
int 型参数,knn算法中指定以最近的几个最近邻样本具有投票权,默认参数为5
weights
str参数, 即每个拥有投票权的样本是按什么比重投票,'uniform’表示等比重投票,‘distance’表示按距离反比投票。默认’uniform’。
p
int型参数,p=2为欧氏距离,p=1为曼哈顿距离。默认为2
n_jobs
int型参数,指并行计算的线程数量,默认为1表示一个线程,为-1表示cpu的内核数。
KNeighborsClassifier类的方法说明
fit()
简单来说就是训练函数,接收参数为两个,训练集特征x和训练集标签y。该方法不是此类所特有的,简单来说就是所有的sklearn包中的机器学习算法都有该方法。
predict()
预测函数,输入参数为测试集特征x。
predict_prob()
也是预测函数,只不过输出的是基于概率的预测。
socre()
打分函数。接受参数有3个。
-X:接收输入的数组类型测试样本,一般是二维数组,每一行是一个样本,每一列是一个属性。
-y:X这些预测样本的真实标签,一维数组或者二维数组。
-sample_weight=None,是一个和X第一位一样长的各样本对准确率影响的权重,一般默认为None.
输出为一个float型数,表示准确率。